长文本生成的句子级启发式树搜索
IF 5
2区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
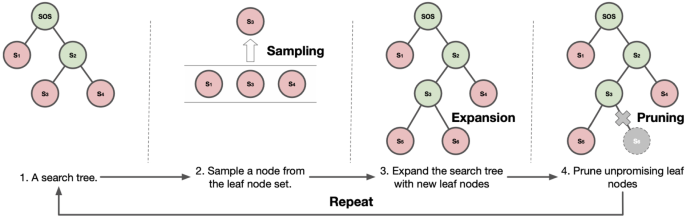
在本研究中,我们主要旨在解决统计语言模型固有的长文本生成中的暴露偏差问题。我们提出了一个句子级启发式树搜索算法,专门为长文本生成量身定制,通过在树结构中管理生成的文本并抑制偏差的复合来缓解这个问题。我们的算法使用两个预训练的语言模型,一个用于生成新句子的自回归模型和一个用于评估句子质量的自编码器模型。这些模型协同执行四个关键操作:用新句子扩展文本树,评估添加的质量,为进一步生成采样潜在的未完成文本片段,以及修剪被认为没有前途的叶节点。这个迭代过程一直持续到生成预定义数量的[EOS]代币,此时我们选择得分最高的完成文本作为最终输出。此外,我们还提出了两种新的令牌级解码技术——带温度的核采样技术和带采样的多束搜索技术。这些方法与我们的句子级搜索算法相结合,旨在提高文本生成的一致性和多样性。实验结果,包括自动测量(包括Jaccard相似度、Word2vec相似度和唯一词比)和人工评估(评估一致性、流畅性和修辞技巧),最终表明我们的方法大大提高了机器生成的长格式文本的质量。通过这项研究,我们的目标是激发基于句子级搜索的文本生成算法的进一步创新。本文章由计算机程序翻译,如有差异,请以英文原文为准。
Sentence-level heuristic tree search for long text generation
Abstract In this study, we primarily aim to address the exposure bias issue in long text generation intrinsic to statistical language models. We propose a sentence-level heuristic tree search algorithm, specially tailored for long text generation, to mitigate the problem by managing generated texts in a tree structure and curbing the compounding of biases. Our algorithm utilizes two pre-trained language models, an auto-regressive model for generating new sentences and an auto-encoder model for evaluating sentence quality. These models work in tandem to perform four critical operations: expanding the text tree with new sentences, evaluating the quality of the additions, sampling potential unfinished text fragments for further generation, and pruning leaf nodes deemed unpromising. This iterative process continues until a pre-defined number of [EOS] tokens are produced, at which point we select the highest-scoring completed text as our final output. Moreover, we pioneer two novel token-level decoding techniques—nucleus sampling with temperature and diverse beam search with sampling. These methods, integrated with our sentence-level search algorithm, aim to improve the consistency and diversity of text generation. Experimental results, both automated measures (including Jaccard similarity, Word2vec similarity, and unique word ratio) and human evaluations (assessing consistency, fluency, and rhetorical skills), conclusively demonstrate that our approach considerably enhances the quality of machine-generated long-form text. Through this research, we aim to inspire further innovations in sentence-level search-based text generation algorithms.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Complex & Intelligent Systems
COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE-
CiteScore
9.60
自引率
10.30%
发文量
297
期刊介绍:
Complex & Intelligent Systems aims to provide a forum for presenting and discussing novel approaches, tools and techniques meant for attaining a cross-fertilization between the broad fields of complex systems, computational simulation, and intelligent analytics and visualization. The transdisciplinary research that the journal focuses on will expand the boundaries of our understanding by investigating the principles and processes that underlie many of the most profound problems facing society today.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


