Evaluating large language models for criterion-based grading from agreement to consistency.
IF 3
1区 心理学
Q1 EDUCATION & EDUCATIONAL RESEARCH
引用次数: 0
Abstract
This study evaluates the ability of large language models (LLMs) to deliver criterion-based grading and examines the impact of prompt engineering with detailed criteria on grading. Using well-established human benchmarks and quantitative analyses, we found that even free LLMs achieve criterion-based grading with a detailed understanding of the criteria, underscoring the importance of domain-specific understanding over model complexity. These findings highlight the potential of LLMs to deliver scalable educational feedback.
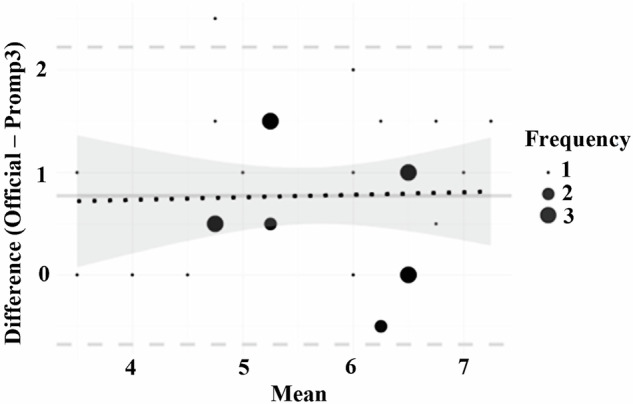
从一致性到一致性,评估基于标准分级的大型语言模型。
本研究评估了大型语言模型(llm)提供基于标准的评分的能力,并检查了带有详细评分标准的即时工程的影响。使用完善的人类基准和定量分析,我们发现即使是免费的法学硕士也可以通过对标准的详细理解来实现基于标准的评分,强调了特定领域对模型复杂性的理解的重要性。这些发现突出了法学硕士在提供可扩展的教育反馈方面的潜力。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


