{"title":"近十年来肿瘤学NLP方法的调查,重点是癌症登记应用。","authors":"Isaac Hands, Ramakanth Kavuluru","doi":"10.1007/s10462-025-11316-5","DOIUrl":null,"url":null,"abstract":"<div><p>Clinical texts from pathology and radiology reports provide critical information for cancer diagnosis and staging. This study surveys the application of natural language processing (NLP) in cancer registry operations from 2014 to 2024. A total of 156 articles from Scopus and PubMed were reviewed and were categorized by NLP methods, document types, cancer sites, and research aims. NLP approaches were evenly distributed across rule-based (n=70), machine learning (n=66), and traditional deep learning (n=70), with transformer models (n=29) gaining prominence since 2019. Encoder-only models like BERT and its clinical adaptations (e.g., ClinicalBERT, RadBERT) show significant promise, though methods for increasing context length are needed. Decoder-only models (e.g., GPT-3, GPT-4) are less explored due to privacy concerns and computational demands. Notably, pediatric cancers, melanomas, and lymphomas are underrepresented, as are research areas such as disease progression, clinical trial matching, and patient communication. Multi-modal models, important for precision oncology and cancer screening, are also scarce. Our study highlights the potential of NLP to enhance data abstraction efficiency and accuracy in cancer registries, making greater use of cancer registry data for patient benefit. However, further research is needed to fully leverage transformer-based models, particularly for underrepresented cancer types and outcomes. Addressing these gaps can improve the timeliness, completeness, and accuracy of structured data collection from clinical text, ultimately enhancing cancer research and patient outcomes.</p></div>","PeriodicalId":8449,"journal":{"name":"Artificial Intelligence Review","volume":"58 10","pages":""},"PeriodicalIF":13.9000,"publicationDate":"2025-07-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12267331/pdf/","citationCount":"0","resultStr":"{\"title\":\"A survey of NLP methods for oncology in the past decade with a focus on cancer registry applications\",\"authors\":\"Isaac Hands, Ramakanth Kavuluru\",\"doi\":\"10.1007/s10462-025-11316-5\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Clinical texts from pathology and radiology reports provide critical information for cancer diagnosis and staging. This study surveys the application of natural language processing (NLP) in cancer registry operations from 2014 to 2024. A total of 156 articles from Scopus and PubMed were reviewed and were categorized by NLP methods, document types, cancer sites, and research aims. NLP approaches were evenly distributed across rule-based (n=70), machine learning (n=66), and traditional deep learning (n=70), with transformer models (n=29) gaining prominence since 2019. Encoder-only models like BERT and its clinical adaptations (e.g., ClinicalBERT, RadBERT) show significant promise, though methods for increasing context length are needed. Decoder-only models (e.g., GPT-3, GPT-4) are less explored due to privacy concerns and computational demands. Notably, pediatric cancers, melanomas, and lymphomas are underrepresented, as are research areas such as disease progression, clinical trial matching, and patient communication. Multi-modal models, important for precision oncology and cancer screening, are also scarce. Our study highlights the potential of NLP to enhance data abstraction efficiency and accuracy in cancer registries, making greater use of cancer registry data for patient benefit. However, further research is needed to fully leverage transformer-based models, particularly for underrepresented cancer types and outcomes. Addressing these gaps can improve the timeliness, completeness, and accuracy of structured data collection from clinical text, ultimately enhancing cancer research and patient outcomes.