{"title":"公共建筑能耗预测的机器学习算法中的特征矩阵分析","authors":"Yong Ding , Lingxiao Fan , Xue Liu","doi":"10.1016/j.enbuild.2021.111208","DOIUrl":null,"url":null,"abstract":"<div><p>With the development of building information and energy consumption data<span>, machine learning methods<span> are increasingly being used for predicting and analyzing building energy consumption. In this study, based on the actual energy consumption data of 2370 public buildings in Chongqing, we used six machine learning algorithms and recursive feature elimination to analyze the importance of each feature in the dataset. First, it is necessary to establish optimal prediction models for analyzing the importance of features, and XGboost has demonstrated its superiority in terms of accuracy and efficiency. Regardless of the algorithm, the cumulative contribution rate of the top ten features exceeds 80%, and there is an obvious diminishing marginal utility when the number of features continues to increase. The learning algorithms with similar kernels have similarities in judging feature importance. Tree model-based algorithms can achieve a satisfactory performance with fewer features compared to linear kernel-based algorithms. Furthermore, the dataset plays a crucial role in model performance. To achieve professional supervised learning, two conditions need to be considered simultaneously in data collection: the importance of features in physical processes and whether the samples have adequate variance on these features. Thus, this study can provide a reference for database establishment and big data analysis of urban building energy consumption.</span></span></p></div>","PeriodicalId":11641,"journal":{"name":"Energy and Buildings","volume":"249 ","pages":"Article 111208"},"PeriodicalIF":6.6000,"publicationDate":"2021-10-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1016/j.enbuild.2021.111208","citationCount":"42","resultStr":"{\"title\":\"Analysis of feature matrix in machine learning algorithms to predict energy consumption of public buildings\",\"authors\":\"Yong Ding , Lingxiao Fan , Xue Liu\",\"doi\":\"10.1016/j.enbuild.2021.111208\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>With the development of building information and energy consumption data<span>, machine learning methods<span> are increasingly being used for predicting and analyzing building energy consumption. In this study, based on the actual energy consumption data of 2370 public buildings in Chongqing, we used six machine learning algorithms and recursive feature elimination to analyze the importance of each feature in the dataset. First, it is necessary to establish optimal prediction models for analyzing the importance of features, and XGboost has demonstrated its superiority in terms of accuracy and efficiency. Regardless of the algorithm, the cumulative contribution rate of the top ten features exceeds 80%, and there is an obvious diminishing marginal utility when the number of features continues to increase. The learning algorithms with similar kernels have similarities in judging feature importance. Tree model-based algorithms can achieve a satisfactory performance with fewer features compared to linear kernel-based algorithms. Furthermore, the dataset plays a crucial role in model performance. To achieve professional supervised learning, two conditions need to be considered simultaneously in data collection: the importance of features in physical processes and whether the samples have adequate variance on these features. Thus, this study can provide a reference for database establishment and big data analysis of urban building energy consumption.</span></span></p></div>\",\"PeriodicalId\":11641,\"journal\":{\"name\":\"Energy and Buildings\",\"volume\":\"249 \",\"pages\":\"Article 111208\"},\"PeriodicalIF\":6.6000,\"publicationDate\":\"2021-10-15\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.1016/j.enbuild.2021.111208\",\"citationCount\":\"42\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Energy and Buildings\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0378778821004928\",\"RegionNum\":2,\"RegionCategory\":\"工程技术\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"CONSTRUCTION & BUILDING TECHNOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Energy and Buildings","FirstCategoryId":"5","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0378778821004928","RegionNum":2,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CONSTRUCTION & BUILDING TECHNOLOGY","Score":null,"Total":0}
Analysis of feature matrix in machine learning algorithms to predict energy consumption of public buildings
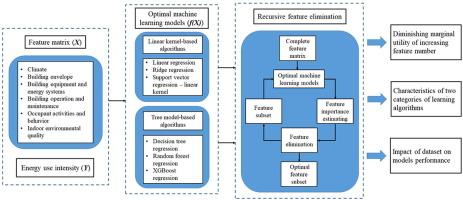
With the development of building information and energy consumption data, machine learning methods are increasingly being used for predicting and analyzing building energy consumption. In this study, based on the actual energy consumption data of 2370 public buildings in Chongqing, we used six machine learning algorithms and recursive feature elimination to analyze the importance of each feature in the dataset. First, it is necessary to establish optimal prediction models for analyzing the importance of features, and XGboost has demonstrated its superiority in terms of accuracy and efficiency. Regardless of the algorithm, the cumulative contribution rate of the top ten features exceeds 80%, and there is an obvious diminishing marginal utility when the number of features continues to increase. The learning algorithms with similar kernels have similarities in judging feature importance. Tree model-based algorithms can achieve a satisfactory performance with fewer features compared to linear kernel-based algorithms. Furthermore, the dataset plays a crucial role in model performance. To achieve professional supervised learning, two conditions need to be considered simultaneously in data collection: the importance of features in physical processes and whether the samples have adequate variance on these features. Thus, this study can provide a reference for database establishment and big data analysis of urban building energy consumption.
期刊介绍:
An international journal devoted to investigations of energy use and efficiency in buildings
Energy and Buildings is an international journal publishing articles with explicit links to energy use in buildings. The aim is to present new research results, and new proven practice aimed at reducing the energy needs of a building and improving indoor environment quality.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


