{"title":"机器学习算法在非线性系统预测分析中的应用——以采矿影响水数据为例","authors":"Kagiso Samuel More, Christian Wolkersdorfer","doi":"10.1016/j.wri.2023.100209","DOIUrl":null,"url":null,"abstract":"<div><p>Various techniques have been researched and introduced in water treatment plants to optimise treatment and management processes. This paper presents a solution that can help treatment plants to work more effectively and reach their mine water management goals. Using Python 3.7.1 programming language within an Anaconda 4.11.0 platform, neural networks and regression tree algorithms were compared to find the best performing model after the data had undergone robust data pre-processing and exploratory data analysis statistical techniques. The main aim was to use this best performing model to forecast mining influenced water (MIW) parameters. This approach will help the treatment plant operators in knowing the future MIW chemistry, and they can eventually plan ahead of time what chemicals and methods to use to treat and manage polluted MIW. Westrand mine pool water near Randfontein, South Africa is used as a case study, in which historical data (2016–2021) from shaft № 9 is used to train and test the algorithms. These algorithms included the artificial neural network (ANN), deep neural network (DNN), gradient boosting and random forest regression trees, while the multivariate long short-term memory (LSTM) was used to generate new data for the best performing algorithm. Different data pre-processing approaches were explored, including data interpolation and anomaly detection. These processes were carried out to highlight the most important part of completing a machine learning related project, which is data analytics. Finally, the random forest regression tree algorithm showed the overall best performance and was used to forecast Fe and acidity concentrations of MIW for 60 days. It could be shown that artificial intelligence techniques are capable to optimise and forecast mine water treatment plant parameters, and it is imperative to perform robust statistical analysis on the data before attempting to build forecasting models.</p></div>","PeriodicalId":23714,"journal":{"name":"Water Resources and Industry","volume":"29 ","pages":"Article 100209"},"PeriodicalIF":7.5000,"publicationDate":"2023-06-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"2","resultStr":"{\"title\":\"Application of machine learning algorithms for nonlinear system forecasting through analytics — A case study with mining influenced water data\",\"authors\":\"Kagiso Samuel More, Christian Wolkersdorfer\",\"doi\":\"10.1016/j.wri.2023.100209\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Various techniques have been researched and introduced in water treatment plants to optimise treatment and management processes. This paper presents a solution that can help treatment plants to work more effectively and reach their mine water management goals. Using Python 3.7.1 programming language within an Anaconda 4.11.0 platform, neural networks and regression tree algorithms were compared to find the best performing model after the data had undergone robust data pre-processing and exploratory data analysis statistical techniques. The main aim was to use this best performing model to forecast mining influenced water (MIW) parameters. This approach will help the treatment plant operators in knowing the future MIW chemistry, and they can eventually plan ahead of time what chemicals and methods to use to treat and manage polluted MIW. Westrand mine pool water near Randfontein, South Africa is used as a case study, in which historical data (2016–2021) from shaft № 9 is used to train and test the algorithms. These algorithms included the artificial neural network (ANN), deep neural network (DNN), gradient boosting and random forest regression trees, while the multivariate long short-term memory (LSTM) was used to generate new data for the best performing algorithm. Different data pre-processing approaches were explored, including data interpolation and anomaly detection. These processes were carried out to highlight the most important part of completing a machine learning related project, which is data analytics. Finally, the random forest regression tree algorithm showed the overall best performance and was used to forecast Fe and acidity concentrations of MIW for 60 days. It could be shown that artificial intelligence techniques are capable to optimise and forecast mine water treatment plant parameters, and it is imperative to perform robust statistical analysis on the data before attempting to build forecasting models.</p></div>\",\"PeriodicalId\":23714,\"journal\":{\"name\":\"Water Resources and Industry\",\"volume\":\"29 \",\"pages\":\"Article 100209\"},\"PeriodicalIF\":7.5000,\"publicationDate\":\"2023-06-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"2\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Water Resources and Industry\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2212371723000094\",\"RegionNum\":3,\"RegionCategory\":\"工程技术\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"WATER RESOURCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Water Resources and Industry","FirstCategoryId":"5","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2212371723000094","RegionNum":3,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"WATER RESOURCES","Score":null,"Total":0}
Application of machine learning algorithms for nonlinear system forecasting through analytics — A case study with mining influenced water data
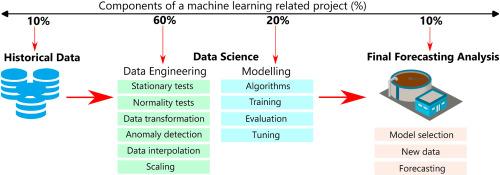
Various techniques have been researched and introduced in water treatment plants to optimise treatment and management processes. This paper presents a solution that can help treatment plants to work more effectively and reach their mine water management goals. Using Python 3.7.1 programming language within an Anaconda 4.11.0 platform, neural networks and regression tree algorithms were compared to find the best performing model after the data had undergone robust data pre-processing and exploratory data analysis statistical techniques. The main aim was to use this best performing model to forecast mining influenced water (MIW) parameters. This approach will help the treatment plant operators in knowing the future MIW chemistry, and they can eventually plan ahead of time what chemicals and methods to use to treat and manage polluted MIW. Westrand mine pool water near Randfontein, South Africa is used as a case study, in which historical data (2016–2021) from shaft № 9 is used to train and test the algorithms. These algorithms included the artificial neural network (ANN), deep neural network (DNN), gradient boosting and random forest regression trees, while the multivariate long short-term memory (LSTM) was used to generate new data for the best performing algorithm. Different data pre-processing approaches were explored, including data interpolation and anomaly detection. These processes were carried out to highlight the most important part of completing a machine learning related project, which is data analytics. Finally, the random forest regression tree algorithm showed the overall best performance and was used to forecast Fe and acidity concentrations of MIW for 60 days. It could be shown that artificial intelligence techniques are capable to optimise and forecast mine water treatment plant parameters, and it is imperative to perform robust statistical analysis on the data before attempting to build forecasting models.
期刊介绍:
Water Resources and Industry moves research to innovation by focusing on the role industry plays in the exploitation, management and treatment of water resources. Different industries use radically different water resources in their production processes, while they produce, treat and dispose a wide variety of wastewater qualities. Depending on the geographical location of the facilities, the impact on the local resources will vary, pre-empting the applicability of one single approach. The aims and scope of the journal include: -Industrial water footprint assessment - an evaluation of tools and methodologies -What constitutes good corporate governance and policy and how to evaluate water-related risk -What constitutes good stakeholder collaboration and engagement -New technologies enabling companies to better manage water resources -Integration of water and energy and of water treatment and production processes in industry

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


