Esben Jannik Bjerrum, Christian Margreitter, Thomas Blaschke, Simona Kolarova, Raquel López-Ríos de Castro
{"title":"Faster and more diverse de novo molecular optimization with double-loop reinforcement learning using augmented SMILES","authors":"Esben Jannik Bjerrum, Christian Margreitter, Thomas Blaschke, Simona Kolarova, Raquel López-Ríos de Castro","doi":"10.1007/s10822-023-00512-6","DOIUrl":null,"url":null,"abstract":"<div><p>Using generative deep learning models and reinforcement learning together can effectively generate new molecules with desired properties. By employing a multi-objective scoring function, thousands of high-scoring molecules can be generated, making this approach useful for drug discovery and material science. However, the application of these methods can be hindered by computationally expensive or time-consuming scoring procedures, particularly when a large number of function calls are required as feedback in the reinforcement learning optimization. Here, we propose the use of double-loop reinforcement learning with simplified molecular line entry system (SMILES) augmentation to improve the efficiency and speed of the optimization. By adding an inner loop that augments the generated SMILES strings to non-canonical SMILES for use in additional reinforcement learning rounds, we can both reuse the scoring calculations on the molecular level, thereby speeding up the learning process, as well as offer additional protection against mode collapse. We find that employing between 5 and 10 augmentation repetitions is optimal for the scoring functions tested and is further associated with an increased diversity in the generated compounds, improved reproducibility of the sampling runs and the generation of molecules of higher similarity to known ligands.</p></div>","PeriodicalId":621,"journal":{"name":"Journal of Computer-Aided Molecular Design","volume":"37 8","pages":"373 - 394"},"PeriodicalIF":3.0000,"publicationDate":"2023-06-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://link.springer.com/content/pdf/10.1007/s10822-023-00512-6.pdf","citationCount":"4","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Computer-Aided Molecular Design","FirstCategoryId":"99","ListUrlMain":"https://link.springer.com/article/10.1007/s10822-023-00512-6","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"BIOCHEMISTRY & MOLECULAR BIOLOGY","Score":null,"Total":0}
引用次数: 4
Abstract
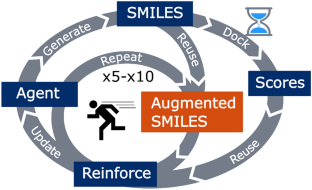
Using generative deep learning models and reinforcement learning together can effectively generate new molecules with desired properties. By employing a multi-objective scoring function, thousands of high-scoring molecules can be generated, making this approach useful for drug discovery and material science. However, the application of these methods can be hindered by computationally expensive or time-consuming scoring procedures, particularly when a large number of function calls are required as feedback in the reinforcement learning optimization. Here, we propose the use of double-loop reinforcement learning with simplified molecular line entry system (SMILES) augmentation to improve the efficiency and speed of the optimization. By adding an inner loop that augments the generated SMILES strings to non-canonical SMILES for use in additional reinforcement learning rounds, we can both reuse the scoring calculations on the molecular level, thereby speeding up the learning process, as well as offer additional protection against mode collapse. We find that employing between 5 and 10 augmentation repetitions is optimal for the scoring functions tested and is further associated with an increased diversity in the generated compounds, improved reproducibility of the sampling runs and the generation of molecules of higher similarity to known ligands.
期刊介绍:
The Journal of Computer-Aided Molecular Design provides a form for disseminating information on both the theory and the application of computer-based methods in the analysis and design of molecules. The scope of the journal encompasses papers which report new and original research and applications in the following areas:
- theoretical chemistry;
- computational chemistry;
- computer and molecular graphics;
- molecular modeling;
- protein engineering;
- drug design;
- expert systems;
- general structure-property relationships;
- molecular dynamics;
- chemical database development and usage.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


