{"title":"偶尔使用两阶段深度强化学习的司机分配——一个电子杂货平台的案例研究","authors":"Nguyen Thi Tam Thanh, Nguyen Van Hop","doi":"10.1016/j.cstp.2025.101606","DOIUrl":null,"url":null,"abstract":"<div><div>This study addresses a stochastic crowd-shipping problem, considering multiple customer types and the uncertain availability of occasional drivers. The objective is to minimize the total delivery cost through efficient customer allocation and routing for dedicated and occasional drivers. A novel two-phase Deep Reinforcement Learning approach is introduced to efficiently handle large-scale instances. In the first stage, a Single-Layer Feed-Forward Neural Network is implemented to train and validate the estimated reward function of random sequences using an on-policy method. The customer types are classified by taking appropriate actions using a Mixed-Integer Programming solution. Then, a modified Proximal Policy Optimization algorithm updates policies over multiple epochs during training. After allocation, optimal routes for occasional drivers are determined by a Capacitated Vehicle Routing model. A case study of an online e-grocery platform illustrates the efficiency of the proposed system. Experimental results indicate that the proposed approach outperforms the previous approach by approximately 17%.</div></div>","PeriodicalId":46989,"journal":{"name":"Case Studies on Transport Policy","volume":"22 ","pages":"Article 101606"},"PeriodicalIF":3.3000,"publicationDate":"2025-09-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Occasional drivers’ allocation using two-stage deep reinforcement learning – a case study of an e-grocery platform\",\"authors\":\"Nguyen Thi Tam Thanh, Nguyen Van Hop\",\"doi\":\"10.1016/j.cstp.2025.101606\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><div>This study addresses a stochastic crowd-shipping problem, considering multiple customer types and the uncertain availability of occasional drivers. The objective is to minimize the total delivery cost through efficient customer allocation and routing for dedicated and occasional drivers. A novel two-phase Deep Reinforcement Learning approach is introduced to efficiently handle large-scale instances. In the first stage, a Single-Layer Feed-Forward Neural Network is implemented to train and validate the estimated reward function of random sequences using an on-policy method. The customer types are classified by taking appropriate actions using a Mixed-Integer Programming solution. Then, a modified Proximal Policy Optimization algorithm updates policies over multiple epochs during training. After allocation, optimal routes for occasional drivers are determined by a Capacitated Vehicle Routing model. A case study of an online e-grocery platform illustrates the efficiency of the proposed system. Experimental results indicate that the proposed approach outperforms the previous approach by approximately 17%.</div></div>\",\"PeriodicalId\":46989,\"journal\":{\"name\":\"Case Studies on Transport Policy\",\"volume\":\"22 \",\"pages\":\"Article 101606\"},\"PeriodicalIF\":3.3000,\"publicationDate\":\"2025-09-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Case Studies on Transport Policy\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2213624X25002433\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"TRANSPORTATION\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Case Studies on Transport Policy","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2213624X25002433","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"TRANSPORTATION","Score":null,"Total":0}
Occasional drivers’ allocation using two-stage deep reinforcement learning – a case study of an e-grocery platform
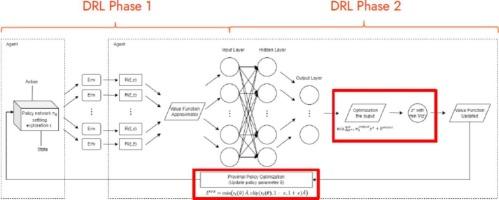
This study addresses a stochastic crowd-shipping problem, considering multiple customer types and the uncertain availability of occasional drivers. The objective is to minimize the total delivery cost through efficient customer allocation and routing for dedicated and occasional drivers. A novel two-phase Deep Reinforcement Learning approach is introduced to efficiently handle large-scale instances. In the first stage, a Single-Layer Feed-Forward Neural Network is implemented to train and validate the estimated reward function of random sequences using an on-policy method. The customer types are classified by taking appropriate actions using a Mixed-Integer Programming solution. Then, a modified Proximal Policy Optimization algorithm updates policies over multiple epochs during training. After allocation, optimal routes for occasional drivers are determined by a Capacitated Vehicle Routing model. A case study of an online e-grocery platform illustrates the efficiency of the proposed system. Experimental results indicate that the proposed approach outperforms the previous approach by approximately 17%.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


