{"title":"在资源受限的 FPGA 平台上实现优化的 k 近邻搜索","authors":"Sandra Djosic, Milica Jovanovic, Goran Lj. Djordjevic","doi":"10.1016/j.micpro.2024.105089","DOIUrl":null,"url":null,"abstract":"<div><p>The k-Nearest Neighbors (kNN) algorithm is a fundamental machine learning classification technique with wide-ranging applications. Among various kNN implementation choices, FPGA-based heterogeneous systems have gained popularity due to FPGA's inherent parallelism, energy efficiency, and reconfigurability. However, implementing the kNN algorithm on resource-constrained embedded FPGA platforms, typically characterized by constrained programmable resources shared among various application-specific hardware units, necessitates a kNN accelerator architecture that balances high performance, hardware efficiency, and flexibility. To address this challenge, in this paper, we present a kNN hardware accelerator unit designed to optimize resource utilization by utilizing sequential, i.e. accumulation-based, instead of pipelined/parallel distance computations. The proposed architecture incorporates two key algorithmic optimizations to reduce the iteration count of the sequential distance computation loop: a dynamic lower bound enabling early termination of the distance computation and an online element selection that maximizes partial distance growth per iteration. We further enhance the accelerator's performance by incorporating multiple optimized sequential distance computation units, each dedicated to processing a segment of the training dataset. Our experiments demonstrate that the proposed approach is scalable, making it applicable to various hardware platforms and resource constraints. In particular, when implemented on an AMD Zynq device, the proposed single-core kNN accelerator occupies a mere 5 % of the FPGA's resources while delivering a speedup of 3 – 5 times compared to the kNN software implementation running on the accompanying ARM A9 processor. For the 8-core kNN accelerator, the resource utilization stands at 30 <span><math><mo>%</mo></math></span>, while the speedup factor ranges between 25 and 35.</p></div>","PeriodicalId":49815,"journal":{"name":"Microprocessors and Microsystems","volume":"109 ","pages":"Article 105089"},"PeriodicalIF":2.6000,"publicationDate":"2024-08-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Optimized k-Nearest neighbors search implementation on resource-constrained FPGA platforms\",\"authors\":\"Sandra Djosic, Milica Jovanovic, Goran Lj. Djordjevic\",\"doi\":\"10.1016/j.micpro.2024.105089\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>The k-Nearest Neighbors (kNN) algorithm is a fundamental machine learning classification technique with wide-ranging applications. Among various kNN implementation choices, FPGA-based heterogeneous systems have gained popularity due to FPGA's inherent parallelism, energy efficiency, and reconfigurability. However, implementing the kNN algorithm on resource-constrained embedded FPGA platforms, typically characterized by constrained programmable resources shared among various application-specific hardware units, necessitates a kNN accelerator architecture that balances high performance, hardware efficiency, and flexibility. To address this challenge, in this paper, we present a kNN hardware accelerator unit designed to optimize resource utilization by utilizing sequential, i.e. accumulation-based, instead of pipelined/parallel distance computations. The proposed architecture incorporates two key algorithmic optimizations to reduce the iteration count of the sequential distance computation loop: a dynamic lower bound enabling early termination of the distance computation and an online element selection that maximizes partial distance growth per iteration. We further enhance the accelerator's performance by incorporating multiple optimized sequential distance computation units, each dedicated to processing a segment of the training dataset. Our experiments demonstrate that the proposed approach is scalable, making it applicable to various hardware platforms and resource constraints. In particular, when implemented on an AMD Zynq device, the proposed single-core kNN accelerator occupies a mere 5 % of the FPGA's resources while delivering a speedup of 3 – 5 times compared to the kNN software implementation running on the accompanying ARM A9 processor. For the 8-core kNN accelerator, the resource utilization stands at 30 <span><math><mo>%</mo></math></span>, while the speedup factor ranges between 25 and 35.</p></div>\",\"PeriodicalId\":49815,\"journal\":{\"name\":\"Microprocessors and Microsystems\",\"volume\":\"109 \",\"pages\":\"Article 105089\"},\"PeriodicalIF\":2.6000,\"publicationDate\":\"2024-08-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Microprocessors and Microsystems\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S014193312400084X\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Microprocessors and Microsystems","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S014193312400084X","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE","Score":null,"Total":0}
Optimized k-Nearest neighbors search implementation on resource-constrained FPGA platforms
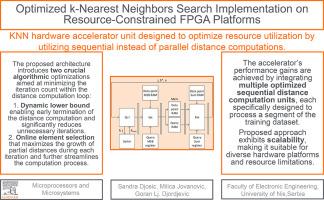
The k-Nearest Neighbors (kNN) algorithm is a fundamental machine learning classification technique with wide-ranging applications. Among various kNN implementation choices, FPGA-based heterogeneous systems have gained popularity due to FPGA's inherent parallelism, energy efficiency, and reconfigurability. However, implementing the kNN algorithm on resource-constrained embedded FPGA platforms, typically characterized by constrained programmable resources shared among various application-specific hardware units, necessitates a kNN accelerator architecture that balances high performance, hardware efficiency, and flexibility. To address this challenge, in this paper, we present a kNN hardware accelerator unit designed to optimize resource utilization by utilizing sequential, i.e. accumulation-based, instead of pipelined/parallel distance computations. The proposed architecture incorporates two key algorithmic optimizations to reduce the iteration count of the sequential distance computation loop: a dynamic lower bound enabling early termination of the distance computation and an online element selection that maximizes partial distance growth per iteration. We further enhance the accelerator's performance by incorporating multiple optimized sequential distance computation units, each dedicated to processing a segment of the training dataset. Our experiments demonstrate that the proposed approach is scalable, making it applicable to various hardware platforms and resource constraints. In particular, when implemented on an AMD Zynq device, the proposed single-core kNN accelerator occupies a mere 5 % of the FPGA's resources while delivering a speedup of 3 – 5 times compared to the kNN software implementation running on the accompanying ARM A9 processor. For the 8-core kNN accelerator, the resource utilization stands at 30 , while the speedup factor ranges between 25 and 35.
期刊介绍:
Microprocessors and Microsystems: Embedded Hardware Design (MICPRO) is a journal covering all design and architectural aspects related to embedded systems hardware. This includes different embedded system hardware platforms ranging from custom hardware via reconfigurable systems and application specific processors to general purpose embedded processors. Special emphasis is put on novel complex embedded architectures, such as systems on chip (SoC), systems on a programmable/reconfigurable chip (SoPC) and multi-processor systems on a chip (MPSoC), as well as, their memory and communication methods and structures, such as network-on-chip (NoC).
Design automation of such systems including methodologies, techniques, flows and tools for their design, as well as, novel designs of hardware components fall within the scope of this journal. Novel cyber-physical applications that use embedded systems are also central in this journal. While software is not in the main focus of this journal, methods of hardware/software co-design, as well as, application restructuring and mapping to embedded hardware platforms, that consider interplay between software and hardware components with emphasis on hardware, are also in the journal scope.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


