柑橘精油行业的机器学习:工艺优化、认证、风味和生物活性化合物开发的综合综述
IF 15.4
1区 农林科学
Q1 FOOD SCIENCE & TECHNOLOGY
引用次数: 0
摘要
柑橘精油(富含风味和生物活性化合物)是从柑橘果皮中提取的(构成占果实质量近40 - 50%的加工副产品),使柑橘得到综合利用,同时减轻环境污染。提取工艺参数、分析技术和化合物研究与开发的复杂性不断升级,产生了大规模、复杂的数据集,需要应用先进的计算分析(机器学习,ML)来进行有效的数据处理和分析。本文系统介绍了ML模型构建的一般工作流程(包括数据收集、预处理、模型选择和模型评估),重点介绍了ML模型的应用(包括工艺优化、产率预测、可追溯性、掺假鉴定、关键风味化合物表征和鉴定、风味和生物活性化合物的预测和合成)。随后的章节批判性地讨论了主要的挑战和限制,最后提出了未来的展望。sml已经渗透到精油行业的各个阶段,自2020年左右以来,其应用逐渐从传统的机器学习算法(依赖于手动特征提取)过渡到深度学习算法(采用神经网络进行自动特征学习)。这一技术进步显著提高了生产效率、质量控制、风味调节和生物活性化合物的开发。为了进一步加快机器学习在这一领域的实施,未来的工作应优先考虑:建立全面的公共数据库;特定领域数据预处理方法的发展;质量控制关键特征的识别;混合多任务建模的研究进展计算模拟与生物验证的必要性提高可解释性和商业适用性。本文章由计算机程序翻译,如有差异,请以英文原文为准。
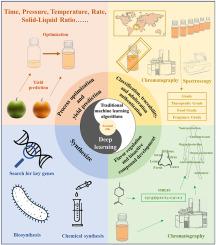
Machine learning in the citrus essential oil industry: A comprehensive review on process optimization, authentication, and flavor and bioactive compound development
Background
Citrus essential oils (rich in flavor and bioactive compounds) are extracted from citrus peels (constituting processing byproducts accounting for nearly 40–50 % of fruit mass), enabling comprehensive citrus utilization while mitigating environmental contamination. The escalating complexity of extraction process parameters, analytical techniques, and compound research and development generates large-scale, complex datasets, necessitating applications of advanced computational analytics (machine learning, ML) for efficient data processing and analysis.
Scope and approach
This review systematically presented the general workflows for construction of ML model (encompassing data collection, pre-processing, model selection, and model evaluation), with a focus on their applications (including process optimization, yield prediction, traceability, adulteration authentication, key flavor compound characterization and identification, and prediction and synthesis of flavor and bioactive compound). Subsequent sections critically addressed predominant challenges and limitations, culminating in proposed future outlooks.
Key findings and conclusions
ML has permeated all stages of the essential oil industry, with its applications progressively transitioning from traditional machine learning algorithms (relying on manual feature extraction) to deep learning algorithms (employing neural networks for automatic feature learning) since about 2020. This technological evolution has significantly enhanced production efficiency, quality control, flavor regulation, and bioactive compound development. To further accelerate ML implementation in this sector, future efforts should prioritize: establishment of comprehensive public databases; development of domain-specific data pre-processing methods; identification of key features for quality control; advancement of hybrid and multi-task modeling; necessity of computational simulation and biological verification; enhancement of interpretability and commercial applicability.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Trends in Food Science & Technology
工程技术-食品科技
CiteScore
32.50
自引率
2.60%
发文量
322
审稿时长
37 days
期刊介绍:
Trends in Food Science & Technology is a prestigious international journal that specializes in peer-reviewed articles covering the latest advancements in technology, food science, and human nutrition. It serves as a bridge between specialized primary journals and general trade magazines, providing readable and scientifically rigorous reviews and commentaries on current research developments and their potential applications in the food industry.
Unlike traditional journals, Trends in Food Science & Technology does not publish original research papers. Instead, it focuses on critical and comprehensive reviews to offer valuable insights for professionals in the field. By bringing together cutting-edge research and industry applications, this journal plays a vital role in disseminating knowledge and facilitating advancements in the food science and technology sector.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


