Elijah Akwarandu Njoku , Patrick Etim Akpan , Augustine Edet Effiong , Isaac Oluwatosin Babatunde
{"title":"站点密度在瑞典气温地质统计预测中的作用:两种插值技术的比较","authors":"Elijah Akwarandu Njoku , Patrick Etim Akpan , Augustine Edet Effiong , Isaac Oluwatosin Babatunde","doi":"10.1016/j.resenv.2022.100092","DOIUrl":null,"url":null,"abstract":"<div><p>High fidelity gridded temperature datasets are difficult to obtain for areas with sparse coverage of meteorological stations given that sparsity of stations is known to introduce uncertainty in the interpolation of climatic variables generally. Inspired by their potential for optimal results especially for small sample datasets, we assessed and compared the accuracy of interpolation results of Empirical Bayesian Kriging (EBK) and EBK-Regression Prediction (EBKRP) spatial prediction techniques under varying sampling density scenarios, using monthly maximum temperature normals (1991–2020) for the entire area of Sweden. The objectives of the study were to understand how EBK and EBKRP interpolation techniques perform in different sampling density scenarios and particularly in a sparse data setting, and the possible difference in the prediction accuracy between the two techniques. The 708 sampled stations obtained from the historical climatology database of the Swedish Meteorological and Hydrological Institute (SMHI) were split into seven sampling density subsets, ranging from 1 sample per 63,614 km<sup>2</sup> to 1 sample per 634,350 km<sup>2</sup> and representing both low and high sampling density scenarios. EBK interpolation technique was implemented using temperature data while land use land cover (LULC) and digital elevation model (DEM) were used as temperature covariates for the EBKRP interpolation models. The prediction accuracy assessment was based on five robust prediction performance indicators – mean error, mean absolute error, mean square error, root mean square error and Pearson correlation (R) – obtained from independent validation/cross-validation operations. Prediction accuracy was found to be generally positively related to sampling density, and sampling density accounted for about 85%–87% of interpolation accuracy for both EBK and EBKRP techniques. Although sampling density increased linearly, the rate of change in accuracy from one sampling density step to the next was not particularly proportional. For equivalent sampling density set-ups, EBKRP consistently outperformed EBK in all the accuracy metrics and EBKRP proved to be approximately 40% better than EBK. However, the two interpolation techniques produced generally low prediction biases for all the sampling density scenarios investigated. Our study suggests that potential effects of low sampling density and non-stationarity of temperature data can be significantly reduced by applying EBK but especially EBKRP when coupled with relevant covariates. This is especially true for continuous and slowly varying phenomena such as temperature and similar variables.</p></div>","PeriodicalId":34479,"journal":{"name":"Resources Environment and Sustainability","volume":"11 ","pages":"Article 100092"},"PeriodicalIF":12.4000,"publicationDate":"2023-03-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"6","resultStr":"{\"title\":\"The effects of station density in geostatistical prediction of air temperatures in Sweden: A comparison of two interpolation techniques\",\"authors\":\"Elijah Akwarandu Njoku , Patrick Etim Akpan , Augustine Edet Effiong , Isaac Oluwatosin Babatunde\",\"doi\":\"10.1016/j.resenv.2022.100092\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>High fidelity gridded temperature datasets are difficult to obtain for areas with sparse coverage of meteorological stations given that sparsity of stations is known to introduce uncertainty in the interpolation of climatic variables generally. Inspired by their potential for optimal results especially for small sample datasets, we assessed and compared the accuracy of interpolation results of Empirical Bayesian Kriging (EBK) and EBK-Regression Prediction (EBKRP) spatial prediction techniques under varying sampling density scenarios, using monthly maximum temperature normals (1991–2020) for the entire area of Sweden. The objectives of the study were to understand how EBK and EBKRP interpolation techniques perform in different sampling density scenarios and particularly in a sparse data setting, and the possible difference in the prediction accuracy between the two techniques. The 708 sampled stations obtained from the historical climatology database of the Swedish Meteorological and Hydrological Institute (SMHI) were split into seven sampling density subsets, ranging from 1 sample per 63,614 km<sup>2</sup> to 1 sample per 634,350 km<sup>2</sup> and representing both low and high sampling density scenarios. EBK interpolation technique was implemented using temperature data while land use land cover (LULC) and digital elevation model (DEM) were used as temperature covariates for the EBKRP interpolation models. The prediction accuracy assessment was based on five robust prediction performance indicators – mean error, mean absolute error, mean square error, root mean square error and Pearson correlation (R) – obtained from independent validation/cross-validation operations. Prediction accuracy was found to be generally positively related to sampling density, and sampling density accounted for about 85%–87% of interpolation accuracy for both EBK and EBKRP techniques. Although sampling density increased linearly, the rate of change in accuracy from one sampling density step to the next was not particularly proportional. For equivalent sampling density set-ups, EBKRP consistently outperformed EBK in all the accuracy metrics and EBKRP proved to be approximately 40% better than EBK. However, the two interpolation techniques produced generally low prediction biases for all the sampling density scenarios investigated. Our study suggests that potential effects of low sampling density and non-stationarity of temperature data can be significantly reduced by applying EBK but especially EBKRP when coupled with relevant covariates. This is especially true for continuous and slowly varying phenomena such as temperature and similar variables.</p></div>\",\"PeriodicalId\":34479,\"journal\":{\"name\":\"Resources Environment and Sustainability\",\"volume\":\"11 \",\"pages\":\"Article 100092\"},\"PeriodicalIF\":12.4000,\"publicationDate\":\"2023-03-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"6\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Resources Environment and Sustainability\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2666916122000366\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"ENVIRONMENTAL SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Resources Environment and Sustainability","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2666916122000366","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"ENVIRONMENTAL SCIENCES","Score":null,"Total":0}
The effects of station density in geostatistical prediction of air temperatures in Sweden: A comparison of two interpolation techniques
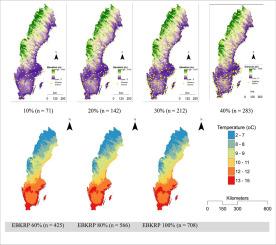
High fidelity gridded temperature datasets are difficult to obtain for areas with sparse coverage of meteorological stations given that sparsity of stations is known to introduce uncertainty in the interpolation of climatic variables generally. Inspired by their potential for optimal results especially for small sample datasets, we assessed and compared the accuracy of interpolation results of Empirical Bayesian Kriging (EBK) and EBK-Regression Prediction (EBKRP) spatial prediction techniques under varying sampling density scenarios, using monthly maximum temperature normals (1991–2020) for the entire area of Sweden. The objectives of the study were to understand how EBK and EBKRP interpolation techniques perform in different sampling density scenarios and particularly in a sparse data setting, and the possible difference in the prediction accuracy between the two techniques. The 708 sampled stations obtained from the historical climatology database of the Swedish Meteorological and Hydrological Institute (SMHI) were split into seven sampling density subsets, ranging from 1 sample per 63,614 km2 to 1 sample per 634,350 km2 and representing both low and high sampling density scenarios. EBK interpolation technique was implemented using temperature data while land use land cover (LULC) and digital elevation model (DEM) were used as temperature covariates for the EBKRP interpolation models. The prediction accuracy assessment was based on five robust prediction performance indicators – mean error, mean absolute error, mean square error, root mean square error and Pearson correlation (R) – obtained from independent validation/cross-validation operations. Prediction accuracy was found to be generally positively related to sampling density, and sampling density accounted for about 85%–87% of interpolation accuracy for both EBK and EBKRP techniques. Although sampling density increased linearly, the rate of change in accuracy from one sampling density step to the next was not particularly proportional. For equivalent sampling density set-ups, EBKRP consistently outperformed EBK in all the accuracy metrics and EBKRP proved to be approximately 40% better than EBK. However, the two interpolation techniques produced generally low prediction biases for all the sampling density scenarios investigated. Our study suggests that potential effects of low sampling density and non-stationarity of temperature data can be significantly reduced by applying EBK but especially EBKRP when coupled with relevant covariates. This is especially true for continuous and slowly varying phenomena such as temperature and similar variables.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


