{"title":"一种用于恶意统一资源定位器(URL)的智能识别和分类系统。","authors":"Qasem Abu Al-Haija, Mustafa Al-Fayoumi","doi":"10.1007/s00521-023-08592-z","DOIUrl":null,"url":null,"abstract":"<p><p>Uniform Resource Locator (URL) is a unique identifier composed of protocol and domain name used to locate and retrieve a resource on the Internet. Like any Internet service, URLs (also called websites) are vulnerable to compromise by attackers to develop Malicious URLs that can exploit/devastate the user's information and resources. Malicious URLs are usually designed with the intention of promoting cyber-attacks such as spam, phishing, malware, and defacement. These websites usually require action on the user's side and can reach users across emails, text messages, pop-ups, or devious advertisements. They have a potential impact that can reach, in some cases, to compromise the machine or network of the user, especially those arriving by email. Therefore, developing systems to detect malicious URLs is of great interest nowadays. This paper proposes a high-performance machine learning-based detection system to identify Malicious URLs. The proposed system provides two layers of detection. Firstly, we identify the URLs as either benign or malware using a binary classifier. Secondly, we classify the URL classes based on their feature into five classes: benign, spam, phishing, malware, and defacement. Specifically, we report on four ensemble learning approaches, viz. the ensemble of bagging trees (En_Bag) approach, the ensemble of k-nearest neighbor (En_kNN) approach, and the ensemble of boosted decision trees (En_Bos) approach, and the ensemble of subspace discriminator (En_Dsc) approach. The developed approaches have been evaluated on an inclusive and contemporary dataset for uniform resource locators (ISCX-URL2016). ISCX-URL2016 provides a lightweight dataset for detecting and categorizing malicious URLs according to their attack type and lexical analysis. Conventional machine learning evaluation measurements are used to evaluate the detection accuracy, precision, recall, F Score, and detection time. Our experiential assessment indicates that the ensemble of bagging trees (En_Bag) approach provides better performance rates than other ensemble methods. Alternatively, the ensemble of the k-nearest neighbor (En_kNN) approach provides the highest inference speed. We also contrast our En_Bag model with state-of-the-art solutions and show its superiority in binary classification and multi-classification with accuracy rates of 99.3% and 97.92%, respectively.</p>","PeriodicalId":49766,"journal":{"name":"Neural Computing & Applications","volume":" ","pages":"1-17"},"PeriodicalIF":4.5000,"publicationDate":"2023-04-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10117275/pdf/","citationCount":"5","resultStr":"{\"title\":\"An intelligent identification and classification system for malicious uniform resource locators (URLs).\",\"authors\":\"Qasem Abu Al-Haija, Mustafa Al-Fayoumi\",\"doi\":\"10.1007/s00521-023-08592-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Uniform Resource Locator (URL) is a unique identifier composed of protocol and domain name used to locate and retrieve a resource on the Internet. Like any Internet service, URLs (also called websites) are vulnerable to compromise by attackers to develop Malicious URLs that can exploit/devastate the user's information and resources. Malicious URLs are usually designed with the intention of promoting cyber-attacks such as spam, phishing, malware, and defacement. These websites usually require action on the user's side and can reach users across emails, text messages, pop-ups, or devious advertisements. They have a potential impact that can reach, in some cases, to compromise the machine or network of the user, especially those arriving by email. Therefore, developing systems to detect malicious URLs is of great interest nowadays. This paper proposes a high-performance machine learning-based detection system to identify Malicious URLs. The proposed system provides two layers of detection. Firstly, we identify the URLs as either benign or malware using a binary classifier. Secondly, we classify the URL classes based on their feature into five classes: benign, spam, phishing, malware, and defacement. Specifically, we report on four ensemble learning approaches, viz. the ensemble of bagging trees (En_Bag) approach, the ensemble of k-nearest neighbor (En_kNN) approach, and the ensemble of boosted decision trees (En_Bos) approach, and the ensemble of subspace discriminator (En_Dsc) approach. The developed approaches have been evaluated on an inclusive and contemporary dataset for uniform resource locators (ISCX-URL2016). ISCX-URL2016 provides a lightweight dataset for detecting and categorizing malicious URLs according to their attack type and lexical analysis. Conventional machine learning evaluation measurements are used to evaluate the detection accuracy, precision, recall, F Score, and detection time. Our experiential assessment indicates that the ensemble of bagging trees (En_Bag) approach provides better performance rates than other ensemble methods. Alternatively, the ensemble of the k-nearest neighbor (En_kNN) approach provides the highest inference speed. We also contrast our En_Bag model with state-of-the-art solutions and show its superiority in binary classification and multi-classification with accuracy rates of 99.3% and 97.92%, respectively.</p>\",\"PeriodicalId\":49766,\"journal\":{\"name\":\"Neural Computing & Applications\",\"volume\":\" \",\"pages\":\"1-17\"},\"PeriodicalIF\":4.5000,\"publicationDate\":\"2023-04-20\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10117275/pdf/\",\"citationCount\":\"5\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Neural Computing & Applications\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s00521-023-08592-z\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Neural Computing & Applications","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00521-023-08592-z","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
An intelligent identification and classification system for malicious uniform resource locators (URLs).
