大图中的子图挖掘:综述
IF 11.7
2区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
Wiley Interdisciplinary Reviews-Data Mining and Knowledge Discovery
Pub Date : 2022-03-08
DOI:10.1002/widm.1454
引用次数: 8
摘要
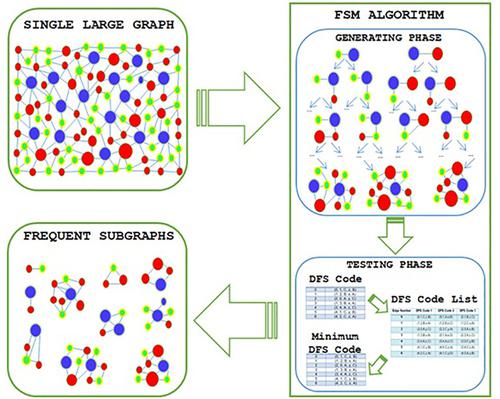
在各种研究和应用领域中,大图形经常被用来对复杂系统进行模拟和建模。由于其重要性,单个大图的频繁子图挖掘(FSM)是一个非常重要的问题,近年来吸引了众多研究者,并在各种研究和应用任务中发挥了重要作用。FSM的目标是找到在一个大图中出现次数大于或等于给定频率阈值的所有子图。在最近的应用中,底层图是非常大的,例如社交网络,因此从单个大图中进行FSM的算法已经迅速发展,但它们都具有NP - hard(不确定多项式时间)复杂性,并且具有巨大的搜索空间,因此仍然需要大量的时间和内存来恢复和处理。在本文中,我们概述了FSM的问题,FSM的重要阶段,FSM的主要组,以及许多现代应用的算法。这包括许多实际应用,是未来许多研究的基本前提。本文章由计算机程序翻译,如有差异,请以英文原文为准。
Subgraph mining in a large graph: A review
Large graphs are often used to simulate and model complex systems in various research and application fields. Because of its importance, frequent subgraph mining (FSM) in single large graphs is a vital issue, and recently, it has attracted numerous researchers, and played an important role in various tasks for both research and application purposes. FSM is aimed at finding all subgraphs whose number of appearances in a large graph is greater than or equal to a given frequency threshold. In most recent applications, the underlying graphs are very large, such as social networks, and therefore algorithms for FSM from a single large graph have been rapidly developed, but all of them have NP‐hard (nondeterministic polynomial time) complexity with huge search spaces, and therefore still need a lot of time and memory to restore and process. In this article, we present an overview of problems of FSM, important phases in FSM, main groups of FSM, as well as surveying many modern applied algorithms. This includes many practical applications and is a fundamental premise for many studies in the future.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Wiley Interdisciplinary Reviews-Data Mining and Knowledge Discovery
COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE-COMPUTER SCIENCE, THEORY & METHODS
CiteScore
22.70
自引率
2.60%
发文量
39
审稿时长
>12 weeks
期刊介绍:
The goals of Wiley Interdisciplinary Reviews-Data Mining and Knowledge Discovery (WIREs DMKD) are multifaceted. Firstly, the journal aims to provide a comprehensive overview of the current state of data mining and knowledge discovery by featuring ongoing reviews authored by leading researchers. Secondly, it seeks to highlight the interdisciplinary nature of the field by presenting articles from diverse perspectives, covering various application areas such as technology, business, healthcare, education, government, society, and culture. Thirdly, WIREs DMKD endeavors to keep pace with the rapid advancements in data mining and knowledge discovery through regular content updates. Lastly, the journal strives to promote active engagement in the field by presenting its accomplishments and challenges in an accessible manner to a broad audience. The content of WIREs DMKD is intended to benefit upper-level undergraduate and postgraduate students, teaching and research professors in academic programs, as well as scientists and research managers in industry.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


