回顾自动化时间序列预测管道
IF 11.7
2区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
Wiley Interdisciplinary Reviews-Data Mining and Knowledge Discovery
Pub Date : 2022-02-03
DOI:10.1002/widm.1475
引用次数: 19
摘要
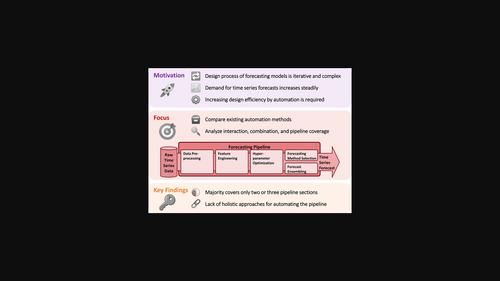
时间序列预测是不同领域(如能源系统和经济)中各种用例的基础。为特定用例创建预测模型需要一个迭代和复杂的设计过程。典型的设计过程包括五个部分(1)数据预处理,(2)特征工程,(3)超参数优化,(4)预测方法选择,(5)预测集成,通常以管道结构组织。一个有希望的方法来处理时间序列预测不断增长的需求是自动化这个设计过程。因此,本文回顾了关于自动化时间序列预测管道的现有文献,并分析了预测模型的设计过程目前是如何自动化的。因此,我们在单个预测管道中考虑自动机器学习(AutoML)和自动统计预测方法。为此,我们首先介绍并比较每个管道部分的已确定的自动化方法。其次,我们分析了这些自动化方法的相互作用、组合和五个管道段的覆盖范围。对于两者,我们都讨论了有助于自动化设计过程的文献,确定问题,给出建议,并建议未来的研究。这篇综述显示,大多数综述文献只涵盖了五个管道部分中的两个或三个。我们得出结论,未来的研究必须全面考虑预测管道的自动化,以实现时间序列预测的大规模应用。本文章由计算机程序翻译,如有差异,请以英文原文为准。
Review of automated time series forecasting pipelines
Time series forecasting is fundamental for various use cases in different domains such as energy systems and economics. Creating a forecasting model for a specific use case requires an iterative and complex design process. The typical design process includes five sections (1) data preprocessing, (2) feature engineering, (3) hyperparameter optimization, (4) forecasting method selection, and (5) forecast ensembling, which are commonly organized in a pipeline structure. One promising approach to handle the ever‐growing demand for time series forecasts is automating this design process. The article, thus, reviews existing literature on automated time series forecasting pipelines and analyzes how the design process of forecasting models is currently automated. Thereby, we consider both automated machine learning (AutoML) and automated statistical forecasting methods in a single forecasting pipeline. For this purpose, we first present and compare the identified automation methods for each pipeline section. Second, we analyze these automation methods regarding their interaction, combination, and coverage of the five pipeline sections. For both, we discuss the reviewed literature that contributes toward automating the design process, identify problems, give recommendations, and suggest future research. This review reveals that the majority of the reviewed literature only covers two or three of the five pipeline sections. We conclude that future research has to holistically consider the automation of the forecasting pipeline to enable the large‐scale application of time series forecasting.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Wiley Interdisciplinary Reviews-Data Mining and Knowledge Discovery
COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE-COMPUTER SCIENCE, THEORY & METHODS
CiteScore
22.70
自引率
2.60%
发文量
39
审稿时长
>12 weeks
期刊介绍:
The goals of Wiley Interdisciplinary Reviews-Data Mining and Knowledge Discovery (WIREs DMKD) are multifaceted. Firstly, the journal aims to provide a comprehensive overview of the current state of data mining and knowledge discovery by featuring ongoing reviews authored by leading researchers. Secondly, it seeks to highlight the interdisciplinary nature of the field by presenting articles from diverse perspectives, covering various application areas such as technology, business, healthcare, education, government, society, and culture. Thirdly, WIREs DMKD endeavors to keep pace with the rapid advancements in data mining and knowledge discovery through regular content updates. Lastly, the journal strives to promote active engagement in the field by presenting its accomplishments and challenges in an accessible manner to a broad audience. The content of WIREs DMKD is intended to benefit upper-level undergraduate and postgraduate students, teaching and research professors in academic programs, as well as scientists and research managers in industry.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


