{"title":"On-demand reverse design of polymers with PolyTAO","authors":"Haoke Qiu, Zhao-Yan Sun","doi":"10.1038/s41524-024-01466-5","DOIUrl":null,"url":null,"abstract":"<p>The forward screening and reverse design of drug molecules, inorganic molecules, and polymers with enhanced properties are vital for accelerating the transition from laboratory research to market application. Specifically, due to the scarcity of large-scale datasets, the discovery of polymers via materials informatics is particularly challenging. Nonetheless, scientists have developed various machine learning models for polymer structure-property relationships using only small polymer datasets, thereby advancing the forward screening process of polymers. However, the success of this approach ultimately depends on the diversity of the candidate pool, and exhaustively enumerating all possible polymer structures through human imagination is impractical. Consequently, achieving on-demand reverse design of polymers is essential. In this work, we curate an immense polymer dataset containing nearly one million polymeric structure-property pairs based on expert knowledge. Leveraging this dataset, we propose a Transformer-Assisted Oriented pretrained model for on-demand polymer generation (PolyTAO). This model generates polymers with 99.27% chemical validity in top-1 generation mode (approximately 200k generated polymers), representing the highest reported success rate among polymer generative models, and this was achieved on the largest test set. Importantly, the average <i>R</i><sup>2</sup> between the properties of the generated polymers and their expected values across 15 predefined properties is 0.96, which underscores PolyTAO’s powerful on-demand polymer generation capabilities. To further evaluate the pretrained model’s performance in generating polymers with additional user-defined properties for downstream tasks, we conduct fine-tuning experiments on three publicly available small polymer datasets using both semi-template and template-free generation paradigms. Through these extensive experiments, we demonstrate that our pretrained model and its fine-tuned versions are capable of achieving the on-demand reverse design of polymers with specified properties, whether in a semi-template generation or the more challenging template-free generation scenarios, showcasing its potential as a unified pretrained foundation model for polymer generation.</p>","PeriodicalId":19342,"journal":{"name":"npj Computational Materials","volume":"26 1","pages":""},"PeriodicalIF":9.4000,"publicationDate":"2024-11-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"npj Computational Materials","FirstCategoryId":"88","ListUrlMain":"https://doi.org/10.1038/s41524-024-01466-5","RegionNum":1,"RegionCategory":"材料科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, PHYSICAL","Score":null,"Total":0}
引用次数: 0
Abstract
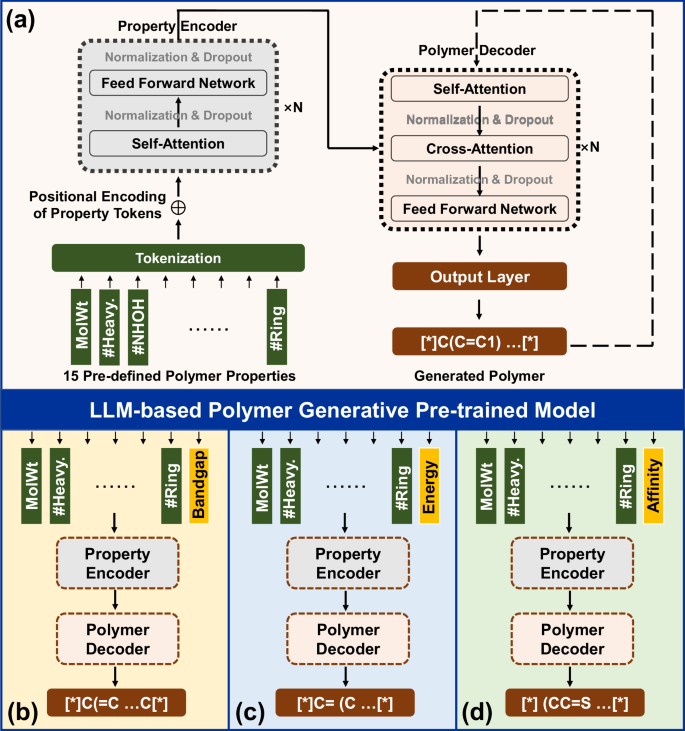
The forward screening and reverse design of drug molecules, inorganic molecules, and polymers with enhanced properties are vital for accelerating the transition from laboratory research to market application. Specifically, due to the scarcity of large-scale datasets, the discovery of polymers via materials informatics is particularly challenging. Nonetheless, scientists have developed various machine learning models for polymer structure-property relationships using only small polymer datasets, thereby advancing the forward screening process of polymers. However, the success of this approach ultimately depends on the diversity of the candidate pool, and exhaustively enumerating all possible polymer structures through human imagination is impractical. Consequently, achieving on-demand reverse design of polymers is essential. In this work, we curate an immense polymer dataset containing nearly one million polymeric structure-property pairs based on expert knowledge. Leveraging this dataset, we propose a Transformer-Assisted Oriented pretrained model for on-demand polymer generation (PolyTAO). This model generates polymers with 99.27% chemical validity in top-1 generation mode (approximately 200k generated polymers), representing the highest reported success rate among polymer generative models, and this was achieved on the largest test set. Importantly, the average R2 between the properties of the generated polymers and their expected values across 15 predefined properties is 0.96, which underscores PolyTAO’s powerful on-demand polymer generation capabilities. To further evaluate the pretrained model’s performance in generating polymers with additional user-defined properties for downstream tasks, we conduct fine-tuning experiments on three publicly available small polymer datasets using both semi-template and template-free generation paradigms. Through these extensive experiments, we demonstrate that our pretrained model and its fine-tuned versions are capable of achieving the on-demand reverse design of polymers with specified properties, whether in a semi-template generation or the more challenging template-free generation scenarios, showcasing its potential as a unified pretrained foundation model for polymer generation.
期刊介绍:
npj Computational Materials is a high-quality open access journal from Nature Research that publishes research papers applying computational approaches for the design of new materials and enhancing our understanding of existing ones. The journal also welcomes papers on new computational techniques and the refinement of current approaches that support these aims, as well as experimental papers that complement computational findings.
Some key features of npj Computational Materials include a 2-year impact factor of 12.241 (2021), article downloads of 1,138,590 (2021), and a fast turnaround time of 11 days from submission to the first editorial decision. The journal is indexed in various databases and services, including Chemical Abstracts Service (ACS), Astrophysics Data System (ADS), Current Contents/Physical, Chemical and Earth Sciences, Journal Citation Reports/Science Edition, SCOPUS, EI Compendex, INSPEC, Google Scholar, SCImago, DOAJ, CNKI, and Science Citation Index Expanded (SCIE), among others.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