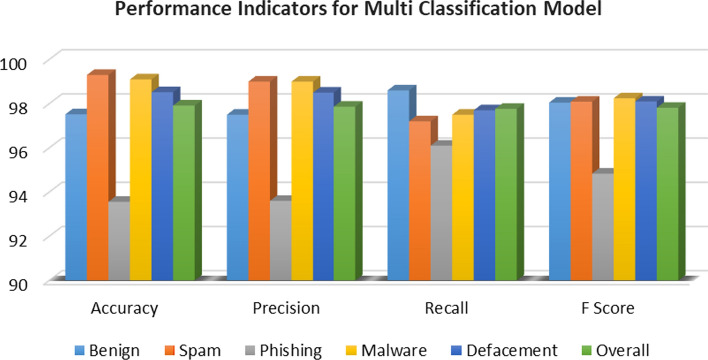
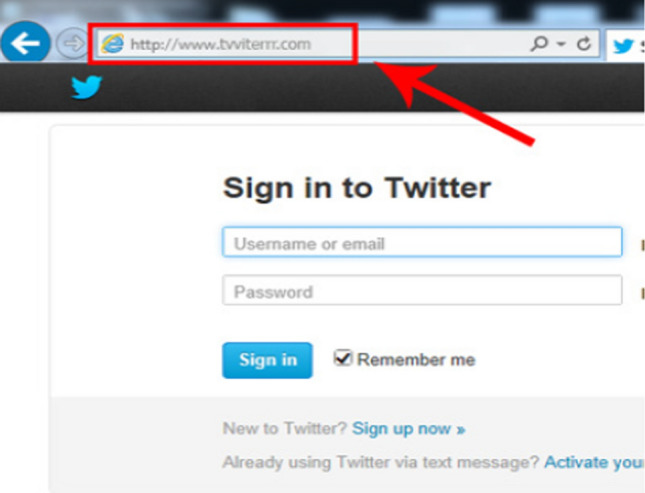
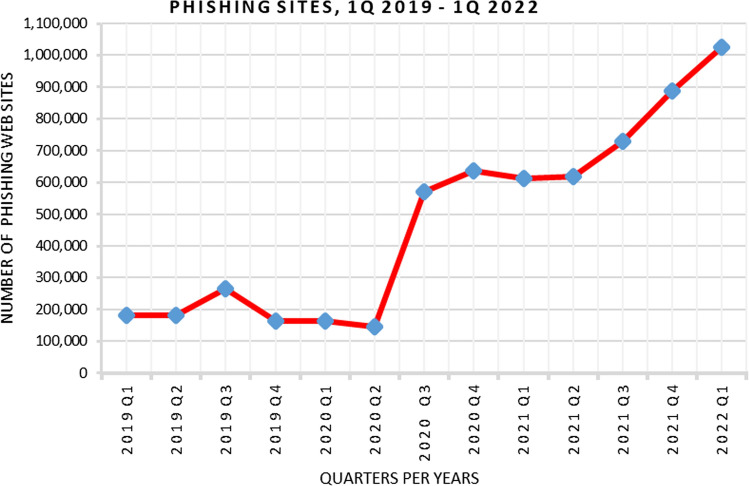
Uniform Resource Locator (URL) is a unique identifier composed of protocol and domain name used to locate and retrieve a resource on the Internet. Like any Internet service, URLs (also called websites) are vulnerable to compromise by attackers to develop Malicious URLs that can exploit/devastate the user's information and resources. Malicious URLs are usually designed with the intention of promoting cyber-attacks such as spam, phishing, malware, and defacement. These websites usually require action on the user's side and can reach users across emails, text messages, pop-ups, or devious advertisements. They have a potential impact that can reach, in some cases, to compromise the machine or network of the user, especially those arriving by email. Therefore, developing systems to detect malicious URLs is of great interest nowadays. This paper proposes a high-performance machine learning-based detection system to identify Malicious URLs. The proposed system provides two layers of detection. Firstly, we identify the URLs as either benign or malware using a binary classifier. Secondly, we classify the URL classes based on their feature into five classes: benign, spam, phishing, malware, and defacement. Specifically, we report on four ensemble learning approaches, viz. the ensemble of bagging trees (En_Bag) approach, the ensemble of k-nearest neighbor (En_kNN) approach, and the ensemble of boosted decision trees (En_Bos) approach, and the ensemble of subspace discriminator (En_Dsc) approach. The developed approaches have been evaluated on an inclusive and contemporary dataset for uniform resource locators (ISCX-URL2016). ISCX-URL2016 provides a lightweight dataset for detecting and categorizing malicious URLs according to their attack type and lexical analysis. Conventional machine learning evaluation measurements are used to evaluate the detection accuracy, precision, recall, F Score, and detection time. Our experiential assessment indicates that the ensemble of bagging trees (En_Bag) approach provides better performance rates than other ensemble methods. Alternatively, the ensemble of the k-nearest neighbor (En_kNN) approach provides the highest inference speed. We also contrast our En_Bag model with state-of-the-art solutions and show its superiority in binary classification and multi-classification with accuracy rates of 99.3% and 97.92%, respectively.
期刊介绍:
Neural Computing & Applications is an international journal which publishes original research and other information in the field of practical applications of neural computing and related techniques such as genetic algorithms, fuzzy logic and neuro-fuzzy systems.
All items relevant to building practical systems are within its scope, including but not limited to:
-adaptive computing-
algorithms-
applicable neural networks theory-
applied statistics-
architectures-
artificial intelligence-
benchmarks-
case histories of innovative applications-
fuzzy logic-
genetic algorithms-
hardware implementations-
hybrid intelligent systems-
intelligent agents-
intelligent control systems-
intelligent diagnostics-
intelligent forecasting-
machine learning-
neural networks-
neuro-fuzzy systems-
pattern recognition-
performance measures-
self-learning systems-
software simulations-
supervised and unsupervised learning methods-
system engineering and integration.
Featured contributions fall into several categories: Original Articles, Review Articles, Book Reviews and Announcements.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


