{"title":"基于情感信息检索的平滑和缩放语言模型","authors":"Fatma Najar, Nizar Bouguila","doi":"10.1007/s11634-022-00522-6","DOIUrl":null,"url":null,"abstract":"<div><p>Sentiment analysis or opinion mining refers to the discovery of sentiment information within textual documents, tweets, or review posts. This field has emerged with the social media outgrowth which becomes of great interest for several applications such as marketing, tourism, and business. In this work, we approach Twitter sentiment analysis through a novel framework that addresses simultaneously the problems of text representation such as sparseness and high-dimensionality. We propose an information retrieval probabilistic model based on a new distribution namely the Smoothed Scaled Dirichlet distribution. We present a likelihood learning method for estimating the parameters of the distribution and we propose a feature generation from the information retrieval system. We apply the proposed approach Smoothed Scaled Relevance Model on four Twitter sentiment datasets: STD, STS-Gold, SemEval14, and SentiStrength. We evaluate the performance of the offered solution with a comparison against the baseline models and the related-works.</p></div>","PeriodicalId":49270,"journal":{"name":"Advances in Data Analysis and Classification","volume":"17 3","pages":"725 - 744"},"PeriodicalIF":1.3000,"publicationDate":"2022-10-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"1","resultStr":"{\"title\":\"On smoothing and scaling language model for sentiment based information retrieval\",\"authors\":\"Fatma Najar, Nizar Bouguila\",\"doi\":\"10.1007/s11634-022-00522-6\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Sentiment analysis or opinion mining refers to the discovery of sentiment information within textual documents, tweets, or review posts. This field has emerged with the social media outgrowth which becomes of great interest for several applications such as marketing, tourism, and business. In this work, we approach Twitter sentiment analysis through a novel framework that addresses simultaneously the problems of text representation such as sparseness and high-dimensionality. We propose an information retrieval probabilistic model based on a new distribution namely the Smoothed Scaled Dirichlet distribution. We present a likelihood learning method for estimating the parameters of the distribution and we propose a feature generation from the information retrieval system. We apply the proposed approach Smoothed Scaled Relevance Model on four Twitter sentiment datasets: STD, STS-Gold, SemEval14, and SentiStrength. We evaluate the performance of the offered solution with a comparison against the baseline models and the related-works.</p></div>\",\"PeriodicalId\":49270,\"journal\":{\"name\":\"Advances in Data Analysis and Classification\",\"volume\":\"17 3\",\"pages\":\"725 - 744\"},\"PeriodicalIF\":1.3000,\"publicationDate\":\"2022-10-13\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"1\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Advances in Data Analysis and Classification\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s11634-022-00522-6\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"STATISTICS & PROBABILITY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Advances in Data Analysis and Classification","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s11634-022-00522-6","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"STATISTICS & PROBABILITY","Score":null,"Total":0}
On smoothing and scaling language model for sentiment based information retrieval
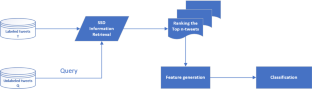
Sentiment analysis or opinion mining refers to the discovery of sentiment information within textual documents, tweets, or review posts. This field has emerged with the social media outgrowth which becomes of great interest for several applications such as marketing, tourism, and business. In this work, we approach Twitter sentiment analysis through a novel framework that addresses simultaneously the problems of text representation such as sparseness and high-dimensionality. We propose an information retrieval probabilistic model based on a new distribution namely the Smoothed Scaled Dirichlet distribution. We present a likelihood learning method for estimating the parameters of the distribution and we propose a feature generation from the information retrieval system. We apply the proposed approach Smoothed Scaled Relevance Model on four Twitter sentiment datasets: STD, STS-Gold, SemEval14, and SentiStrength. We evaluate the performance of the offered solution with a comparison against the baseline models and the related-works.
期刊介绍:
The international journal Advances in Data Analysis and Classification (ADAC) is designed as a forum for high standard publications on research and applications concerning the extraction of knowable aspects from many types of data. It publishes articles on such topics as structural, quantitative, or statistical approaches for the analysis of data; advances in classification, clustering, and pattern recognition methods; strategies for modeling complex data and mining large data sets; methods for the extraction of knowledge from data, and applications of advanced methods in specific domains of practice. Articles illustrate how new domain-specific knowledge can be made available from data by skillful use of data analysis methods. The journal also publishes survey papers that outline, and illuminate the basic ideas and techniques of special approaches.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


