Jose R. Mora, Edgar A. Marquez, Noel Pérez-Pérez, Ernesto Contreras-Torres, Yunierkis Perez-Castillo, Guillermin Agüero-Chapin, Felix Martinez-Rios, Yovani Marrero-Ponce, Stephen J. Barigye
{"title":"重新思考 QSAR 模型中的适用域分析。","authors":"Jose R. Mora, Edgar A. Marquez, Noel Pérez-Pérez, Ernesto Contreras-Torres, Yunierkis Perez-Castillo, Guillermin Agüero-Chapin, Felix Martinez-Rios, Yovani Marrero-Ponce, Stephen J. Barigye","doi":"10.1007/s10822-024-00550-8","DOIUrl":null,"url":null,"abstract":"<div><p>Notwithstanding the wide adoption of the OECD principles (or best practices) for QSAR modeling, disparities between <i>in silico</i> predictions and experimental results are frequent, suggesting that model predictions are often too optimistic. Of these OECD principles, the applicability domain (AD) estimation has been recognized in several reports in the literature to be one of the most challenging, implying that the actual reliability measures of model predictions are often unreliable. Applying tree-based error analysis workflows on 5 QSAR models reported in the literature and available in the QsarDB repository, i.e., androgen receptor bioactivity (agonists, antagonists, and binders, respectively) and membrane permeability (highest membrane permeability and the intrinsic permeability), we demonstrate that predictions erroneously tagged as reliable (AD prediction errors) overwhelmingly correspond to instances in subspaces (cohorts) with the highest prediction error rates, highlighting the inhomogeneity of the AD space. In this sense, we call for more stringent AD analysis guidelines which require the incorporation of model error analysis schemes, to provide critical insight on the reliability of underlying AD algorithms. Additionally, any selected AD method should be rigorously validated to demonstrate its suitability for the model space over which it is applied. These steps will ultimately contribute to more accurate estimations of the reliability of model predictions. Finally, error analysis may also be useful in “rational” model refinement in that data expansion efforts and model retraining are focused on cohorts with the highest error rates.</p></div>","PeriodicalId":621,"journal":{"name":"Journal of Computer-Aided Molecular Design","volume":"38 1","pages":""},"PeriodicalIF":3.0000,"publicationDate":"2024-02-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Rethinking the applicability domain analysis in QSAR models\",\"authors\":\"Jose R. Mora, Edgar A. Marquez, Noel Pérez-Pérez, Ernesto Contreras-Torres, Yunierkis Perez-Castillo, Guillermin Agüero-Chapin, Felix Martinez-Rios, Yovani Marrero-Ponce, Stephen J. Barigye\",\"doi\":\"10.1007/s10822-024-00550-8\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Notwithstanding the wide adoption of the OECD principles (or best practices) for QSAR modeling, disparities between <i>in silico</i> predictions and experimental results are frequent, suggesting that model predictions are often too optimistic. Of these OECD principles, the applicability domain (AD) estimation has been recognized in several reports in the literature to be one of the most challenging, implying that the actual reliability measures of model predictions are often unreliable. Applying tree-based error analysis workflows on 5 QSAR models reported in the literature and available in the QsarDB repository, i.e., androgen receptor bioactivity (agonists, antagonists, and binders, respectively) and membrane permeability (highest membrane permeability and the intrinsic permeability), we demonstrate that predictions erroneously tagged as reliable (AD prediction errors) overwhelmingly correspond to instances in subspaces (cohorts) with the highest prediction error rates, highlighting the inhomogeneity of the AD space. In this sense, we call for more stringent AD analysis guidelines which require the incorporation of model error analysis schemes, to provide critical insight on the reliability of underlying AD algorithms. Additionally, any selected AD method should be rigorously validated to demonstrate its suitability for the model space over which it is applied. These steps will ultimately contribute to more accurate estimations of the reliability of model predictions. Finally, error analysis may also be useful in “rational” model refinement in that data expansion efforts and model retraining are focused on cohorts with the highest error rates.