Zi-Xin Zou , Shi-Sheng Huang , Tai-Jiang Mu , Yu-Ping Wang
{"title":"目标融合:具有神经目标先验的精确目标级SLAM","authors":"Zi-Xin Zou , Shi-Sheng Huang , Tai-Jiang Mu , Yu-Ping Wang","doi":"10.1016/j.gmod.2022.101165","DOIUrl":null,"url":null,"abstract":"<div><p><span>Previous object-level Simultaneous Localization and Mapping (SLAM) approaches still fail to create high quality object-oriented 3D map in an efficient way. The main challenges come from how to represent the object shape </span><em>effectively</em> and how to apply such object representation to accurate <em>online</em> camera tracking <em>efficiently</em>. In this paper, we provide <em>ObjectFusion</em> as a novel <em>object</em><span>-level SLAM in static scenes which efficiently creates object-oriented 3D map with high-quality object reconstruction, by leveraging neural object priors. We propose a neural object representation with only a single encoder–decoder network to effectively express the object shape across various categories, which benefits high quality reconstruction of object instance. More importantly, we propose to </span><em>convert</em> such neural object representation as precise measurements to jointly optimize the <em>object shape</em>, <em>object pose</em> and <em>camera pose</em><span> for the final accurate 3D object reconstruction. With extensive evaluations on synthetic and real-world RGB-D datasets, we show that our ObjectFusion outperforms previous approaches, with better object reconstruction quality, using much less memory footprint, and in a more efficient way, especially at the </span><em>object</em> level.</p></div>","PeriodicalId":55083,"journal":{"name":"Graphical Models","volume":"123 ","pages":"Article 101165"},"PeriodicalIF":2.5000,"publicationDate":"2022-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"5","resultStr":"{\"title\":\"ObjectFusion: Accurate object-level SLAM with neural object priors\",\"authors\":\"Zi-Xin Zou , Shi-Sheng Huang , Tai-Jiang Mu , Yu-Ping Wang\",\"doi\":\"10.1016/j.gmod.2022.101165\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p><span>Previous object-level Simultaneous Localization and Mapping (SLAM) approaches still fail to create high quality object-oriented 3D map in an efficient way. The main challenges come from how to represent the object shape </span><em>effectively</em> and how to apply such object representation to accurate <em>online</em> camera tracking <em>efficiently</em>. In this paper, we provide <em>ObjectFusion</em> as a novel <em>object</em><span>-level SLAM in static scenes which efficiently creates object-oriented 3D map with high-quality object reconstruction, by leveraging neural object priors. We propose a neural object representation with only a single encoder–decoder network to effectively express the object shape across various categories, which benefits high quality reconstruction of object instance. More importantly, we propose to </span><em>convert</em> such neural object representation as precise measurements to jointly optimize the <em>object shape</em>, <em>object pose</em> and <em>camera pose</em><span> for the final accurate 3D object reconstruction. With extensive evaluations on synthetic and real-world RGB-D datasets, we show that our ObjectFusion outperforms previous approaches, with better object reconstruction quality, using much less memory footprint, and in a more efficient way, especially at the </span><em>object</em> level.</p></div>\",\"PeriodicalId\":55083,\"journal\":{\"name\":\"Graphical Models\",\"volume\":\"123 \",\"pages\":\"Article 101165\"},\"PeriodicalIF\":2.5000,\"publicationDate\":\"2022-09-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"5\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Graphical Models\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1524070322000418\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Graphical Models","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1524070322000418","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
ObjectFusion: Accurate object-level SLAM with neural object priors
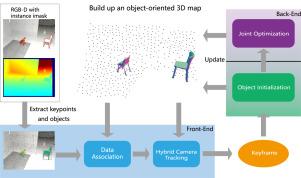
Previous object-level Simultaneous Localization and Mapping (SLAM) approaches still fail to create high quality object-oriented 3D map in an efficient way. The main challenges come from how to represent the object shape effectively and how to apply such object representation to accurate online camera tracking efficiently. In this paper, we provide ObjectFusion as a novel object-level SLAM in static scenes which efficiently creates object-oriented 3D map with high-quality object reconstruction, by leveraging neural object priors. We propose a neural object representation with only a single encoder–decoder network to effectively express the object shape across various categories, which benefits high quality reconstruction of object instance. More importantly, we propose to convert such neural object representation as precise measurements to jointly optimize the object shape, object pose and camera pose for the final accurate 3D object reconstruction. With extensive evaluations on synthetic and real-world RGB-D datasets, we show that our ObjectFusion outperforms previous approaches, with better object reconstruction quality, using much less memory footprint, and in a more efficient way, especially at the object level.
期刊介绍:
Graphical Models is recognized internationally as a highly rated, top tier journal and is focused on the creation, geometric processing, animation, and visualization of graphical models and on their applications in engineering, science, culture, and entertainment. GMOD provides its readers with thoroughly reviewed and carefully selected papers that disseminate exciting innovations, that teach rigorous theoretical foundations, that propose robust and efficient solutions, or that describe ambitious systems or applications in a variety of topics.
We invite papers in five categories: research (contributions of novel theoretical or practical approaches or solutions), survey (opinionated views of the state-of-the-art and challenges in a specific topic), system (the architecture and implementation details of an innovative architecture for a complete system that supports model/animation design, acquisition, analysis, visualization?), application (description of a novel application of know techniques and evaluation of its impact), or lecture (an elegant and inspiring perspective on previously published results that clarifies them and teaches them in a new way).
GMOD offers its authors an accelerated review, feedback from experts in the field, immediate online publication of accepted papers, no restriction on color and length (when justified by the content) in the online version, and a broad promotion of published papers. A prestigious group of editors selected from among the premier international researchers in their fields oversees the review process.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