</p></div>\",\"PeriodicalId\":8449,\"journal\":{\"name\":\"Artificial Intelligence Review\",\"volume\":\"58 10\",\"pages\":\"\"},\"PeriodicalIF\":13.9000,\"publicationDate\":\"2025-07-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12267331/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Artificial Intelligence Review\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s10462-025-11316-5\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Artificial Intelligence Review","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s10462-025-11316-5","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
A survey of NLP methods for oncology in the past decade with a focus on cancer registry applications
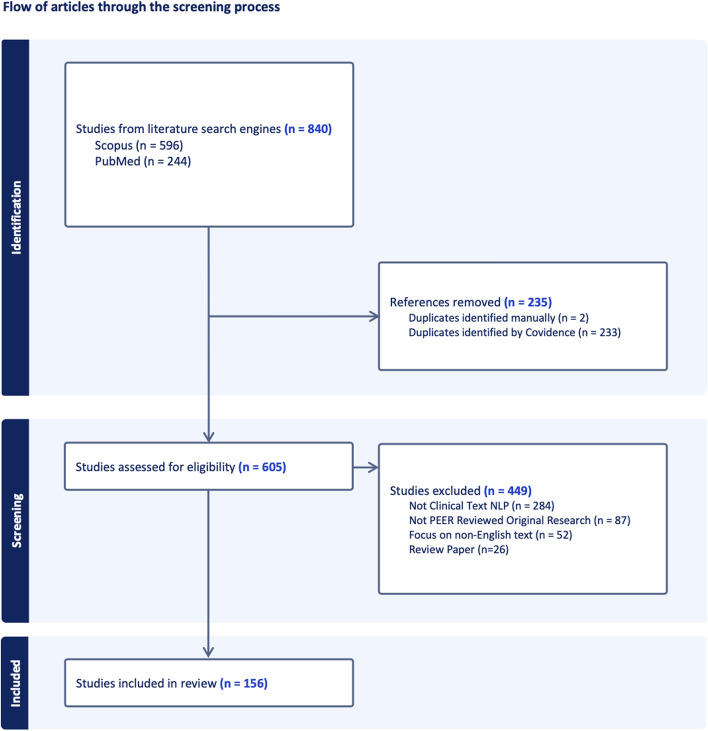
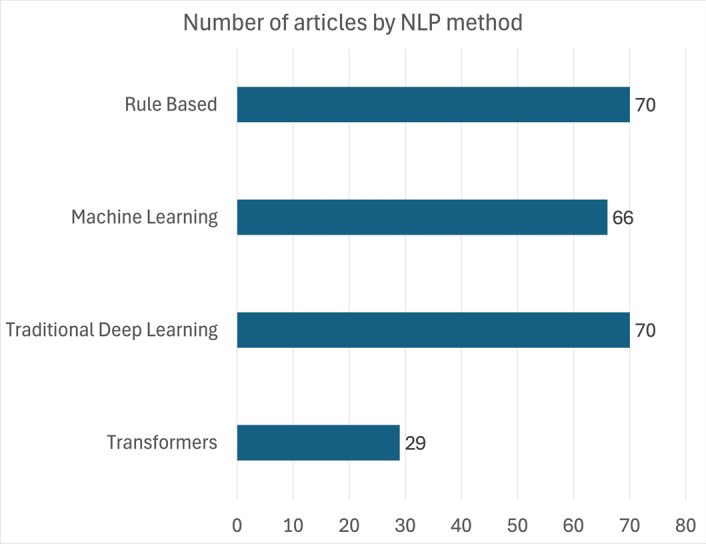
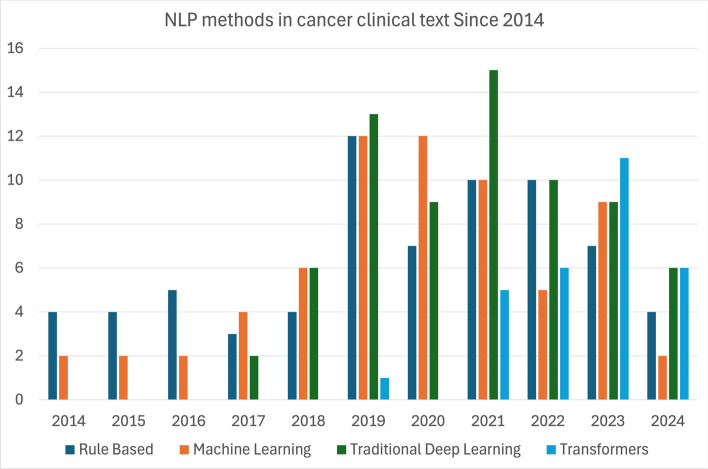
Clinical texts from pathology and radiology reports provide critical information for cancer diagnosis and staging. This study surveys the application of natural language processing (NLP) in cancer registry operations from 2014 to 2024. A total of 156 articles from Scopus and PubMed were reviewed and were categorized by NLP methods, document types, cancer sites, and research aims. NLP approaches were evenly distributed across rule-based (n=70), machine learning (n=66), and traditional deep learning (n=70), with transformer models (n=29) gaining prominence since 2019. Encoder-only models like BERT and its clinical adaptations (e.g., ClinicalBERT, RadBERT) show significant promise, though methods for increasing context length are needed. Decoder-only models (e.g., GPT-3, GPT-4) are less explored due to privacy concerns and computational demands. Notably, pediatric cancers, melanomas, and lymphomas are underrepresented, as are research areas such as disease progression, clinical trial matching, and patient communication. Multi-modal models, important for precision oncology and cancer screening, are also scarce. Our study highlights the potential of NLP to enhance data abstraction efficiency and accuracy in cancer registries, making greater use of cancer registry data for patient benefit. However, further research is needed to fully leverage transformer-based models, particularly for underrepresented cancer types and outcomes. Addressing these gaps can improve the timeliness, completeness, and accuracy of structured data collection from clinical text, ultimately enhancing cancer research and patient outcomes.
期刊介绍:
Artificial Intelligence Review, a fully open access journal, publishes cutting-edge research in artificial intelligence and cognitive science. It features critical evaluations of applications, techniques, and algorithms, providing a platform for both researchers and application developers. The journal includes refereed survey and tutorial articles, along with reviews and commentary on significant developments in the field.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


