Di Fu, Fares Abawi, Hugo Carneiro, Matthias Kerzel, Ziwei Chen, Erik Strahl, Xun Liu, Stefan Wermter
{"title":"经过训练的仿人机器人可以进行类似人类的跨模态社会关注和冲突解决。","authors":"Di Fu, Fares Abawi, Hugo Carneiro, Matthias Kerzel, Ziwei Chen, Erik Strahl, Xun Liu, Stefan Wermter","doi":"10.1007/s12369-023-00993-3","DOIUrl":null,"url":null,"abstract":"<p><p>To enhance human-robot social interaction, it is essential for robots to process multiple social cues in a complex real-world environment. However, incongruency of input information across modalities is inevitable and could be challenging for robots to process. To tackle this challenge, our study adopted the neurorobotic paradigm of crossmodal conflict resolution to make a robot express human-like social attention. A behavioural experiment was conducted on 37 participants for the human study. We designed a round-table meeting scenario with three animated avatars to improve ecological validity. Each avatar wore a medical mask to obscure the facial cues of the nose, mouth, and jaw. The central avatar shifted its eye gaze while the peripheral avatars generated sound. Gaze direction and sound locations were either spatially congruent or incongruent. We observed that the central avatar's dynamic gaze could trigger crossmodal social attention responses. In particular, human performance was better under the congruent audio-visual condition than the incongruent condition. Our saliency prediction model was trained to detect social cues, predict audio-visual saliency, and attend selectively for the robot study. After mounting the trained model on the iCub, the robot was exposed to laboratory conditions similar to the human experiment. While the human performance was overall superior, our trained model demonstrated that it could replicate attention responses similar to humans.</p>","PeriodicalId":14361,"journal":{"name":"International Journal of Social Robotics","volume":" ","pages":"1-16"},"PeriodicalIF":3.8000,"publicationDate":"2023-04-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10067521/pdf/","citationCount":"2","resultStr":"{\"title\":\"A Trained Humanoid Robot can Perform Human-Like Crossmodal Social Attention and Conflict Resolution.\",\"authors\":\"Di Fu, Fares Abawi, Hugo Carneiro, Matthias Kerzel, Ziwei Chen, Erik Strahl, Xun Liu, Stefan Wermter\",\"doi\":\"10.1007/s12369-023-00993-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>To enhance human-robot social interaction, it is essential for robots to process multiple social cues in a complex real-world environment. However, incongruency of input information across modalities is inevitable and could be challenging for robots to process. To tackle this challenge, our study adopted the neurorobotic paradigm of crossmodal conflict resolution to make a robot express human-like social attention. A behavioural experiment was conducted on 37 participants for the human study. We designed a round-table meeting scenario with three animated avatars to improve ecological validity. Each avatar wore a medical mask to obscure the facial cues of the nose, mouth, and jaw. The central avatar shifted its eye gaze while the peripheral avatars generated sound. Gaze direction and sound locations were either spatially congruent or incongruent. We observed that the central avatar's dynamic gaze could trigger crossmodal social attention responses. In particular, human performance was better under the congruent audio-visual condition than the incongruent condition. Our saliency prediction model was trained to detect social cues, predict audio-visual saliency, and attend selectively for the robot study. After mounting the trained model on the iCub, the robot was exposed to laboratory conditions similar to the human experiment. While the human performance was overall superior, our trained model demonstrated that it could replicate attention responses similar to humans.</p>\",\"PeriodicalId\":14361,\"journal\":{\"name\":\"International Journal of Social Robotics\",\"volume\":\" \",\"pages\":\"1-16\"},\"PeriodicalIF\":3.8000,\"publicationDate\":\"2023-04-02\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10067521/pdf/\",\"citationCount\":\"2\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"International Journal of Social Robotics\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s12369-023-00993-3\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"ROBOTICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Social Robotics","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s12369-023-00993-3","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"ROBOTICS","Score":null,"Total":0}
A Trained Humanoid Robot can Perform Human-Like Crossmodal Social Attention and Conflict Resolution.
