{"title":"从叶子到标签:使用LeafMachine2构建用于快速植物标本分析的模块化机器学习网络。","authors":"William N. Weaver, Stephen A. Smith","doi":"10.1002/aps3.11548","DOIUrl":null,"url":null,"abstract":"<div>\n \n \n <section>\n \n <h3> Premise</h3>\n \n <p>Quantitative plant traits play a crucial role in biological research. However, traditional methods for measuring plant morphology are time consuming and have limited scalability. We present LeafMachine2, a suite of modular machine learning and computer vision tools that can automatically extract a base set of leaf traits from digital plant data sets.</p>\n </section>\n \n <section>\n \n <h3> Methods</h3>\n \n <p>LeafMachine2 was trained on 494,766 manually prepared annotations from 5648 herbarium images obtained from 288 institutions and representing 2663 species; it employs a set of plant component detection and segmentation algorithms to isolate individual leaves, petioles, fruits, flowers, wood samples, buds, and roots. Our landmarking network automatically identifies and measures nine pseudo-landmarks that occur on most broadleaf taxa. Text labels and barcodes are automatically identified by an archival component detector and are prepared for optical character recognition methods or natural language processing algorithms.</p>\n </section>\n \n <section>\n \n <h3> Results</h3>\n \n <p>LeafMachine2 can extract trait data from at least 245 angiosperm families and calculate pixel-to-metric conversion factors for 26 commonly used ruler types.</p>\n </section>\n \n <section>\n \n <h3> Discussion</h3>\n \n <p>LeafMachine2 is a highly efficient tool for generating large quantities of plant trait data, even from occluded or overlapping leaves, field images, and non-archival data sets. Our project, along with similar initiatives, has made significant progress in removing the bottleneck in plant trait data acquisition from herbarium specimens and shifted the focus toward the crucial task of data revision and quality control.</p>\n </section>\n </div>","PeriodicalId":8022,"journal":{"name":"Applications in Plant Sciences","volume":"11 5","pages":""},"PeriodicalIF":2.4000,"publicationDate":"2023-10-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"4","resultStr":"{\"title\":\"From leaves to labels: Building modular machine learning networks for rapid herbarium specimen analysis with LeafMachine2\",\"authors\":\"William N. Weaver, Stephen A. Smith\",\"doi\":\"10.1002/aps3.11548\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div>\\n \\n \\n <section>\\n \\n <h3> Premise</h3>\\n \\n <p>Quantitative plant traits play a crucial role in biological research. However, traditional methods for measuring plant morphology are time consuming and have limited scalability. We present LeafMachine2, a suite of modular machine learning and computer vision tools that can automatically extract a base set of leaf traits from digital plant data sets.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Methods</h3>\\n \\n <p>LeafMachine2 was trained on 494,766 manually prepared annotations from 5648 herbarium images obtained from 288 institutions and representing 2663 species; it employs a set of plant component detection and segmentation algorithms to isolate individual leaves, petioles, fruits, flowers, wood samples, buds, and roots. Our landmarking network automatically identifies and measures nine pseudo-landmarks that occur on most broadleaf taxa. Text labels and barcodes are automatically identified by an archival component detector and are prepared for optical character recognition methods or natural language processing algorithms.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Results</h3>\\n \\n <p>LeafMachine2 can extract trait data from at least 245 angiosperm families and calculate pixel-to-metric conversion factors for 26 commonly used ruler types.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Discussion</h3>\\n \\n <p>LeafMachine2 is a highly efficient tool for generating large quantities of plant trait data, even from occluded or overlapping leaves, field images, and non-archival data sets. Our project, along with similar initiatives, has made significant progress in removing the bottleneck in plant trait data acquisition from herbarium specimens and shifted the focus toward the crucial task of data revision and quality control.</p>\\n </section>\\n </div>\",\"PeriodicalId\":8022,\"journal\":{\"name\":\"Applications in Plant Sciences\",\"volume\":\"11 5\",\"pages\":\"\"},\"PeriodicalIF\":2.4000,\"publicationDate\":\"2023-10-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"4\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Applications in Plant Sciences\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/aps3.11548\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"PLANT SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Applications in Plant Sciences","FirstCategoryId":"99","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/aps3.11548","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"PLANT SCIENCES","Score":null,"Total":0}
From leaves to labels: Building modular machine learning networks for rapid herbarium specimen analysis with LeafMachine2
Premise
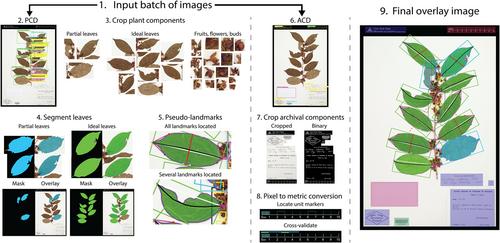
Quantitative plant traits play a crucial role in biological research. However, traditional methods for measuring plant morphology are time consuming and have limited scalability. We present LeafMachine2, a suite of modular machine learning and computer vision tools that can automatically extract a base set of leaf traits from digital plant data sets.
Methods
LeafMachine2 was trained on 494,766 manually prepared annotations from 5648 herbarium images obtained from 288 institutions and representing 2663 species; it employs a set of plant component detection and segmentation algorithms to isolate individual leaves, petioles, fruits, flowers, wood samples, buds, and roots. Our landmarking network automatically identifies and measures nine pseudo-landmarks that occur on most broadleaf taxa. Text labels and barcodes are automatically identified by an archival component detector and are prepared for optical character recognition methods or natural language processing algorithms.
Results
LeafMachine2 can extract trait data from at least 245 angiosperm families and calculate pixel-to-metric conversion factors for 26 commonly used ruler types.
Discussion
LeafMachine2 is a highly efficient tool for generating large quantities of plant trait data, even from occluded or overlapping leaves, field images, and non-archival data sets. Our project, along with similar initiatives, has made significant progress in removing the bottleneck in plant trait data acquisition from herbarium specimens and shifted the focus toward the crucial task of data revision and quality control.
期刊介绍:
Applications in Plant Sciences (APPS) is a monthly, peer-reviewed, open access journal promoting the rapid dissemination of newly developed, innovative tools and protocols in all areas of the plant sciences, including genetics, structure, function, development, evolution, systematics, and ecology. Given the rapid progress today in technology and its application in the plant sciences, the goal of APPS is to foster communication within the plant science community to advance scientific research. APPS is a publication of the Botanical Society of America, originating in 2009 as the American Journal of Botany''s online-only section, AJB Primer Notes & Protocols in the Plant Sciences.
APPS publishes the following types of articles: (1) Protocol Notes describe new methods and technological advancements; (2) Genomic Resources Articles characterize the development and demonstrate the usefulness of newly developed genomic resources, including transcriptomes; (3) Software Notes detail new software applications; (4) Application Articles illustrate the application of a new protocol, method, or software application within the context of a larger study; (5) Review Articles evaluate available techniques, methods, or protocols; (6) Primer Notes report novel genetic markers with evidence of wide applicability.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


