Jason Miller, Andrew Balthrop, Beth Davis-Sramek, Robert Glenn Richey Jr
{"title":"档案研究中未观察到的变量:实现理论和统计识别","authors":"Jason Miller, Andrew Balthrop, Beth Davis-Sramek, Robert Glenn Richey Jr","doi":"10.1111/jbl.12358","DOIUrl":null,"url":null,"abstract":"<p>A welcomed addition to the logistics and supply chain management (L&SCM) research landscape has been growth in the use of archival data, defined as data collected by an entity outside the research team (Miller et al., <span>2021</span>). Expansion in the use of archival data is stimulated by discussions concerning the generally accepted limitations of primary data research and related debate about when and how the use of primary data is appropriate (e.g., Montabon et al., <span>2018</span>; Schoenherr et al., <span>2015</span>). Concurrently, there has been recognition that research utilizing archival data opens new avenues of emphasis for L&SCM research in answering a wide array of questions. When archival data is generated from industry and operations (e.g., DeHoratius et al., <span>2022</span>), direct application may be enhanced. Additionally, archival data is highly accessible, which aids in both replication and extension (Pagell, <span>2021</span>).</p><p>As with every research design, archival data poses multiple limitations, and there are unique challenges as researchers employing the data are detached from the original collection process. Recent articles have tackled issues concerning how to establish strong validity claims for measures derived from archival sources (Miller et al., <span>2021</span>) and how to formulate statistical models that ensure theoretical hypotheses map to estimated parameters (Ketokivi et al., <span>2021</span>). We refer to this as <i>statistical identification</i>, which focuses on the confidence that an estimated statistical parameter (e.g., regression coefficient) is reasonably unbiased and not overly sensitive to changes in the structure of the statistical model. Possibly the greatest threat to statistical identification is the existence of one or more unmeasured variables that reside theoretically upstream or parallel to the independent variables. If included as predictors in a statistical model, these variables could be significantly related to the outcome variable. This is highly problematic if the estimates of the independent variables could shift substantially (Miller & Kulpa, <span>2022</span>). We see a significant amount of emphasis on this aspect of the research, and the general remedy involves utilizing a combination of control variables and performing robustness tests (sometimes in excessive numbers) to rule out alternative explanations.</p><p>One fundamental issue that has not been adequately addressed in L&SCM research is related to theorizing. Theorizing involves devising hypotheses that will be tested with this archival data. It is not enough to develop statistical models where there is a reasonable degree of confidence that focal parameters are statistically identified. It is just as important to provide evidence of <i>theoretical identification</i>, defined here as the existence of strong and convincing rationale(s) that the theorized mechanisms bring to the reported results. Because archival data do not capture the unobserved processes that are postulated to bring about hypothesized relationships, theorizing in archival research can sometimes be more challenging than when using primary methods (Godfrey & Hill, <span>1995</span>; Ketokivi & Mantere, <span>2021</span>). Lack of guidance on this issue is problematic as it can (a) encourage research that presents “novel” findings without solid theoretical reasoning, (b) discourage L&SCM researchers from answering important questions, and (c) cause confusion between authors and reviewers during the peer review process.</p><p>In this editorial, we hope to provide clarification to authors and reviewers about theorizing with archival data. We asked Dr. Jason Miller and Dr. Andy Balthrop to co-author this manuscript given their exceptional methodological expertise in this area. To address the need for theoretical identification, we stress the importance of developing <i>mechanism-based explanations</i> when hypothesizing relationships between variables. We contend that it is critical in the research process to explicitly explain the “underlying entities, processes, or structures which operate in particular contexts to generate outcomes of interest” that are theorized to bring about the hypothesized effects (Astbury & Leeuw, <span>2010</span>, p. 368). The focus of offering mechanism-based explanations should be on developing logical arguments that explain unobserved underlying processes. It is these unobservable mechanisms, grounded in a study's context, that provide the rationale for hypotheses development concerning the directional relationships between selected variables (Bunge, <span>1997</span>).