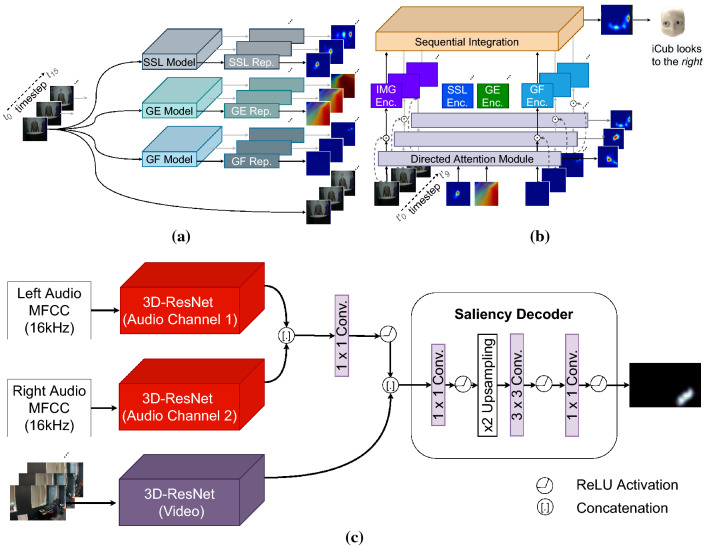
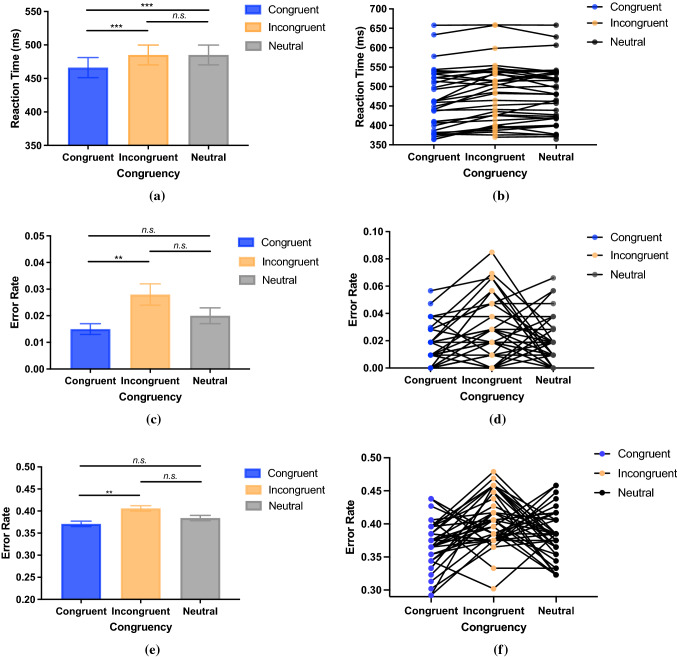
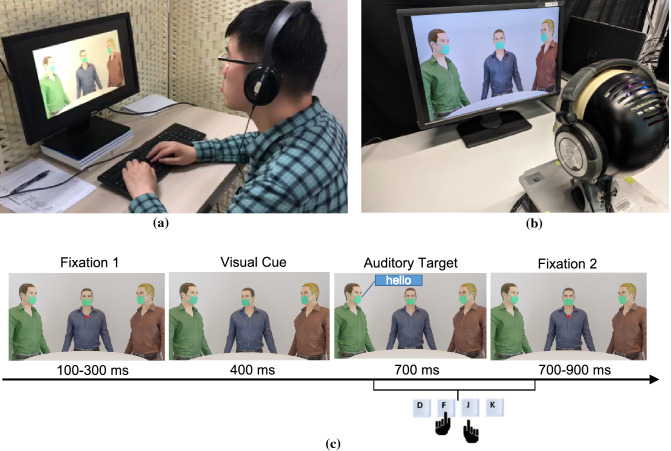
To enhance human-robot social interaction, it is essential for robots to process multiple social cues in a complex real-world environment. However, incongruency of input information across modalities is inevitable and could be challenging for robots to process. To tackle this challenge, our study adopted the neurorobotic paradigm of crossmodal conflict resolution to make a robot express human-like social attention. A behavioural experiment was conducted on 37 participants for the human study. We designed a round-table meeting scenario with three animated avatars to improve ecological validity. Each avatar wore a medical mask to obscure the facial cues of the nose, mouth, and jaw. The central avatar shifted its eye gaze while the peripheral avatars generated sound. Gaze direction and sound locations were either spatially congruent or incongruent. We observed that the central avatar's dynamic gaze could trigger crossmodal social attention responses. In particular, human performance was better under the congruent audio-visual condition than the incongruent condition. Our saliency prediction model was trained to detect social cues, predict audio-visual saliency, and attend selectively for the robot study. After mounting the trained model on the iCub, the robot was exposed to laboratory conditions similar to the human experiment. While the human performance was overall superior, our trained model demonstrated that it could replicate attention responses similar to humans.
期刊介绍:
Social Robotics is the study of robots that are able to interact and communicate among themselves, with humans, and with the environment, within the social and cultural structure attached to its role. The journal covers a broad spectrum of topics related to the latest technologies, new research results and developments in the area of social robotics on all levels, from developments in core enabling technologies to system integration, aesthetic design, applications and social implications. It provides a platform for like-minded researchers to present their findings and latest developments in social robotics, covering relevant advances in engineering, computing, arts and social sciences.
The journal publishes original, peer reviewed articles and contributions on innovative ideas and concepts, new discoveries and improvements, as well as novel applications, by leading researchers and developers regarding the latest fundamental advances in the core technologies that form the backbone of social robotics, distinguished developmental projects in the area, as well as seminal works in aesthetic design, ethics and philosophy, studies on social impact and influence, pertaining to social robotics.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


