{"title":"利用反事实数据增强的去伪存真变分自动编码器","authors":"Yupu Guo, Fei Cai, Jianming Zheng, Xin Zhang, Honghui Chen","doi":"10.1007/s40747-023-01314-x","DOIUrl":null,"url":null,"abstract":"<p>Recommender system always suffers from various recommendation biases, seriously hindering its development. In this light, a series of debias methods have been proposed in the recommender system, especially for two most common biases, i.e., popularity bias and amplified subjective bias. However, existing debias methods usually concentrate on correcting a single bias. Such single-functionality debiases neglect the bias-coupling issue in which the recommended items are collectively attributed to multiple biases. Besides, previous work cannot tackle the lacking supervised signals brought by sparse data, yet which has become a commonplace in the recommender system. In this work, we introduce a disentangled debias variational auto-encoder framework (DB-VAE) to address the single-functionality issue as well as a counterfactual data enhancement method to mitigate the adverse effect due to the data sparsity. In specific, DB-VAE first extracts two types of extreme items only affected by a single bias based on the collier theory, which are, respectively, employed to learn the latent representation of corresponding biases, thereby realizing the bias decoupling. In this way, the exact unbiased user representation can be learned by these decoupled bias representations. Furthermore, the data generation module employs Pearl’s framework to produce massive counterfactual data to help fully train the model, making up the lacking supervised signals due to the sparse data. Extensive experiments on three real-world data sets demonstrate the effectiveness of our proposed model. Specifically, our model outperforms the best baseline by 19.5% in terms of Recall@20 and 9.5% in terms of NDCG@100 in the best scenario. Besides, the counterfactual data can further improve DB-VAE, especially on the data set with low sparsity.</p>","PeriodicalId":10524,"journal":{"name":"Complex & Intelligent Systems","volume":"54 1","pages":""},"PeriodicalIF":5.0000,"publicationDate":"2024-01-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Disentangled variational auto-encoder enhanced by counterfactual data for debiasing recommendation\",\"authors\":\"Yupu Guo, Fei Cai, Jianming Zheng, Xin Zhang, Honghui Chen\",\"doi\":\"10.1007/s40747-023-01314-x\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Recommender system always suffers from various recommendation biases, seriously hindering its development. In this light, a series of debias methods have been proposed in the recommender system, especially for two most common biases, i.e., popularity bias and amplified subjective bias. However, existing debias methods usually concentrate on correcting a single bias. Such single-functionality debiases neglect the bias-coupling issue in which the recommended items are collectively attributed to multiple biases. Besides, previous work cannot tackle the lacking supervised signals brought by sparse data, yet which has become a commonplace in the recommender system. In this work, we introduce a disentangled debias variational auto-encoder framework (DB-VAE) to address the single-functionality issue as well as a counterfactual data enhancement method to mitigate the adverse effect due to the data sparsity. In specific, DB-VAE first extracts two types of extreme items only affected by a single bias based on the collier theory, which are, respectively, employed to learn the latent representation of corresponding biases, thereby realizing the bias decoupling. In this way, the exact unbiased user representation can be learned by these decoupled bias representations. Furthermore, the data generation module employs Pearl’s framework to produce massive counterfactual data to help fully train the model, making up the lacking supervised signals due to the sparse data. Extensive experiments on three real-world data sets demonstrate the effectiveness of our proposed model. Specifically, our model outperforms the best baseline by 19.5% in terms of Recall@20 and 9.5% in terms of NDCG@100 in the best scenario. Besides, the counterfactual data can further improve DB-VAE, especially on the data set with low sparsity.</p>\",\"PeriodicalId\":10524,\"journal\":{\"name\":\"Complex & Intelligent Systems\",\"volume\":\"54 1\",\"pages\":\"\"},\"PeriodicalIF\":5.0000,\"publicationDate\":\"2024-01-12\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Complex & Intelligent Systems\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s40747-023-01314-x\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Complex & Intelligent Systems","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s40747-023-01314-x","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Disentangled variational auto-encoder enhanced by counterfactual data for debiasing recommendation
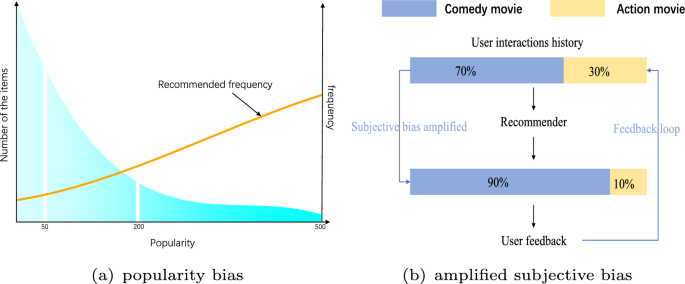
Recommender system always suffers from various recommendation biases, seriously hindering its development. In this light, a series of debias methods have been proposed in the recommender system, especially for two most common biases, i.e., popularity bias and amplified subjective bias. However, existing debias methods usually concentrate on correcting a single bias. Such single-functionality debiases neglect the bias-coupling issue in which the recommended items are collectively attributed to multiple biases. Besides, previous work cannot tackle the lacking supervised signals brought by sparse data, yet which has become a commonplace in the recommender system. In this work, we introduce a disentangled debias variational auto-encoder framework (DB-VAE) to address the single-functionality issue as well as a counterfactual data enhancement method to mitigate the adverse effect due to the data sparsity. In specific, DB-VAE first extracts two types of extreme items only affected by a single bias based on the collier theory, which are, respectively, employed to learn the latent representation of corresponding biases, thereby realizing the bias decoupling. In this way, the exact unbiased user representation can be learned by these decoupled bias representations. Furthermore, the data generation module employs Pearl’s framework to produce massive counterfactual data to help fully train the model, making up the lacking supervised signals due to the sparse data. Extensive experiments on three real-world data sets demonstrate the effectiveness of our proposed model. Specifically, our model outperforms the best baseline by 19.5% in terms of Recall@20 and 9.5% in terms of NDCG@100 in the best scenario. Besides, the counterfactual data can further improve DB-VAE, especially on the data set with low sparsity.
期刊介绍:
Complex & Intelligent Systems aims to provide a forum for presenting and discussing novel approaches, tools and techniques meant for attaining a cross-fertilization between the broad fields of complex systems, computational simulation, and intelligent analytics and visualization. The transdisciplinary research that the journal focuses on will expand the boundaries of our understanding by investigating the principles and processes that underlie many of the most profound problems facing society today.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


