Alireza Khorramfard, Jamshid Pirgazi, Ali Ghanbari Sorkhi
{"title":"基于改进的不平衡数据中支持向量数据描述的药物蛋白相互作用预测。","authors":"Alireza Khorramfard, Jamshid Pirgazi, Ali Ghanbari Sorkhi","doi":"10.34172/bi.30468","DOIUrl":null,"url":null,"abstract":"<p><p></p><p><strong>Introduction: </strong>Predicting drug-protein interactions is critical in drug discovery, but traditional laboratory methods are expensive and time-consuming. Computational approaches, especially those leveraging machine learning, are increasingly popular. This paper introduces VASVDD, a multi-step method to predict drug-protein interactions. First, it extracts features from amino acid sequences in proteins and drug structures. To address the challenge of unbalanced datasets, a Support Vector Data Description (SVDD) approach is employed, outperforming standard techniques like SMOTE and ENN in balancing data. Subsequently, dimensionality reduction using a Variational Autoencoder (VAE) reduces features from 1074 to 32, improving computational efficiency and predictive performance.</p><p><strong>Methods: </strong>The proposed method was evaluated on four datasets related to enzymes, G-protein-coupled receptors, ion channels, and nuclear receptors. Without preprocessing, the Gradient Boosting Classifier showed bias towards the majority class. However, balancing and dimensionality reduction significantly improved accuracy, sensitivity, specificity, and F1 scores. VASVDD demonstrated superior performance compared to other dimensionality reduction methods, such as kernel principal component analysis (kernel PCA) and Principal Component Analysis (PCA), and was validated across multiple classifiers, achieving higher AUROC values than existing techniques.</p><p><strong>Results: </strong>The results highlight VASVDD's effectiveness and generalizability in predicting drug-target interactions. The method outperforms state-of-the-art techniques in terms of accuracy, robustness, and efficiency, making it a promising tool in bioinformatics for drug discovery.</p><p><strong>Conclusion: </strong>The datasets analyzed during the current study are not publicly available but are available from the corresponding author upon reasonable request and source code are available on GitHub: https://github.com/alirezakhorramfard/vasvdd.</p>","PeriodicalId":48614,"journal":{"name":"Bioimpacts","volume":"15 ","pages":"30468"},"PeriodicalIF":2.2000,"publicationDate":"2024-12-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12008248/pdf/","citationCount":"0","resultStr":"{\"title\":\"Predicting drug protein interactions based on improved support vector data description in unbalanced data.