Philip M Newton, Christopher J Summers, Uzman Zaheer, Maira Xiromeriti, Jemima R Stokes, Jaskaran Singh Bhangu, Elis G Roome, Alanna Roberts-Phillips, Darius Mazaheri-Asadi, Cameron D Jones, Stuart Hughes, Dominic Gilbert, Ewan Jones, Keioni Essex, Emily C Ellis, Ross Davey, Adrienne A Cox, Jessica A Bassett
{"title":"chatgpt - 40真的能通过医学考试吗?用新颖疑问句进行语用分析。","authors":"Philip M Newton, Christopher J Summers, Uzman Zaheer, Maira Xiromeriti, Jemima R Stokes, Jaskaran Singh Bhangu, Elis G Roome, Alanna Roberts-Phillips, Darius Mazaheri-Asadi, Cameron D Jones, Stuart Hughes, Dominic Gilbert, Ewan Jones, Keioni Essex, Emily C Ellis, Ross Davey, Adrienne A Cox, Jessica A Bassett","doi":"10.1007/s40670-025-02293-z","DOIUrl":null,"url":null,"abstract":"<p><p>ChatGPT apparently shows excellent performance on high-level professional exams such as those involved in medical assessment and licensing. This has raised concerns that ChatGPT could be used for academic misconduct, especially in unproctored online exams. However, ChatGPT has previously shown weaker performance on questions with pictures, and there have been concerns that ChatGPT's performance may be artificially inflated by the public nature of the sample questions tested, meaning they likely formed part of the training materials for ChatGPT. This led to suggestions that cheating could be mitigated by using novel questions for every sitting of an exam and making extensive use of picture-based questions. These approaches remain untested. Here, we tested the performance of ChatGPT-4o on existing medical licensing exams in the UK and USA, and on novel questions based on those exams. ChatGPT-4o scored 94% on the United Kingdom Medical Licensing Exam Applied Knowledge Test and 89.9% on the United States Medical Licensing Exam Step 1. Performance was not diminished when the questions were rewritten into novel versions, or on completely novel questions which were not based on any existing questions. ChatGPT did show reduced performance on questions containing images when the answer options were added to an image as text labels. These data demonstrate that the performance of ChatGPT continues to improve and that secure testing environments are required for the valid assessment of both foundational and higher order learning.</p><p><strong>Supplementary information: </strong>The online version contains supplementary material available at 10.1007/s40670-025-02293-z.</p>","PeriodicalId":37113,"journal":{"name":"Medical Science Educator","volume":"35 2","pages":"721-729"},"PeriodicalIF":1.8000,"publicationDate":"2025-02-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12058600/pdf/","citationCount":"0","resultStr":"{\"title\":\"Can ChatGPT-4o Really Pass Medical Science Exams? A Pragmatic Analysis Using Novel Questions.\",\"authors\":\"Philip M Newton, Christopher J Summers, Uzman Zaheer, Maira Xiromeriti, Jemima R Stokes, Jaskaran Singh Bhangu, Elis G Roome, Alanna Roberts-Phillips, Darius Mazaheri-Asadi, Cameron D Jones, Stuart Hughes, Dominic Gilbert, Ewan Jones, Keioni Essex, Emily C Ellis, Ross Davey, Adrienne A Cox, Jessica A Bassett\",\"doi\":\"10.1007/s40670-025-02293-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>ChatGPT apparently shows excellent performance on high-level professional exams such as those involved in medical assessment and licensing. This has raised concerns that ChatGPT could be used for academic misconduct, especially in unproctored online exams. However, ChatGPT has previously shown weaker performance on questions with pictures, and there have been concerns that ChatGPT's performance may be artificially inflated by the public nature of the sample questions tested, meaning they likely formed part of the training materials for ChatGPT. This led to suggestions that cheating could be mitigated by using novel questions for every sitting of an exam and making extensive use of picture-based questions. These approaches remain untested. Here, we tested the performance of ChatGPT-4o on existing medical licensing exams in the UK and USA, and on novel questions based on those exams. ChatGPT-4o scored 94% on the United Kingdom Medical Licensing Exam Applied Knowledge Test and 89.9% on the United States Medical Licensing Exam Step 1. Performance was not diminished when the questions were rewritten into novel versions, or on completely novel questions which were not based on any existing questions. ChatGPT did show reduced performance on questions containing images when the answer options were added to an image as text labels. These data demonstrate that the performance of ChatGPT continues to improve and that secure testing environments are required for the valid assessment of both foundational and higher order learning.</p><p><strong>Supplementary information: </strong>The online version contains supplementary material available at 10.1007/s40670-025-02293-z.</p>\",\"PeriodicalId\":37113,\"journal\":{\"name\":\"Medical Science Educator\",\"volume\":\"35 2\",\"pages\":\"721-729\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2025-02-04\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12058600/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Medical Science Educator\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s40670-025-02293-z\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/4/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"EDUCATION, SCIENTIFIC DISCIPLINES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Medical Science Educator","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s40670-025-02293-z","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/4/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"EDUCATION, SCIENTIFIC DISCIPLINES","Score":null,"Total":0}
Can ChatGPT-4o Really Pass Medical Science Exams? A Pragmatic Analysis Using Novel Questions.
