Noor Fadhil Jumaa, Jafar Razmara, Sepideh Parvizpour, Jaber Karimpour
{"title":"Hybrid deep learning models for text-based identification of gene-disease associations.","authors":"Noor Fadhil Jumaa, Jafar Razmara, Sepideh Parvizpour, Jaber Karimpour","doi":"10.34172/bi.31226","DOIUrl":null,"url":null,"abstract":"<p><p></p><p><strong>Introduction: </strong>Identifying gene-disease associations is crucial for advancing medical research and improving clinical outcomes. Nevertheless, the rapid expansion of biomedical literature poses significant obstacles to extracting meaningful relationships from extensive text collections.</p><p><strong>Methods: </strong>This study uses deep learning techniques to automate this process, using publicly available datasets (EU-ADR, GAD, and SNPPhenA) to classify these associations accurately. Each dataset underwent rigorous pre-processing, including entity identification and preparation, word embedding using pre-trained Word2Vec and fastText models, and position embedding to capture semantic and contextual relationships within the text. In this research, three deep learning-based hybrid models have been implemented and contrasted, including CNN-LSTM, CNN-GRU, and CNN-GRU-LSTM. Each model has been equipped with attentional mechanisms to enhance its performance.</p><p><strong>Results: </strong>Our findings reveal that the CNN-GRU model achieved the highest accuracy of 91.23% on the SNPPhenA dataset, while the CNN-GRU-LSTM model attained an accuracy of 90.14% on the EU-ADR dataset. Meanwhile, the CNN-LSTM model demonstrated