</p></div>\",\"PeriodicalId\":621,\"journal\":{\"name\":\"Journal of Computer-Aided Molecular Design\",\"volume\":\"38 1\",\"pages\":\"\"},\"PeriodicalIF\":3.0000,\"publicationDate\":\"2024-02-14\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Computer-Aided Molecular Design\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s10822-024-00550-8\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"BIOCHEMISTRY & MOLECULAR BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Computer-Aided Molecular Design","FirstCategoryId":"99","ListUrlMain":"https://link.springer.com/article/10.1007/s10822-024-00550-8","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"BIOCHEMISTRY & MOLECULAR BIOLOGY","Score":null,"Total":0}
引用次数: 0
摘要
尽管 QSAR 建模广泛采用了 OECD 原则(或最佳实践),但硅学预测与实验结果之间经常出现差异,这表明模型预测往往过于乐观。在这些 OECD 原则中,适用域(AD)估算在一些文献报告中被认为是最具挑战性的原则之一,这意味着模型预测的实际可靠性度量往往不可靠。对文献中报道的、QsarDB 数据库中的 5 个 QSAR 模型(即雄激素受体生物活性(分别为激动剂、拮抗剂和粘合剂)和膜渗透性(最高膜渗透性和内在渗透性),我们证明了被错误地标记为可靠的预测(AD 预测错误)绝大多数对应于预测错误率最高的子空间(队列)中的实例,突出了 AD 空间的不均匀性。从这个意义上说,我们呼吁制定更严格的 AD 分析指南,要求纳入模型误差分析方案,以提供对基础 AD 算法可靠性的重要见解。此外,任何选定的 AD 方法都应经过严格验证,以证明其适用于所应用的模型空间。这些步骤最终将有助于更准确地估计模型预测的可靠性。最后,误差分析还有助于 "合理 "地完善模型,因为数据扩展工作和模型再训练都将重点放在误差率最高的队列上。
Rethinking the applicability domain analysis in QSAR models
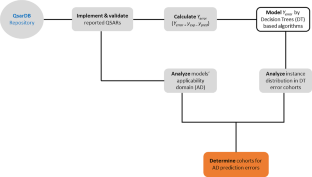
Notwithstanding the wide adoption of the OECD principles (or best practices) for QSAR modeling, disparities between in silico predictions and experimental results are frequent, suggesting that model predictions are often too optimistic. Of these OECD principles, the applicability domain (AD) estimation has been recognized in several reports in the literature to be one of the most challenging, implying that the actual reliability measures of model predictions are often unreliable. Applying tree-based error analysis workflows on 5 QSAR models reported in the literature and available in the QsarDB repository, i.e., androgen receptor bioactivity (agonists, antagonists, and binders, respectively) and membrane permeability (highest membrane permeability and the intrinsic permeability), we demonstrate that predictions erroneously tagged as reliable (AD prediction errors) overwhelmingly correspond to instances in subspaces (cohorts) with the highest prediction error rates, highlighting the inhomogeneity of the AD space. In this sense, we call for more stringent AD analysis guidelines which require the incorporation of model error analysis schemes, to provide critical insight on the reliability of underlying AD algorithms. Additionally, any selected AD method should be rigorously validated to demonstrate its suitability for the model space over which it is applied. These steps will ultimately contribute to more accurate estimations of the reliability of model predictions. Finally, error analysis may also be useful in “rational” model refinement in that data expansion efforts and model retraining are focused on cohorts with the highest error rates.
期刊介绍:
The Journal of Computer-Aided Molecular Design provides a form for disseminating information on both the theory and the application of computer-based methods in the analysis and design of molecules. The scope of the journal encompasses papers which report new and original research and applications in the following areas:
- theoretical chemistry;
- computational chemistry;
- computer and molecular graphics;
- molecular modeling;
- protein engineering;
- drug design;
- expert systems;
- general structure-property relationships;
- molecular dynamics;
- chemical database development and usage.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


