Vadym Gryshchuk, Devesh Singh, Stefan Teipel, Martin Dyrba
{"title":"神经退行性疾病分类的对比自监督学习。","authors":"Vadym Gryshchuk, Devesh Singh, Stefan Teipel, Martin Dyrba","doi":"10.3389/fninf.2025.1527582","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Neurodegenerative diseases such as Alzheimer's disease (AD) or frontotemporal lobar degeneration (FTLD) involve specific loss of brain volume, detectable <i>in vivo</i> using T1-weighted MRI scans. Supervised machine learning approaches classifying neurodegenerative diseases require diagnostic-labels for each sample. However, it can be difficult to obtain expert labels for a large amount of data. Self-supervised learning (SSL) offers an alternative for training machine learning models without data-labels.</p><p><strong>Methods: </strong>We investigated if the SSL models can be applied to distinguish between different neurodegenerative disorders in an interpretable manner. Our method comprises a feature extractor and a downstream classification head. A deep convolutional neural network, trained with a contrastive loss, serves as the feature extractor that learns latent representations. The classification head is a single-layer perceptron that is trained to perform diagnostic group separation. We used <i>N</i> = 2,694 T1-weighted MRI scans from four data cohorts: two ADNI datasets, AIBL and FTLDNI, including cognitively normal controls (CN), cases with prodromal and clinical AD, as well as FTLD cases differentiated into its phenotypes.</p><p><strong>Results: </strong>Our results showed that the feature extractor trained in a self-supervised way provides generalizable and robust representations for the downstream classification. For AD vs. CN, our model achieves 82% balanced accuracy on the test subset and 80% on an independent holdout dataset. Similarly, the Behavioral variant of frontotemporal dementia (BV) vs. CN model attains an 88% balanced accuracy on the test subset. The average feature attribution heatmaps obtained by the Integrated Gradient method highlighted hallmark regions, i.e., temporal gray matter atrophy for AD, and insular atrophy for BV.</p><p><strong>Conclusion: </strong>Our models perform comparably to state-of-the-art supervised deep learning approaches. This suggests that the SSL methodology can successfully make use of unannotated neuroimaging datasets as training data while remaining robust and interpretable.</p>","PeriodicalId":12462,"journal":{"name":"Frontiers in Neuroinformatics","volume":"19 ","pages":"1527582"},"PeriodicalIF":2.5000,"publicationDate":"2025-02-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11873101/pdf/","citationCount":"0","resultStr":"{\"title\":\"Contrastive self-supervised learning for neurodegenerative disorder classification.\",\"authors\":\"Vadym Gryshchuk, Devesh Singh, Stefan Teipel, Martin Dyrba\",\"doi\":\"10.3389/fninf.2025.1527582\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Introduction: </strong>Neurodegenerative diseases such as Alzheimer's disease (AD) or frontotemporal lobar degeneration (FTLD) involve specific loss of brain volume, detectable <i>in vivo</i> using T1-weighted MRI scans. Supervised machine learning approaches classifying neurodegenerative diseases require diagnostic-labels for each sample. However, it can be difficult to obtain expert labels for a large amount of data. Self-supervised learning (SSL) offers an alternative for training machine learning models without data-labels.</p><p><strong>Methods: </strong>We investigated if the SSL models can be applied to distinguish between different neurodegenerative disorders in an interpretable manner. Our method comprises a feature extractor and a downstream classification head. A deep convolutional neural network, trained with a contrastive loss, serves as the feature extractor that learns latent representations. The classification head is a single-layer perceptron that is trained to perform diagnostic group separation. We used <i>N</i> = 2,694 T1-weighted MRI scans from four data cohorts: two ADNI datasets, AIBL and FTLDNI, including cognitively normal controls (CN), cases with prodromal and clinical AD, as well as FTLD cases differentiated into its phenotypes.</p><p><strong>Results: </strong>Our results showed that the feature extractor trained in a self-supervised way provides generalizable and robust representations for the downstream classification. For AD vs. CN, our model achieves 82% balanced accuracy on the test subset and 80% on an independent holdout dataset. Similarly, the Behavioral variant of frontotemporal dementia (BV) vs. CN model attains an 88% balanced accuracy on the test subset. The average feature attribution heatmaps obtained by the Integrated Gradient method highlighted hallmark regions, i.e., temporal gray matter atrophy for AD, and insular atrophy for BV.</p><p><strong>Conclusion: </strong>Our models perform comparably to state-of-the-art supervised deep learning approaches. This suggests that the SSL methodology can successfully make use of unannotated neuroimaging datasets as training data while remaining robust and interpretable.</p>\",\"PeriodicalId\":12462,\"journal\":{\"name\":\"Frontiers in Neuroinformatics\",\"volume\":\"19 \",\"pages\":\"1527582\"},\"PeriodicalIF\":2.5000,\"publicationDate\":\"2025-02-17\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11873101/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Frontiers in Neuroinformatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.3389/fninf.2025.1527582\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in Neuroinformatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.3389/fninf.2025.1527582","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Contrastive self-supervised learning for neurodegenerative disorder classification.
Introduction: Neurodegenerative diseases such as Alzheimer's disease (AD) or frontotemporal lobar degeneration (FTLD) involve specific loss of brain volume, detectable in vivo using T1-weighted MRI scans. Supervised machine learning approaches classifying neurodegenerative diseases require diagnostic-labels for each sample. However, it can be difficult to obtain expert labels for a large amount of data. Self-supervised learning (SSL) offers an alternative for training machine learning models without data-labels.