\",\"authors\":\"Alireza Khorramfard, Jamshid Pirgazi, Ali Ghanbari Sorkhi\",\"doi\":\"10.34172/bi.30468\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p></p><p><strong>Introduction: </strong>Predicting drug-protein interactions is critical in drug discovery, but traditional laboratory methods are expensive and time-consuming. Computational approaches, especially those leveraging machine learning, are increasingly popular. This paper introduces VASVDD, a multi-step method to predict drug-protein interactions. First, it extracts features from amino acid sequences in proteins and drug structures. To address the challenge of unbalanced datasets, a Support Vector Data Description (SVDD) approach is employed, outperforming standard techniques like SMOTE and ENN in balancing data. Subsequently, dimensionality reduction using a Variational Autoencoder (VAE) reduces features from 1074 to 32, improving computational efficiency and predictive performance.</p><p><strong>Methods: </strong>The proposed method was evaluated on four datasets related to enzymes, G-protein-coupled receptors, ion channels, and nuclear receptors. Without preprocessing, the Gradient Boosting Classifier showed bias towards the majority class. However, balancing and dimensionality reduction significantly improved accuracy, sensitivity, specificity, and F1 scores. VASVDD demonstrated superior performance compared to other dimensionality reduction methods, such as kernel principal component analysis (kernel PCA) and Principal Component Analysis (PCA), and was validated across multiple classifiers, achieving higher AUROC values than existing techniques.</p><p><strong>Results: </strong>The results highlight VASVDD's effectiveness and generalizability in predicting drug-target interactions. The method outperforms state-of-the-art techniques in terms of accuracy, robustness, and efficiency, making it a promising tool in bioinformatics for drug discovery.</p><p><strong>Conclusion: </strong>The datasets analyzed during the current study are not publicly available but are available from the corresponding author upon reasonable request and source code are available on GitHub: https://github.com/alirezakhorramfard/vasvdd.</p>\",\"PeriodicalId\":48614,\"journal\":{\"name\":\"Bioimpacts\",\"volume\":\"15 \",\"pages\":\"30468\"},\"PeriodicalIF\":2.2000,\"publicationDate\":\"2024-12-30\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12008248/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Bioimpacts\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://doi.org/10.34172/bi.30468\",\"RegionNum\":4,\"RegionCategory\":\"工程技术\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q3\",\"JCRName\":\"PHARMACOLOGY & PHARMACY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioimpacts","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.34172/bi.30468","RegionNum":4,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"PHARMACOLOGY & PHARMACY","Score":null,"Total":0}
引用次数: 0
摘要
预测药物-蛋白质相互作用在药物发现中至关重要,但传统的实验室方法既昂贵又耗时。计算方法,尤其是那些利用机器学习的方法,越来越受欢迎。本文介绍了一种多步骤预测药物-蛋白质相互作用的方法VASVDD。首先,它从蛋白质和药物结构的氨基酸序列中提取特征。为了解决不平衡数据集的挑战,采用了支持向量数据描述(SVDD)方法,在平衡数据方面优于SMOTE和ENN等标准技术。随后,使用变分自编码器(VAE)进行降维,将特征从1074个减少到32个,提高了计算效率和预测性能。方法:采用酶、g蛋白偶联受体、离子通道和核受体等4个数据集对该方法进行评价。在未经预处理的情况下,梯度增强分类器表现出对多数类的偏向。然而,平衡和降维显著提高了准确性、敏感性、特异性和F1评分。与其他降维方法(如核主成分分析(kernel principal component analysis, PCA)和主成分分析(principal component analysis, PCA))相比,VASVDD表现出了优越的性能,并在多个分类器上进行了验证,获得了比现有技术更高的AUROC值。结果:VASVDD在预测药物-靶标相互作用方面具有一定的有效性和普遍性。该方法在准确性,稳健性和效率方面优于最先进的技术,使其成为生物信息学中药物发现的有前途的工具。结论:目前研究中分析的数据集不是公开的,但应通讯作者的合理要求,可以从GitHub上获得源代码:https://github.com/alirezakhorramfard/vasvdd。
