S. Yaser Samadi, L. Billard, Jiin-Huarng Guo, Wei Xu
{"title":"双变量区间值模型参数的 MLE","authors":"S. Yaser Samadi, L. Billard, Jiin-Huarng Guo, Wei Xu","doi":"10.1007/s11634-023-00546-6","DOIUrl":null,"url":null,"abstract":"<div><p>With contemporary data sets becoming too large to analyze the data directly, various forms of aggregated data are becoming common. The original individual data are points, but after aggregation the observations are interval-valued (e.g.). While some researchers simply analyze the set of averages of the observations by aggregated class, it is easily established that approach ignores much of the information in the original data set. The initial theoretical work for interval-valued data was that of Le-Rademacher and Billard (J Stat Plan Infer 141:1593–1602, 2011), but those results were limited to estimation of the mean and variance of a single variable only. This article seeks to redress the limitation of their work by deriving the maximum likelihood estimator for the all important covariance statistic, a basic requirement for numerous methodologies, such as regression, principal components, and canonical analyses. Asymptotic properties of the proposed estimators are established. The Le-Rademacher and Billard results emerge as special cases of our wider derivations.</p></div>","PeriodicalId":49270,"journal":{"name":"Advances in Data Analysis and Classification","volume":"18 4","pages":"827 - 850"},"PeriodicalIF":1.3000,"publicationDate":"2023-06-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"MLE for the parameters of bivariate interval-valued model\",\"authors\":\"S. Yaser Samadi, L. Billard, Jiin-Huarng Guo, Wei Xu\",\"doi\":\"10.1007/s11634-023-00546-6\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>With contemporary data sets becoming too large to analyze the data directly, various forms of aggregated data are becoming common. The original individual data are points, but after aggregation the observations are interval-valued (e.g.). While some researchers simply analyze the set of averages of the observations by aggregated class, it is easily established that approach ignores much of the information in the original data set. The initial theoretical work for interval-valued data was that of Le-Rademacher and Billard (J Stat Plan Infer 141:1593–1602, 2011), but those results were limited to estimation of the mean and variance of a single variable only. This article seeks to redress the limitation of their work by deriving the maximum likelihood estimator for the all important covariance statistic, a basic requirement for numerous methodologies, such as regression, principal components, and canonical analyses. Asymptotic properties of the proposed estimators are established. The Le-Rademacher and Billard results emerge as special cases of our wider derivations.</p></div>\",\"PeriodicalId\":49270,\"journal\":{\"name\":\"Advances in Data Analysis and Classification\",\"volume\":\"18 4\",\"pages\":\"827 - 850\"},\"PeriodicalIF\":1.3000,\"publicationDate\":\"2023-06-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Advances in Data Analysis and Classification\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s11634-023-00546-6\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"STATISTICS & PROBABILITY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Advances in Data Analysis and Classification","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s11634-023-00546-6","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"STATISTICS & PROBABILITY","Score":null,"Total":0}
引用次数: 0
摘要
随着当代数据集变得过于庞大而无法直接分析数据,各种形式的汇总数据变得越来越常见。原始的单个数据是点,但汇总后的观测值是区间值(例如)。虽然有些研究人员只是按聚合类别分析观测值的平均值集,但很容易确定这种方法忽略了原始数据集中的许多信息。勒-拉德马赫和比拉尔德(J Stat Plan Infer 141:1593-1602, 2011)对区间值数据进行了初步的理论研究,但这些研究成果仅限于估计单一变量的均值和方差。本文试图通过推导最重要的协方差统计量的最大似然估计器来弥补他们工作的局限性,协方差统计量是回归、主成分和典型分析等众多方法的基本要求。提出的估计器的渐近特性已经确定。Le-Rademacher 和 Billard 结果是我们更广泛推导的特例。
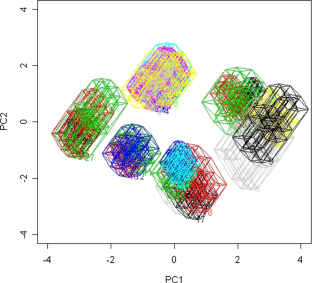
MLE for the parameters of bivariate interval-valued model
With contemporary data sets becoming too large to analyze the data directly, various forms of aggregated data are becoming common. The original individual data are points, but after aggregation the observations are interval-valued (e.g.). While some researchers simply analyze the set of averages of the observations by aggregated class, it is easily established that approach ignores much of the information in the original data set. The initial theoretical work for interval-valued data was that of Le-Rademacher and Billard (J Stat Plan Infer 141:1593–1602, 2011), but those results were limited to estimation of the mean and variance of a single variable only. This article seeks to redress the limitation of their work by deriving the maximum likelihood estimator for the all important covariance statistic, a basic requirement for numerous methodologies, such as regression, principal components, and canonical analyses. Asymptotic properties of the proposed estimators are established. The Le-Rademacher and Billard results emerge as special cases of our wider derivations.
期刊介绍:
The international journal Advances in Data Analysis and Classification (ADAC) is designed as a forum for high standard publications on research and applications concerning the extraction of knowable aspects from many types of data. It publishes articles on such topics as structural, quantitative, or statistical approaches for the analysis of data; advances in classification, clustering, and pattern recognition methods; strategies for modeling complex data and mining large data sets; methods for the extraction of knowledge from data, and applications of advanced methods in specific domains of practice. Articles illustrate how new domain-specific knowledge can be made available from data by skillful use of data analysis methods. The journal also publishes survey papers that outline, and illuminate the basic ideas and techniques of special approaches.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