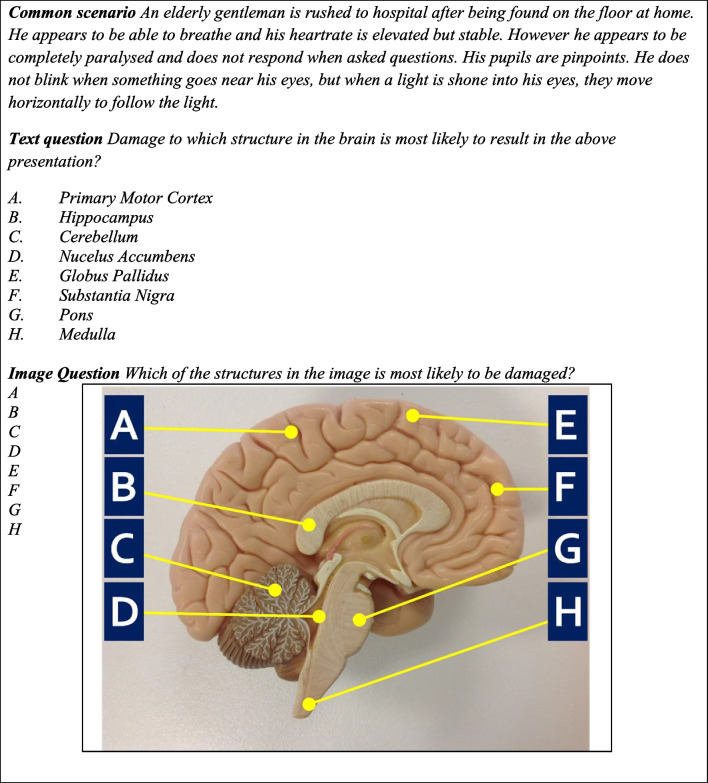
ChatGPT apparently shows excellent performance on high-level professional exams such as those involved in medical assessment and licensing. This has raised concerns that ChatGPT could be used for academic misconduct, especially in unproctored online exams. However, ChatGPT has previously shown weaker performance on questions with pictures, and there have been concerns that ChatGPT's performance may be artificially inflated by the public nature of the sample questions tested, meaning they likely formed part of the training materials for ChatGPT. This led to suggestions that cheating could be mitigated by using novel questions for every sitting of an exam and making extensive use of picture-based questions. These approaches remain untested. Here, we tested the performance of ChatGPT-4o on existing medical licensing exams in the UK and USA, and on novel questions based on those exams. ChatGPT-4o scored 94% on the United Kingdom Medical Licensing Exam Applied Knowledge Test and 89.9% on the United States Medical Licensing Exam Step 1. Performance was not diminished when the questions were rewritten into novel versions, or on completely novel questions which were not based on any existing questions. ChatGPT did show reduced performance on questions containing images when the answer options were added to an image as text labels. These data demonstrate that the performance of ChatGPT continues to improve and that secure testing environments are required for the valid assessment of both foundational and higher order learning.
Supplementary information: The online version contains supplementary material available at 10.1007/s40670-025-02293-z.
期刊介绍:
Medical Science Educator is the successor of the journal JIAMSE. It is the peer-reviewed publication of the International Association of Medical Science Educators (IAMSE). The Journal offers all who teach in healthcare the most current information to succeed in their task by publishing scholarly activities, opinions, and resources in medical science education. Published articles focus on teaching the sciences fundamental to modern medicine and health, and include basic science education, clinical teaching, and the use of modern education technologies. The Journal provides the readership a better understanding of teaching and learning techniques in order to advance medical science education.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


