Chaoran Li, Xiyin Wu, Pai Peng, Zhuhong Zhang, Xiaohuan Lu
{"title":"Incomplete multi-view partial multi-label classification via deep semantic structure preservation","authors":"Chaoran Li, Xiyin Wu, Pai Peng, Zhuhong Zhang, Xiaohuan Lu","doi":"10.1007/s40747-024-01562-5","DOIUrl":null,"url":null,"abstract":"<p>Recent advances in multi-view multi-label learning are often hampered by the prevalent challenges of incomplete views and missing labels, common in real-world data due to uncertainties in data collection and manual annotation. These challenges restrict the capacity of the model to fully utilize the diverse semantic information of each sample, posing significant barriers to effective learning. Despite substantial scholarly efforts, many existing methods inadequately capture the depth of semantic information, focusing primarily on shallow feature extractions that fail to maintain semantic consistency. To address these shortcomings, we propose a novel Deep semantic structure-preserving (SSP) model that effectively tackles both incomplete views and missing labels. SSP innovatively incorporates a graph constraint learning (GCL) scheme to ensure the preservation of semantic structure throughout the feature extraction process across different views. Additionally, the SSP integrates a pseudo-labeling self-paced learning (PSL) strategy to address the often-overlooked issue of missing labels, enhancing the classification accuracy while preserving the distribution structure of data. The SSP model creates a unified framework that synergistically employs GCL and PSL to maintain the integrity of semantic structural information during both feature extraction and classification phases. Extensive evaluations across five real datasets demonstrate that the SSP method outperforms existing approaches, including lrMMC, MVL-IV, MvEL, iMSF, iMvWL, NAIML, and DD-IMvMLC-net. It effectively mitigates the impacts of data incompleteness and enhances semantic representation fidelity.</p>","PeriodicalId":10524,"journal":{"name":"Complex & Intelligent Systems","volume":"32 1","pages":""},"PeriodicalIF":5.0000,"publicationDate":"2024-07-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Complex & Intelligent Systems","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s40747-024-01562-5","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
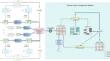
Recent advances in multi-view multi-label learning are often hampered by the prevalent challenges of incomplete views and missing labels, common in real-world data due to uncertainties in data collection and manual annotation. These challenges restrict the capacity of the model to fully utilize the diverse semantic information of each sample, posing significant barriers to effective learning. Despite substantial scholarly efforts, many existing methods inadequately capture the depth of semantic information, focusing primarily on shallow feature extractions that fail to maintain semantic consistency. To address these shortcomings, we propose a novel Deep semantic structure-preserving (SSP) model that effectively tackles both incomplete views and missing labels. SSP innovatively incorporates a graph constraint learning (GCL) scheme to ensure the preservation of semantic structure throughout the feature extraction process across different views. Additionally, the SSP integrates a pseudo-labeling self-paced learning (PSL) strategy to address the often-overlooked issue of missing labels, enhancing the classification accuracy while preserving the distribution structure of data. The SSP model creates a unified framework that synergistically employs GCL and PSL to maintain the integrity of semantic structural information during both feature extraction and classification phases. Extensive evaluations across five real datasets demonstrate that the SSP method outperforms existing approaches, including lrMMC, MVL-IV, MvEL, iMSF, iMvWL, NAIML, and DD-IMvMLC-net. It effectively mitigates the impacts of data incompleteness and enhances semantic representation fidelity.
期刊介绍:
Complex & Intelligent Systems aims to provide a forum for presenting and discussing novel approaches, tools and techniques meant for attaining a cross-fertilization between the broad fields of complex systems, computational simulation, and intelligent analytics and visualization. The transdisciplinary research that the journal focuses on will expand the boundaries of our understanding by investigating the principles and processes that underlie many of the most profound problems facing society today.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