superior performance on the GAD dataset, achieving an accuracy of 84.90%. Compared to previous state-of-the-art methods, such as BioBERT-based models, our hybrid approach demonstrates superior classification performance by effectively capturing local and sequential features without relying on heavy pre-training.</p><p><strong>Conclusion: </strong>The developed models and their evaluation data are available at https://github.com/NoorFadhil/Deep-GDAE.</p>","PeriodicalId":48614,"journal":{"name":"Bioimpacts","volume":"15 ","pages":"31226"},"PeriodicalIF":2.2000,"publicationDate":"2025-06-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12319213/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioimpacts","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.34172/bi.31226","RegionNum":4,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"PHARMACOLOGY & PHARMACY","Score":null,"Total":0}
引用次数: 0
Abstract
Introduction: Identifying gene-disease associations is crucial for advancing medical research and improving clinical outcomes. Nevertheless, the rapid expansion of biomedical literature poses significant obstacles to extracting meaningful relationships from extensive text collections.
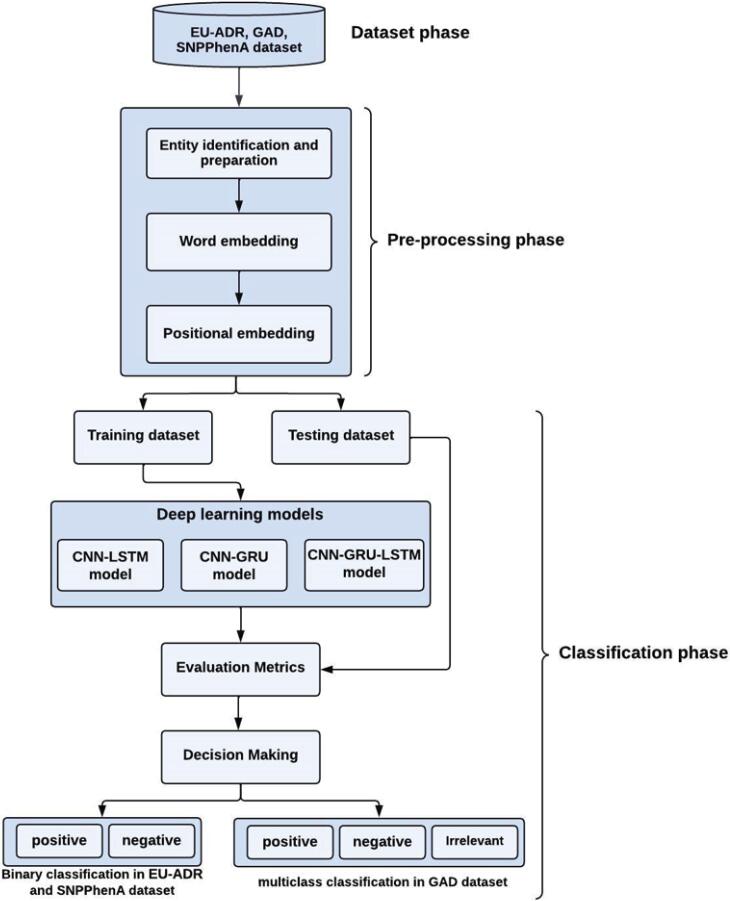
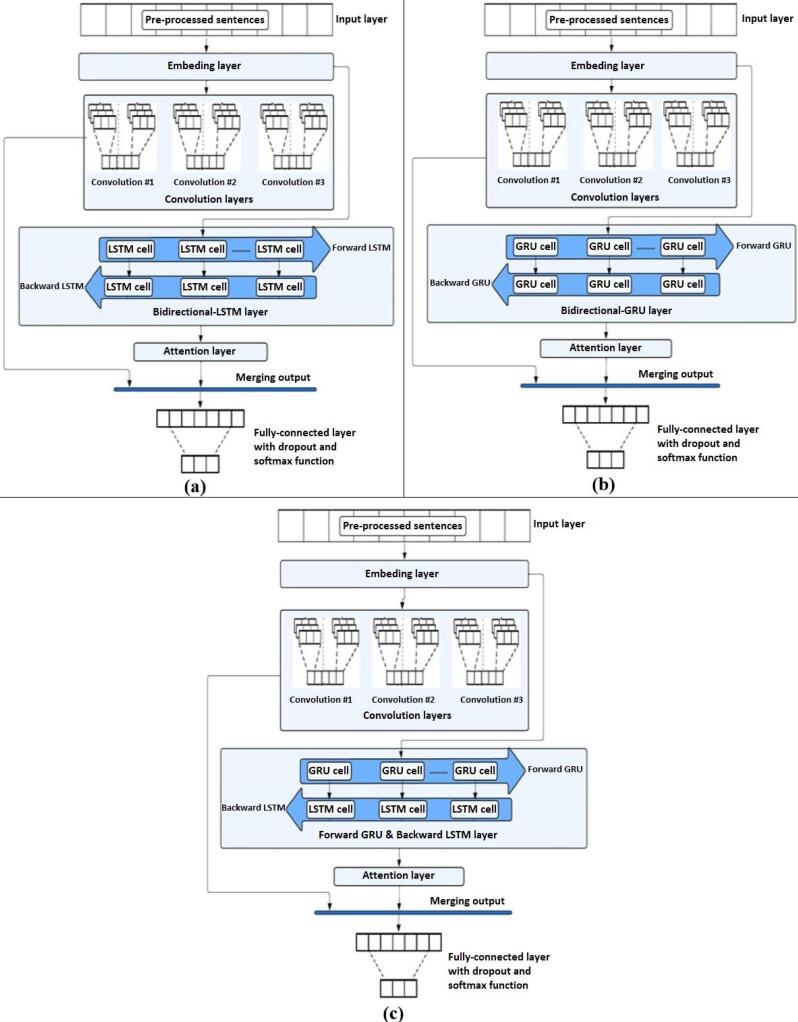
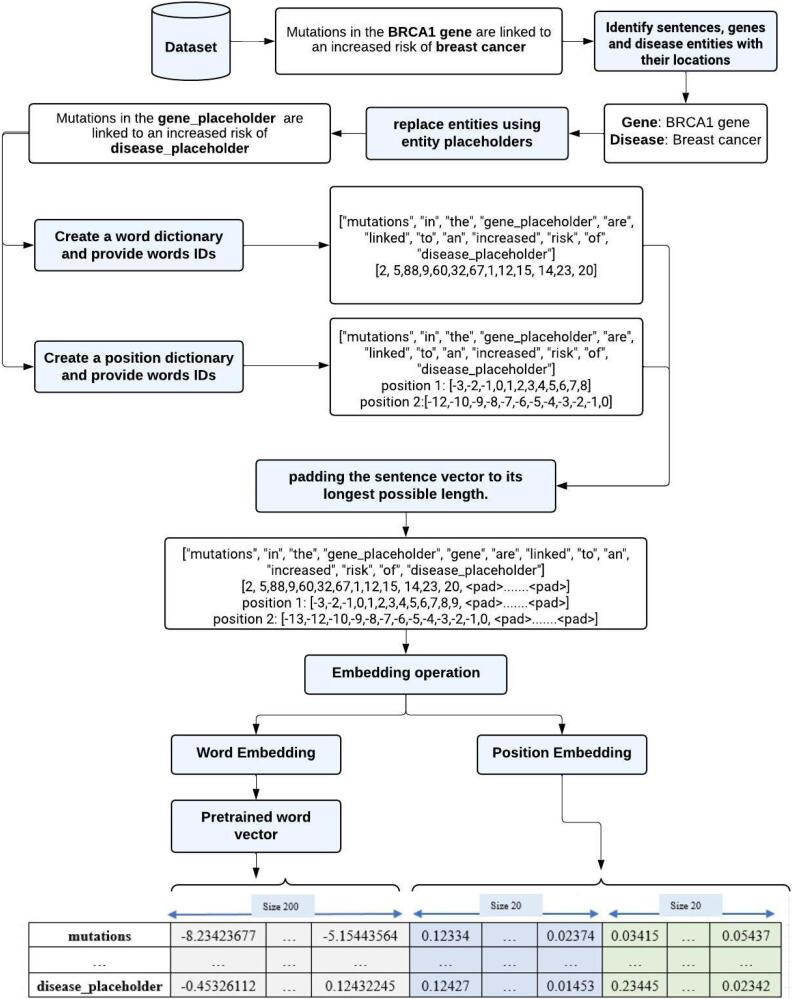
Methods: This study uses deep learning techniques to automate this process, using publicly available datasets (EU-ADR, GAD, and SNPPhenA) to classify these associations accurately. Each dataset underwent rigorous pre-processing, including entity