Fei Cheng, Zhimin Zhou, Fan Wu, Huizhen Li, Zhiqiang Yu, Xiangying Zeng and Jing You*,
{"title":"在数据贫乏的情况下,数据驱动的终点选择:页岩气返排和产出水的生物测定设计","authors":"Fei Cheng, Zhimin Zhou, Fan Wu, Huizhen Li, Zhiqiang Yu, Xiangying Zeng and Jing You*, ","doi":"10.1021/acs.estlett.2c00648","DOIUrl":null,"url":null,"abstract":"<p >Big data approaches have greatly improved scientific decision making, but they are highly dependent on the availability of data, impeding their use in data-poor scenarios. In addition to data abundance, enhancing data diversity is likewise a way to access knowledge. Herein, we propose a data-driven method for toxicity endpoint selection when directly relevant data are deficient, and shale gas exploitation sites were used as an example scenario. From the 1173 substances in the U.S. Environmental Protection Agency’s HFList, the most concerning endpoints in zebrafish embryo toxicity tests (FET) were inferred using a newly developed relational database (RDB) strategy that integrated chemical, high-throughput screening (HTS) bioactivity, genome, and FET endpoint information. This RDB strategy based on text mining and data fusion approaches enabled the integration of 255 bioactive contaminants, 955 HTS bioassays with known modes of action (MoAs), 214 gene ontologies, 65 pathways, and 27 phenotypic data and predicted measurement endpoints within 10 MoAs for shale gas pollution. This data-driven approach was further validated using zebrafish FET and transcriptomic sequencing with field-collected samples and achieved 89% and 97% accuracy for the predictive ontologies and pathways, respectively. This highlighted the applicability of RDB-based data-driven strategies for predicting toxicity endpoints from a priori knowledge of contaminants by improving data diversity.</p>","PeriodicalId":37,"journal":{"name":"Environmental Science & Technology Letters Environ.","volume":"9 12","pages":"1074–1080"},"PeriodicalIF":8.8000,"publicationDate":"2022-11-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"2","resultStr":"{\"title\":\"Data-Driven Endpoint Selection in Data-Poor Scenarios: Bioassay Design for Shale Gas Flowback and Produced Waters\",\"authors\":\"Fei Cheng, Zhimin Zhou, Fan Wu, Huizhen Li, Zhiqiang Yu, Xiangying Zeng and Jing You*, \",\"doi\":\"10.1021/acs.estlett.2c00648\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p >Big data approaches have greatly improved scientific decision making, but they are highly dependent on the availability of data, impeding their use in data-poor scenarios. In addition to data abundance, enhancing data diversity is likewise a way to access knowledge. Herein, we propose a data-driven method for toxicity endpoint selection when directly relevant data are deficient, and shale gas exploitation sites were used as an example scenario. From the 1173 substances in the U.S. Environmental Protection Agency’s HFList, the most concerning endpoints in zebrafish embryo toxicity tests (FET) were inferred using a newly developed relational database (RDB) strategy that integrated chemical, high-throughput screening (HTS) bioactivity, genome, and FET endpoint information. This RDB strategy based on text mining and data fusion approaches enabled the integration of 255 bioactive contaminants, 955 HTS bioassays with known modes of action (MoAs), 214 gene ontologies, 65 pathways, and 27 phenotypic data and predicted measurement endpoints within 10 MoAs for shale gas pollution. This data-driven approach was further validated using zebrafish FET and transcriptomic sequencing with field-collected samples and achieved 89% and 97% accuracy for the predictive ontologies and pathways, respectively. This highlighted the applicability of RDB-based data-driven strategies for predicting toxicity endpoints from a priori knowledge of contaminants by improving data diversity.</p>\",\"PeriodicalId\":37,\"journal\":{\"name\":\"Environmental Science & Technology Letters Environ.\",\"volume\":\"9 12\",\"pages\":\"1074–1080\"},\"PeriodicalIF\":8.8000,\"publicationDate\":\"2022-11-03\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"2\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Environmental Science & Technology Letters Environ.\",\"FirstCategoryId\":\"1\",\"ListUrlMain\":\"https://pubs.acs.org/doi/10.1021/acs.estlett.2c00648\",\"RegionNum\":2,\"RegionCategory\":\"环境科学与生态学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"ENGINEERING, ENVIRONMENTAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Environmental Science & Technology Letters Environ.","FirstCategoryId":"1","ListUrlMain":"https://pubs.acs.org/doi/10.1021/acs.estlett.2c00648","RegionNum":2,"RegionCategory":"环境科学与生态学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"ENGINEERING, ENVIRONMENTAL","Score":null,"Total":0}
Data-Driven Endpoint Selection in Data-Poor Scenarios: Bioassay Design for Shale Gas Flowback and Produced Waters
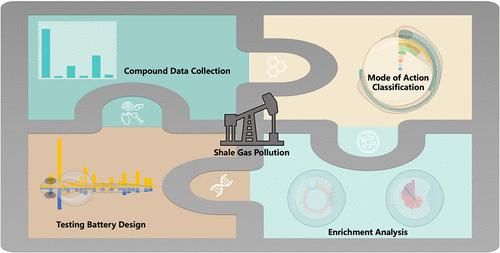
Big data approaches have greatly improved scientific decision making, but they are highly dependent on the availability of data, impeding their use in data-poor scenarios. In addition to data abundance, enhancing data diversity is likewise a way to access knowledge. Herein, we propose a data-driven method for toxicity endpoint selection when directly relevant data are deficient, and shale gas exploitation sites were used as an example scenario. From the 1173 substances in the U.S. Environmental Protection Agency’s HFList, the most concerning endpoints in zebrafish embryo toxicity tests (FET) were inferred using a newly developed relational database (RDB) strategy that integrated chemical, high-throughput screening (HTS) bioactivity, genome, and FET endpoint information. This RDB strategy based on text mining and data fusion approaches enabled the integration of 255 bioactive contaminants, 955 HTS bioassays with known modes of action (MoAs), 214 gene ontologies, 65 pathways, and 27 phenotypic data and predicted measurement endpoints within 10 MoAs for shale gas pollution. This data-driven approach was further validated using zebrafish FET and transcriptomic sequencing with field-collected samples and achieved 89% and 97% accuracy for the predictive ontologies and pathways, respectively. This highlighted the applicability of RDB-based data-driven strategies for predicting toxicity endpoints from a priori knowledge of contaminants by improving data diversity.
期刊介绍:
Environmental Science & Technology Letters serves as an international forum for brief communications on experimental or theoretical results of exceptional timeliness in all aspects of environmental science, both pure and applied. Published as soon as accepted, these communications are summarized in monthly issues. Additionally, the journal features short reviews on emerging topics in environmental science and technology.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


