Xuan Dung James Nguyen, Y A Liu, Christopher C McDowell, Luke Dooley
{"title":"使用机器学习的发酵过程中污染检测和减少的方法学。","authors":"Xuan Dung James Nguyen, Y A Liu, Christopher C McDowell, Luke Dooley","doi":"10.1007/s00449-025-03194-6","DOIUrl":null,"url":null,"abstract":"<p><p>This paper demonstrates an accurate and efficient methodology for fermentation contamination detection and reduction using two machine learning (ML) methods, including one-class support vector machine and autoencoders. We also optimize as many hyperparameters as possible prior to the training of the ML models to improve the model accuracy and efficiency, and choose a Python platform called Optuna, to enable the parallel execution of hyperparameter optimization (HPO). We recommend using Bayesian optimization with hyperband algorithm to carry out HPO. Results show that we can predict contaminated fermentation batches with recall up to 1.0 without sacrificing the precision and specificity of non-contaminated batches, which read up to 0.96 and 0.99, respectively. One-class support vector machine outperforms autoencoders in terms of precision and specificity even though they both achieve an outstanding recall of 1.0. These models demonstrate high accuracy in detecting contamination without requiring labeled contaminated data and are suitable for integration into real-time fermentation monitoring systems with minimal latency and retraining needs. In addition, we benchmark our ML methods against a traditional threshold-based contamination detection approach (mean <math><mo>±</mo></math> 3 <math><mi>σ</mi></math> rule) to quantify the added value of using data-driven models. Finally, we identify important independent variables contributing to the contaminated batches and give recommendations on how to regulate them to reduce the likelihood of contamination.</p>","PeriodicalId":9024,"journal":{"name":"Bioprocess and Biosystems Engineering","volume":" ","pages":"1547-1563"},"PeriodicalIF":3.6000,"publicationDate":"2025-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12367959/pdf/","citationCount":"0","resultStr":"{\"title\":\"Methodology for contamination detection and reduction in fermentation processes using machine learning.\",\"authors\":\"Xuan Dung James Nguyen, Y A Liu, Christopher C McDowell, Luke Dooley\",\"doi\":\"10.1007/s00449-025-03194-6\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>This paper demonstrates an accurate and efficient methodology for fermentation contamination detection and reduction using two machine learning (ML) methods, including one-class support vector machine and autoencoders. We also optimize as many hyperparameters as possible prior to the training of the ML models to improve the model accuracy and efficiency, and choose a Python platform called Optuna, to enable the parallel execution of hyperparameter optimization (HPO). We recommend using Bayesian optimization with hyperband algorithm to carry out HPO. Results show that we can predict contaminated fermentation batches with recall up to 1.0 without sacrificing the precision and specificity of non-contaminated batches, which read up to 0.96 and 0.99, respectively. One-class support vector machine outperforms autoencoders in terms of precision and specificity even though they both achieve an outstanding recall of 1.0. These models demonstrate high accuracy in detecting contamination without requiring labeled contaminated data and are suitable for integration into real-time fermentation monitoring systems with minimal latency and retraining needs. In addition, we benchmark our ML methods against a traditional threshold-based contamination detection approach (mean <math><mo>±</mo></math> 3 <math><mi>σ</mi></math> rule) to quantify the added value of using data-driven models. Finally, we identify important independent variables contributing to the contaminated batches and give recommendations on how to regulate them to reduce the likelihood of contamination.</p>\",\"PeriodicalId\":9024,\"journal\":{\"name\":\"Bioprocess and Biosystems Engineering\",\"volume\":\" \",\"pages\":\"1547-1563\"},\"PeriodicalIF\":3.6000,\"publicationDate\":\"2025-09-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12367959/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Bioprocess and Biosystems Engineering\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://doi.org/10.1007/s00449-025-03194-6\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/6/26 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"BIOTECHNOLOGY & APPLIED MICROBIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioprocess and Biosystems Engineering","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1007/s00449-025-03194-6","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/6/26 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"BIOTECHNOLOGY & APPLIED MICROBIOLOGY","Score":null,"Total":0}
Methodology for contamination detection and reduction in fermentation processes using machine learning.
