{"title":"Fedisp: an incremental subgradient-proximal-based ring-type architecture for decentralized federated learning","authors":"Jianjun Huang, Zihao Rui, Li Kang","doi":"10.1007/s40747-023-01272-4","DOIUrl":null,"url":null,"abstract":"<p>Federated learning (FL) represents a promising distributed machine learning paradigm for resolving data isolation due to data privacy concerns. Nevertheless, most vanilla FL algorithms, which depend on a server, encounter the problem of reliability and a high communication burden in real cases. Decentralized federated learning (DFL) that does not follow the star topology faces the challenges of weight divergence and inferior communication efficiency. In this paper, a novel DFL framework called federated incremental subgradient-proximal (FedISP) is proposed that utilizes the incremental method to perform model updates to alleviate weight divergence. In our setup, multiple clients are distributed in a ring topology and communicate in a cyclic manner, which significantly mitigates the communication load. A convergence guarantee is given under the convex condition to demonstrate the impact of the learning rate on our algorithms, which further improves the performance of FedISP. Extensive experiments on benchmark datasets validate the effectiveness of the proposed approach in both independent and identically distributed (IID) and non-IID settings while illustrating the advantages of the FedISP algorithm in achieving model consensus and saving communication costs.</p>","PeriodicalId":10524,"journal":{"name":"Complex & Intelligent Systems","volume":"28 1","pages":""},"PeriodicalIF":5.0000,"publicationDate":"2023-11-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Complex & Intelligent Systems","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s40747-023-01272-4","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
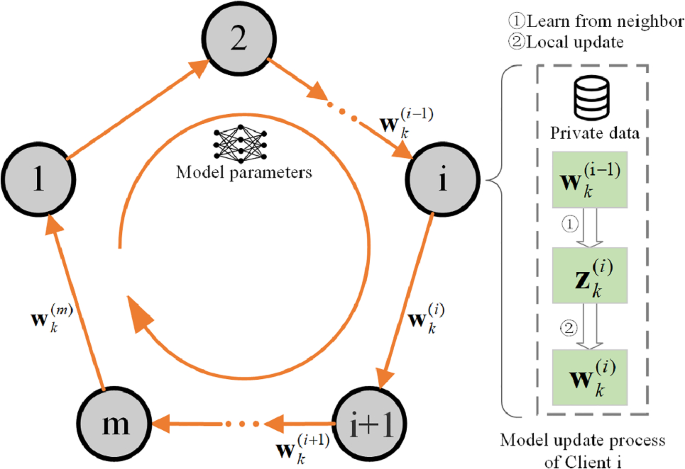
Federated learning (FL) represents a promising distributed machine learning paradigm for resolving data isolation due to data privacy concerns. Nevertheless, most vanilla FL algorithms, which depend on a server, encounter the problem of reliability and a high communication burden in real cases. Decentralized federated learning (DFL) that does not follow the star topology faces the challenges of weight divergence and inferior communication efficiency. In this paper, a novel DFL framework called federated incremental subgradient-proximal (FedISP) is proposed that utilizes the incremental method to perform model updates to alleviate weight divergence. In our setup, multiple clients are distributed in a ring topology and communicate in a cyclic manner, which significantly mitigates the communication load. A convergence guarantee is given under the convex condition to demonstrate the impact of the learning rate on our algorithms, which further improves the performance of FedISP. Extensive experiments on benchmark datasets validate the effectiveness of the proposed approach in both independent and identically distributed (IID) and non-IID settings while illustrating the advantages of the FedISP algorithm in achieving model consensus and saving communication costs.
期刊介绍:
Complex & Intelligent Systems aims to provide a forum for presenting and discussing novel approaches, tools and techniques meant for attaining a cross-fertilization between the broad fields of complex systems, computational simulation, and intelligent analytics and visualization. The transdisciplinary research that the journal focuses on will expand the boundaries of our understanding by investigating the principles and processes that underlie many of the most profound problems facing society today.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