identification and preparation, word embedding using pre-trained Word2Vec and fastText models, and position embedding to capture semantic and contextual relationships within the text. In this research, three deep learning-based hybrid models have been implemented and contrasted, including CNN-LSTM, CNN-GRU, and CNN-GRU-LSTM. Each model has been equipped with attentional mechanisms to enhance its performance.
Results: Our findings reveal that the CNN-GRU model achieved the highest accuracy of 91.23% on the SNPPhenA dataset, while the CNN-GRU-LSTM model attained an accuracy of 90.14% on the EU-ADR dataset. Meanwhile, the CNN-LSTM model demonstrated superior performance on the GAD dataset, achieving an accuracy of 84.90%. Compared to previous state-of-the-art methods, such as BioBERT-based models, our hybrid approach demonstrates superior classification performance by effectively capturing local and sequential features without relying on heavy pre-training.
Conclusion: The developed models and their evaluation data are available at https://github.com/NoorFadhil/Deep-GDAE.
BioimpactsPharmacology, Toxicology and Pharmaceutics-Pharmaceutical Science
CiteScore
4.80
自引率
7.70%
发文量
36
审稿时长
5 weeks
期刊介绍:
BioImpacts (BI) is a peer-reviewed multidisciplinary international journal, covering original research articles, reviews, commentaries, hypotheses, methodologies, and visions/reflections dealing with all aspects of biological and biomedical researches at molecular, cellular, functional and translational dimensions.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