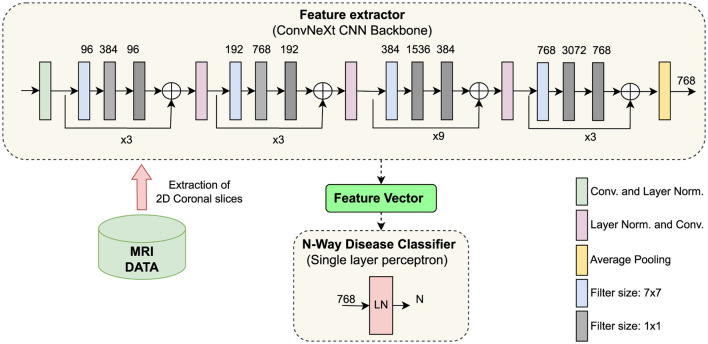
Methods: We investigated if the SSL models can be applied to distinguish between different neurodegenerative disorders in an interpretable manner. Our method comprises a feature extractor and a downstream classification head. A deep convolutional neural network, trained with a contrastive loss, serves as the feature extractor that learns latent representations. The classification head is a single-layer perceptron that is trained to perform diagnostic group separation. We used N = 2,694 T1-weighted MRI scans from four data cohorts: two ADNI datasets, AIBL and FTLDNI, including cognitively normal controls (CN), cases with prodromal and clinical AD, as well as FTLD cases differentiated into its phenotypes.
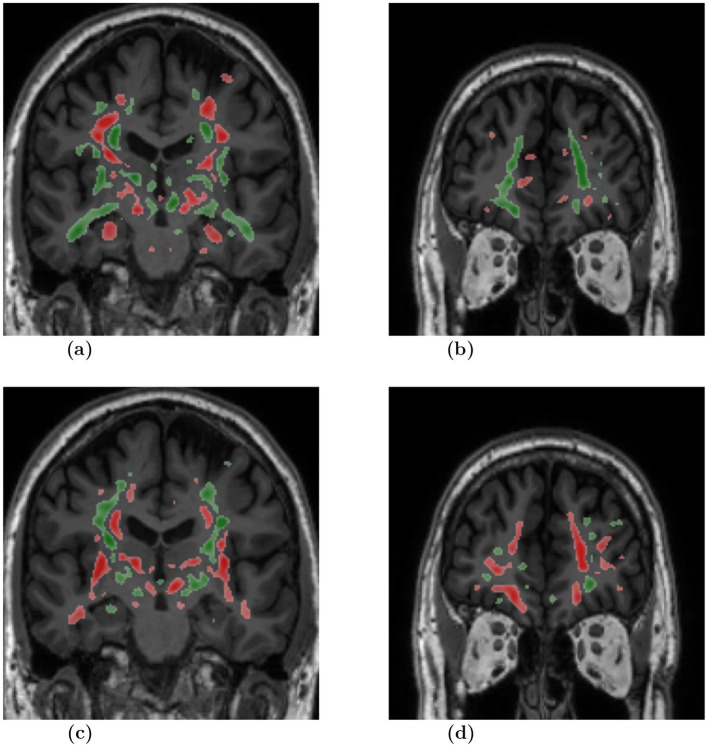
Results: Our results showed that the feature extractor trained in a self-supervised way provides generalizable and robust representations for the downstream classification. For AD vs. CN, our model achieves 82% balanced accuracy on the test subset and 80% on an independent holdout dataset. Similarly, the Behavioral variant of frontotemporal dementia (BV) vs. CN model attains an 88% balanced accuracy on the test subset. The average feature attribution heatmaps obtained by the Integrated Gradient method highlighted hallmark regions, i.e., temporal gray matter atrophy for AD, and insular atrophy for BV.
Conclusion: Our models perform comparably to state-of-the-art supervised deep learning approaches. This suggests that the SSL methodology can successfully make use of unannotated neuroimaging datasets as training data while remaining robust and interpretable.
期刊介绍:
Frontiers in Neuroinformatics publishes rigorously peer-reviewed research on the development and implementation of numerical/computational models and analytical tools used to share, integrate and analyze experimental data and advance theories of the nervous system functions. Specialty Chief Editors Jan G. Bjaalie at the University of Oslo and Sean L. Hill at the École Polytechnique Fédérale de Lausanne are supported by an outstanding Editorial Board of international experts. This multidisciplinary open-access journal is at the forefront of disseminating and communicating scientific knowledge and impactful discoveries to researchers, academics and the public worldwide.
Neuroscience is being propelled into the information age as the volume of information explodes, demanding organization and synthesis. Novel synthesis approaches are opening up a new dimension for the exploration of the components of brain elements and systems and the vast number of variables that underlie their functions. Neural data is highly heterogeneous with complex inter-relations across multiple levels, driving the need for innovative organizing and synthesizing approaches from genes to cognition, and covering a range of species and disease states.
Frontiers in Neuroinformatics therefore welcomes submissions on existing neuroscience databases, development of data and knowledge bases for all levels of neuroscience, applications and technologies that can facilitate data sharing (interoperability, formats, terminologies, and ontologies), and novel tools for data acquisition, analyses, visualization, and dissemination of nervous system data. Our journal welcomes submissions on new tools (software and hardware) that support brain modeling, and the merging of neuroscience databases with brain models used for simulation and visualization.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