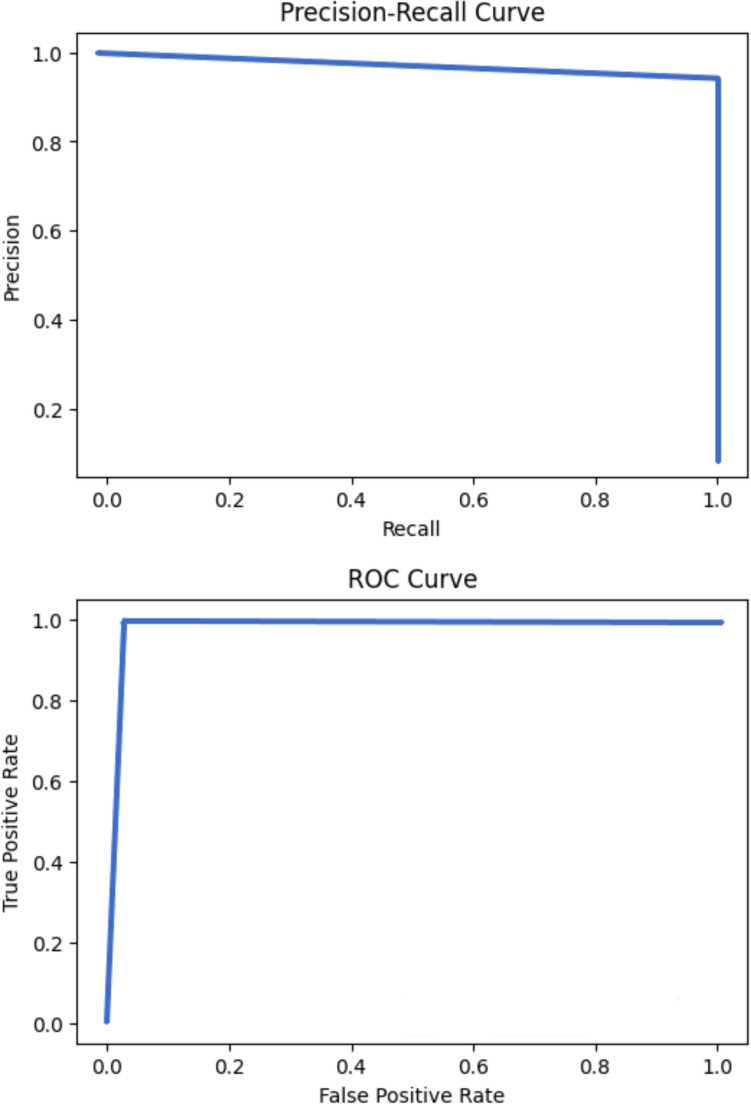
This paper demonstrates an accurate and efficient methodology for fermentation contamination detection and reduction using two machine learning (ML) methods, including one-class support vector machine and autoencoders. We also optimize as many hyperparameters as possible prior to the training of the ML models to improve the model accuracy and efficiency, and choose a Python platform called Optuna, to enable the parallel execution of hyperparameter optimization (HPO). We recommend using Bayesian optimization with hyperband algorithm to carry out HPO. Results show that we can predict contaminated fermentation batches with recall up to 1.0 without sacrificing the precision and specificity of non-contaminated batches, which read up to 0.96 and 0.99, respectively. One-class support vector machine outperforms autoencoders in terms of precision and specificity even though they both achieve an outstanding recall of 1.0. These models demonstrate high accuracy in detecting contamination without requiring labeled contaminated data and are suitable for integration into real-time fermentation monitoring systems with minimal latency and retraining needs. In addition, we benchmark our ML methods against a traditional threshold-based contamination detection approach (mean 3 rule) to quantify the added value of using data-driven models. Finally, we identify important independent variables contributing to the contaminated batches and give recommendations on how to regulate them to reduce the likelihood of contamination.
期刊介绍:
Bioprocess and Biosystems Engineering provides an international peer-reviewed forum to facilitate the discussion between engineering and biological science to find efficient solutions in the development and improvement of bioprocesses. The aim of the journal is to focus more attention on the multidisciplinary approaches for integrative bioprocess design. Of special interest are the rational manipulation of biosystems through metabolic engineering techniques to provide new biocatalysts as well as the model based design of bioprocesses (up-stream processing, bioreactor operation and downstream processing) that will lead to new and sustainable production processes.
Contributions are targeted at new approaches for rational and evolutive design of cellular systems by taking into account the environment and constraints of technical production processes, integration of recombinant technology and process design, as well as new hybrid intersections such as bioinformatics and process systems engineering. Manuscripts concerning the design, simulation, experimental validation, control, and economic as well as ecological evaluation of novel processes using biosystems or parts thereof (e.g., enzymes, microorganisms, mammalian cells, plant cells, or tissue), their related products, or technical devices are also encouraged.
The Editors will consider papers for publication based on novelty, their impact on biotechnological production and their contribution to the advancement of bioprocess and biosystems engineering science. Submission of papers dealing with routine aspects of bioprocess engineering (e.g., routine application of established methodologies, and description of established equipment) are discouraged.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