Predicting drug protein interactions based on improved support vector data description in unbalanced data.
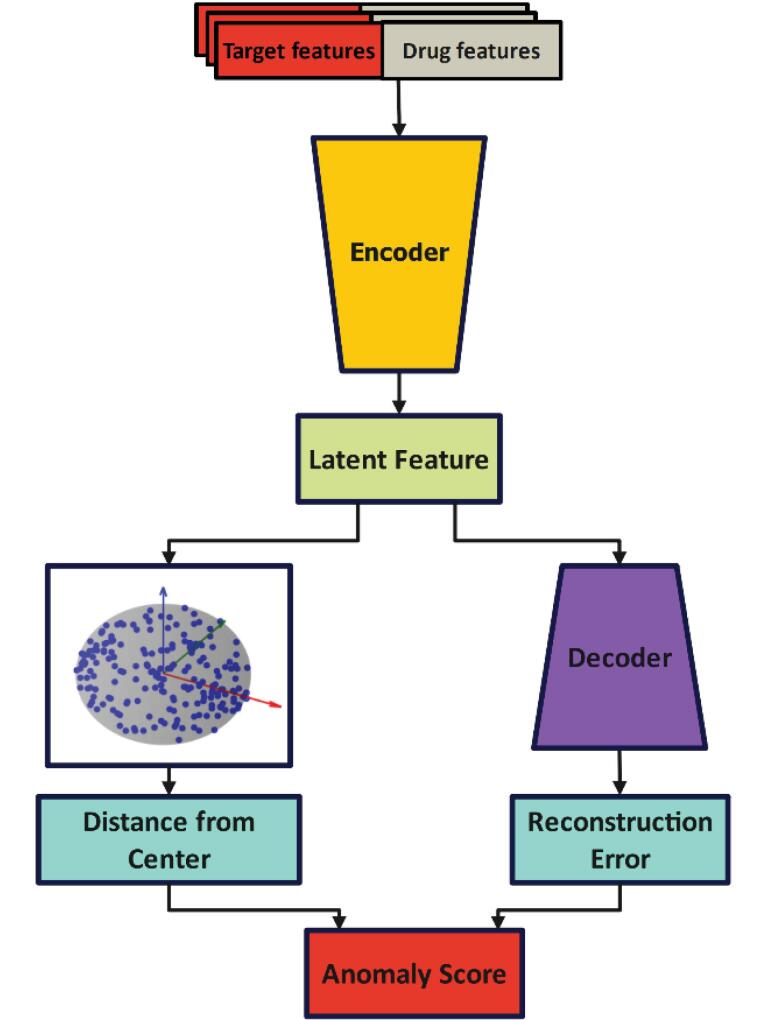
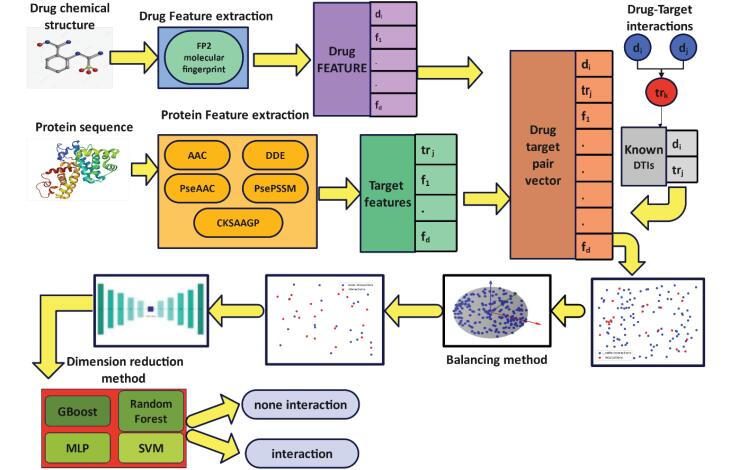
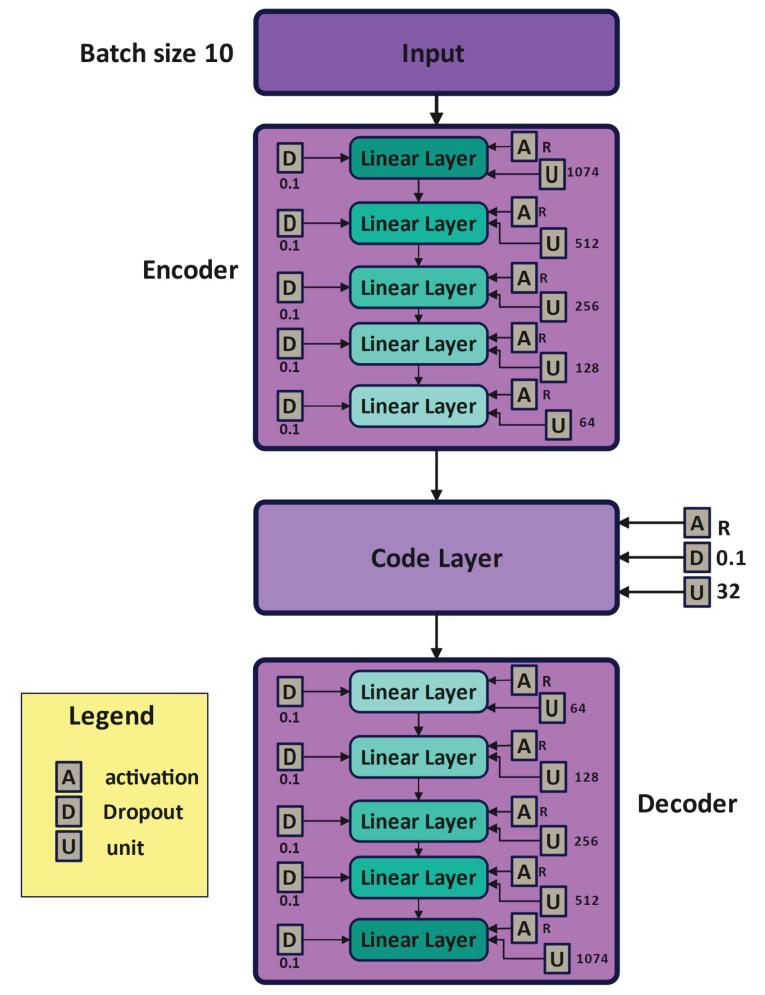
Introduction: Predicting drug-protein interactions is critical in drug discovery, but traditional laboratory methods are expensive and time-consuming. Computational approaches, especially those leveraging machine learning, are increasingly popular. This paper introduces VASVDD, a multi-step method to predict drug-protein interactions. First, it extracts features from amino acid sequences in proteins and drug structures. To address the challenge of unbalanced datasets, a Support Vector Data Description (SVDD) approach is employed, outperforming standard techniques like SMOTE and ENN in balancing data. Subsequently, dimensionality reduction using a Variational Autoencoder (VAE) reduces features from 1074 to 32, improving computational efficiency and predictive performance.
Methods: The proposed method was evaluated on four datasets related to enzymes, G-protein-coupled receptors, ion channels, and nuclear receptors. Without preprocessing, the Gradient Boosting Classifier showed bias towards the majority class. However, balancing and dimensionality reduction significantly improved accuracy, sensitivity, specificity, and F1 scores. VASVDD demonstrated superior performance compared to other dimensionality reduction methods, such as kernel principal component analysis (kernel PCA) and Principal Component Analysis (PCA), and was validated across multiple classifiers, achieving higher AUROC values than existing techniques.
Results: The results highlight VASVDD's effectiveness and generalizability in predicting drug-target interactions. The method outperforms state-of-the-art techniques in terms of accuracy, robustness, and efficiency, making it a promising tool in bioinformatics for drug discovery.
Conclusion: The datasets analyzed during the current study are not publicly available but are available from the corresponding author upon reasonable request and source code are available on GitHub: https://github.com/alirezakhorramfard/vasvdd.
BioimpactsPharmacology, Toxicology and Pharmaceutics-Pharmaceutical Science
CiteScore
4.80
自引率
7.70%
发文量
36
审稿时长
5 weeks
期刊介绍:
BioImpacts (BI) is a peer-reviewed multidisciplinary international journal, covering original research articles, reviews, commentaries, hypotheses, methodologies, and visions/reflections dealing with all aspects of biological and biomedical researches at molecular, cellular, functional and translational dimensions.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