</p><p>In the sections that follow, we further clarify the role that theoretical identification should play in the research process. We also offer a 2 × 2 matrix to distinguish theoretical identification from statistical identification and we underscore why all research should feature both. Finally, we highlight the outstanding articles that are published in this issue.</p>","PeriodicalId":48090,"journal":{"name":"Journal of Business Logistics","volume":"44 3","pages":"292-299"},"PeriodicalIF":7.4000,"publicationDate":"2023-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/jbl.12358","citationCount":"1","resultStr":"{\"title\":\"Unobserved variables in archival research: Achieving both theoretical and statistical identification\",\"authors\":\"Jason Miller, Andrew Balthrop, Beth Davis-Sramek, Robert Glenn Richey Jr\",\"doi\":\"10.1111/jbl.12358\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>A welcomed addition to the logistics and supply chain management (L&SCM) research landscape has been growth in the use of archival data, defined as data collected by an entity outside the research team (Miller et al., <span>2021</span>). Expansion in the use of archival data is stimulated by discussions concerning the generally accepted limitations of primary data research and related debate about when and how the use of primary data is appropriate (e.g., Montabon et al., <span>2018</span>; Schoenherr et al., <span>2015</span>). Concurrently, there has been recognition that research utilizing archival data opens new avenues of emphasis for L&SCM research in answering a wide array of questions. When archival data is generated from industry and operations (e.g., DeHoratius et al., <span>2022</span>), direct application may be enhanced. Additionally, archival data is highly accessible, which aids in both replication and extension (Pagell, <span>2021</span>).</p><p>As with every research design, archival data poses multiple limitations, and there are unique challenges as researchers employing the data are detached from the original collection process. Recent articles have tackled issues concerning how to establish strong validity claims for measures derived from archival sources (Miller et al., <span>2021</span>) and how to formulate statistical models that ensure theoretical hypotheses map to estimated parameters (Ketokivi et al., <span>2021</span>). We refer to this as <i>statistical identification</i>, which focuses on the confidence that an estimated statistical parameter (e.g., regression coefficient) is reasonably unbiased and not overly sensitive to changes in the structure of the statistical model. Possibly the greatest threat to statistical identification is the existence of one or more unmeasured variables that reside theoretically upstream or parallel to the independent variables. If included as predictors in a statistical model, these variables could be significantly related to the outcome variable. This is highly problematic if the estimates of the independent variables could shift substantially (Miller & Kulpa, <span>2022</span>). We see a significant amount of emphasis on this aspect of the research, and the general remedy involves utilizing a combination of control variables and performing robustness tests (sometimes in excessive numbers) to rule out alternative explanations.</p><p>One fundamental issue that has not been adequately addressed in L&SCM research is related to theorizing. Theorizing involves devising hypotheses that will be tested with this archival data. It is not enough to develop statistical models where there is a reasonable degree of confidence that focal parameters are statistically identified. It is just as important to provide evidence of <i>theoretical identification</i>, defined here as the existence of strong and convincing rationale(s) that the theorized mechanisms bring to the reported results. Because archival data do not capture the unobserved processes that are postulated to bring about hypothesized relationships, theorizing in archival research can sometimes be more challenging than when using primary methods (Godfrey & Hill, <span>1995</span>; Ketokivi & Mantere, <span>2021</span>). Lack of guidance on this issue is problematic as it can (a) encourage research that presents “novel” findings without solid theoretical reasoning, (b) discourage L&SCM researchers from answering important questions, and (c) cause confusion between authors and reviewers during the peer review process.