Michael Burke, Katie Lu, Daniel Angelov, Artūras Straižys, Craig Innes, Kartic Subr, Subramanian Ramamoorthy
{"title":"使用概率时间排序从探索性演示中学习奖励","authors":"Michael Burke, Katie Lu, Daniel Angelov, Artūras Straižys, Craig Innes, Kartic Subr, Subramanian Ramamoorthy","doi":"10.1007/s10514-023-10120-w","DOIUrl":null,"url":null,"abstract":"<div><p>Informative path-planning is a well established approach to visual-servoing and active viewpoint selection in robotics, but typically assumes that a suitable cost function or goal state is known. This work considers the inverse problem, where the goal of the task is unknown, and a reward function needs to be inferred from exploratory example demonstrations provided by a demonstrator, for use in a downstream informative path-planning policy. Unfortunately, many existing reward inference strategies are unsuited to this class of problems, due to the exploratory nature of the demonstrations. In this paper, we propose an alternative approach to cope with the class of problems where these sub-optimal, exploratory demonstrations occur. We hypothesise that, in tasks which require discovery, successive states of any demonstration are progressively more likely to be associated with a higher reward, and use this hypothesis to generate time-based binary comparison outcomes and infer reward functions that support these ranks, under a probabilistic generative model. We formalise this <i>probabilistic temporal ranking</i> approach and show that it improves upon existing approaches to perform reward inference for autonomous ultrasound scanning, a novel application of learning from demonstration in medical imaging while also being of value across a broad range of goal-oriented learning from demonstration tasks.</p></div>","PeriodicalId":55409,"journal":{"name":"Autonomous Robots","volume":"47 6","pages":"733 - 751"},"PeriodicalIF":4.3000,"publicationDate":"2023-07-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://link.springer.com/content/pdf/10.1007/s10514-023-10120-w.pdf","citationCount":"0","resultStr":"{\"title\":\"Learning rewards from exploratory demonstrations using probabilistic temporal ranking\",\"authors\":\"Michael Burke, Katie Lu, Daniel Angelov, Artūras Straižys, Craig Innes, Kartic Subr, Subramanian Ramamoorthy\",\"doi\":\"10.1007/s10514-023-10120-w\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Informative path-planning is a well established approach to visual-servoing and active viewpoint selection in robotics, but typically assumes that a suitable cost function or goal state is known. This work considers the inverse problem, where the goal of the task is unknown, and a reward function needs to be inferred from exploratory example demonstrations provided by a demonstrator, for use in a downstream informative path-planning policy. Unfortunately, many existing reward inference strategies are unsuited to this class of problems, due to the exploratory nature of the demonstrations. In this paper, we propose an alternative approach to cope with the class of problems where these sub-optimal, exploratory demonstrations occur. We hypothesise that, in tasks which require discovery, successive states of any demonstration are progressively more likely to be associated with a higher reward, and use this hypothesis to generate time-based binary comparison outcomes and infer reward functions that support these ranks, under a probabilistic generative model. We formalise this <i>probabilistic temporal ranking</i> approach and show that it improves upon existing approaches to perform reward inference for autonomous ultrasound scanning, a novel application of learning from demonstration in medical imaging while also being of value across a broad range of goal-oriented learning from demonstration tasks.</p></div>\",\"PeriodicalId\":55409,\"journal\":{\"name\":\"Autonomous Robots\",\"volume\":\"47 6\",\"pages\":\"733 - 751\"},\"PeriodicalIF\":4.3000,\"publicationDate\":\"2023-07-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://link.springer.com/content/pdf/10.1007/s10514-023-10120-w.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Autonomous Robots\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s10514-023-10120-w\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Autonomous Robots","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s10514-023-10120-w","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Learning rewards from exploratory demonstrations using probabilistic temporal ranking
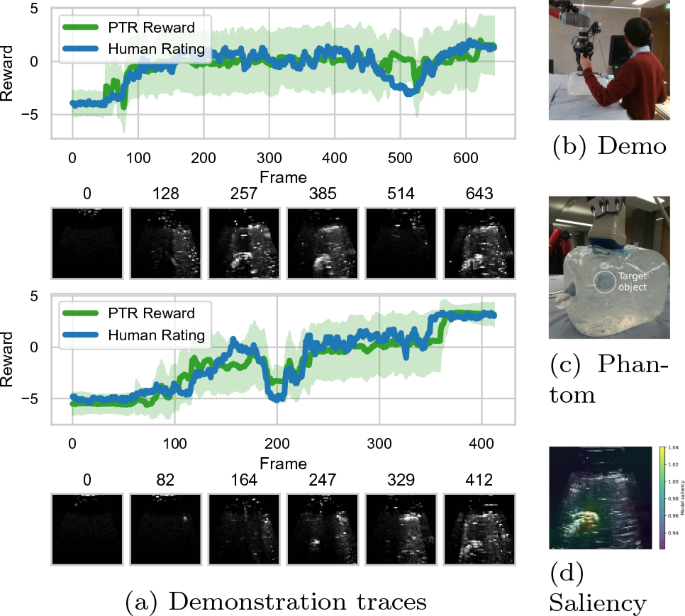
Informative path-planning is a well established approach to visual-servoing and active viewpoint selection in robotics, but typically assumes that a suitable cost function or goal state is known. This work considers the inverse problem, where the goal of the task is unknown, and a reward function needs to be inferred from exploratory example demonstrations provided by a demonstrator, for use in a downstream informative path-planning policy. Unfortunately, many existing reward inference strategies are unsuited to this class of problems, due to the exploratory nature of the demonstrations. In this paper, we propose an alternative approach to cope with the class of problems where these sub-optimal, exploratory demonstrations occur. We hypothesise that, in tasks which require discovery, successive states of any demonstration are progressively more likely to be associated with a higher reward, and use this hypothesis to generate time-based binary comparison outcomes and infer reward functions that support these ranks, under a probabilistic generative model. We formalise this probabilistic temporal ranking approach and show that it improves upon existing approaches to perform reward inference for autonomous ultrasound scanning, a novel application of learning from demonstration in medical imaging while also being of value across a broad range of goal-oriented learning from demonstration tasks.
期刊介绍:
Autonomous Robots reports on the theory and applications of robotic systems capable of some degree of self-sufficiency. It features papers that include performance data on actual robots in the real world. Coverage includes: control of autonomous robots · real-time vision · autonomous wheeled and tracked vehicles · legged vehicles · computational architectures for autonomous systems · distributed architectures for learning, control and adaptation · studies of autonomous robot systems · sensor fusion · theory of autonomous systems · terrain mapping and recognition · self-calibration and self-repair for robots · self-reproducing intelligent structures · genetic algorithms as models for robot development.
The focus is on the ability to move and be self-sufficient, not on whether the system is an imitation of biology. Of course, biological models for robotic systems are of major interest to the journal since living systems are prototypes for autonomous behavior.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