</p><p>In this editorial, we hope to provide clarification to authors and reviewers about theorizing with archival data. We asked Dr. Jason Miller and Dr. Andy Balthrop to co-author this manuscript given their exceptional methodological expertise in this area. To address the need for theoretical identification, we stress the importance of developing <i>mechanism-based explanations</i> when hypothesizing relationships between variables. We contend that it is critical in the research process to explicitly explain the “underlying entities, processes, or structures which operate in particular contexts to generate outcomes of interest” that are theorized to bring about the hypothesized effects (Astbury & Leeuw, <span>2010</span>, p. 368). The focus of offering mechanism-based explanations should be on developing logical arguments that explain unobserved underlying processes. It is these unobservable mechanisms, grounded in a study's context, that provide the rationale for hypotheses development concerning the directional relationships between selected variables (Bunge, <span>1997</span>).</p><p>In the sections that follow, we further clarify the role that theoretical identification should play in the research process. We also offer a 2 × 2 matrix to distinguish theoretical identification from statistical identification and we underscore why all research should feature both. Finally, we highlight the outstanding articles that are published in this issue.</p>\",\"PeriodicalId\":48090,\"journal\":{\"name\":\"Journal of Business Logistics\",\"volume\":\"44 3\",\"pages\":\"292-299\"},\"PeriodicalIF\":7.4000,\"publicationDate\":\"2023-07-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1111/jbl.12358\",\"citationCount\":\"1\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Business Logistics\",\"FirstCategoryId\":\"91\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1111/jbl.12358\",\"RegionNum\":2,\"RegionCategory\":\"管理学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MANAGEMENT\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Business Logistics","FirstCategoryId":"91","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/jbl.12358","RegionNum":2,"RegionCategory":"管理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MANAGEMENT","Score":null,"Total":0}
引用次数: 1
摘要
物流和供应链管理(L&SCM)研究领域的一个受欢迎的补充是档案数据的使用不断增加,档案数据被定义为研究团队以外的实体收集的数据(Miller等人,2021)。关于原始数据研究普遍接受的局限性的讨论以及关于何时以及如何使用原始数据是适当的相关辩论(例如,Montabon等人,2018;Schoenherr et al., 2015)。同时,人们已经认识到,利用档案数据的研究为供应链管理研究开辟了新的途径,以回答一系列广泛的问题。当从工业和运营中产生档案数据时(例如,DeHoratius等人,2022),直接应用可能会得到加强。此外,档案数据是高度可访问的,这有助于复制和扩展(Pagell, 2021)。与每一个研究设计一样,档案数据具有多重局限性,并且由于使用数据的研究人员与原始收集过程分离,因此存在独特的挑战。最近的文章讨论了如何为来自档案来源的测量方法建立强有力的有效性声明(Miller et al., 2021)以及如何制定统计模型以确保理论假设映射到估计参数(Ketokivi et al., 2021)。我们将此称为统计识别,其重点是估计的统计参数(例如,回归系数)是合理无偏的,并且对统计模型结构的变化不过度敏感的置信度。可能对统计识别的最大威胁是存在一个或多个理论上位于独立变量上游或平行的未测量变量。如果将这些变量作为预测因子包括在统计模型中,这些变量可能与结果变量显著相关。如果自变量的估计值可能发生重大变化,这是非常有问题的(Miller &Kulpa, 2022)。我们看到了对这方面研究的大量强调,一般的补救措施包括利用控制变量的组合和执行稳健性测试(有时数量过多)来排除其他解释。在供应链管理研究中,一个尚未得到充分解决的基本问题是理论化。理论化包括设计假设,这些假设将被这些档案数据所检验。发展统计模型是不够的,因为在统计上已经确定了震源参数,这在一定程度上是可信的。同样重要的是提供理论鉴定的证据,这里定义为存在强有力的和令人信服的理由,即理论化的机制给报告的结果带来了什么。由于档案数据没有捕捉到未观察到的过程,而这些过程被假定会带来假设的关系,因此在档案研究中建立理论有时比使用主要方法时更具挑战性(Godfrey &希尔,1995;Ketokivi,Mantere, 2021)。在这个问题上缺乏指导是有问题的,因为它可以(a)鼓励那些在没有坚实理论推理的情况下提出“新颖”发现的研究,(b)阻碍L&SCM研究人员回答重要问题,以及(c)在同行评审过程中导致作者和审稿人之间的混淆。在这篇社论中,我们希望为作者和审稿人澄清利用档案数据进行理论化的问题。鉴于Jason Miller博士和Andy Balthrop博士在这一领域卓越的方法论专业知识,我们邀请他们共同撰写这份手稿。为了解决理论识别的需要,我们强调在假设变量之间的关系时发展基于机制的解释的重要性。我们认为,在研究过程中,明确解释“在特定背景下运作以产生感兴趣的结果的潜在实体、过程或结构”是至关重要的,这些实体、过程或结构是理论化的,可以带来假设的效果(Astbury &Leeuw, 2010, p. 368)。提供基于机制的解释的重点应该是发展解释未观察到的潜在过程的逻辑论证。正是这些基于研究背景的不可观察的机制,为有关选定变量之间的定向关系的假设发展提供了基本原理(Bunge, 1997)。在接下来的章节中,我们将进一步阐明理论识别在研究过程中应该发挥的作用。我们还提供了一个2 × 2矩阵来区分理论鉴定和统计鉴定,我们强调了为什么所有的研究都应该具有这两种特征。最后,我们将重点介绍本期发表的优秀文章。
Unobserved variables in archival research: Achieving both theoretical and statistical identification
A welcomed addition to the logistics and supply chain management (L&SCM) research landscape has been growth in the use of archival data, defined as data collected by an entity outside the research team (Miller et al., 2021). Expansion in the use of archival data is stimulated by discussions concerning the generally accepted limitations of primary data research and related debate about when and how the use of primary data is appropriate (e.g., Montabon et al., 2018; Schoenherr et al., 2015). Concurrently, there has been recognition that research utilizing archival data opens new avenues of emphasis for L&SCM research in answering a wide array of questions. When archival data is generated from industry and operations (e.g., DeHoratius et al., 2022), direct application may be enhanced. Additionally, archival data is highly accessible, which aids in both replication and extension (Pagell, 2021).
As with every research design, archival data poses multiple limitations, and there are unique challenges as researchers employing the data are detached from the original collection process. Recent articles have tackled issues concerning how to establish strong validity claims for measures derived from archival sources (Miller et al., 2021) and how to formulate statistical models that ensure theoretical hypotheses map to estimated parameters (Ketokivi et al., 2021). We refer to this as statistical identification, which focuses on the confidence that an estimated statistical parameter (e.g., regression coefficient) is reasonably unbiased and not overly sensitive to changes in the structure of the statistical model. Possibly the greatest threat to statistical identification is the existence of one or more unmeasured variables that reside theoretically upstream or parallel to the independent variables. If included as predictors in a statistical model, these variables could be significantly related to the outcome variable. This is highly problematic if the estimates of the independent variables could shift substantially (Miller & Kulpa, 2022). We see a significant amount of emphasis on this aspect of the research, and the general remedy involves utilizing a combination of control variables and performing robustness tests (sometimes in excessive numbers) to rule out alternative explanations.
One fundamental issue that has not been adequately addressed in L&SCM research is related to theorizing. Theorizing involves devising hypotheses that will be tested with this archival data. It is not enough to develop statistical models where there is a reasonable degree of confidence that focal parameters are statistically identified. It is just as important to provide evidence of theoretical identification, defined here as the existence of strong and convincing rationale(s) that the theorized mechanisms bring to the reported results. Because archival data do not capture the unobserved processes that are postulated to bring about hypothesized relationships, theorizing in archival research can sometimes be more challenging than when using primary methods (Godfrey & Hill, 1995; Ketokivi & Mantere, 2021). Lack of guidance on this issue is problematic as it can (a) encourage research that presents “novel” findings without solid theoretical reasoning, (b) discourage L&SCM researchers from answering important questions, and (c) cause confusion between authors and reviewers during the peer review process.
In this editorial, we hope to provide clarification to authors and reviewers about theorizing with archival data. We asked Dr. Jason Miller and Dr. Andy Balthrop to co-author this manuscript given their exceptional methodological expertise in this area. To address the need for theoretical identification, we stress the importance of developing mechanism-based explanations when hypothesizing relationships between variables. We contend that it is critical in the research process to explicitly explain the “underlying entities, processes, or structures which operate in particular contexts to generate outcomes of interest” that are theorized to bring about the hypothesized effects (Astbury & Leeuw, 2010, p. 368). The focus of offering mechanism-based explanations should be on developing logical arguments that explain unobserved underlying processes. It is these unobservable mechanisms, grounded in a study's context, that provide the rationale for hypotheses development concerning the directional relationships between selected variables (Bunge, 1997).
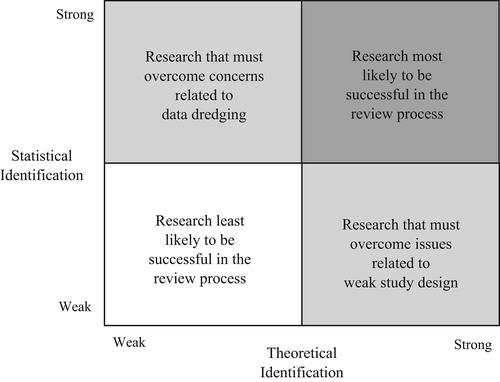
In the sections that follow, we further clarify the role that theoretical identification should play in the research process. We also offer a 2 × 2 matrix to distinguish theoretical identification from statistical identification and we underscore why all research should feature both. Finally, we highlight the outstanding articles that are published in this issue.
期刊介绍:
Supply chain management and logistics processes play a crucial role in the success of businesses, both in terms of operations, strategy, and finances. To gain a deep understanding of these processes, it is essential to explore academic literature such as The Journal of Business Logistics. This journal serves as a scholarly platform for sharing original ideas, research findings, and effective strategies in the field of logistics and supply chain management. By providing innovative insights and research-driven knowledge, it equips organizations with the necessary tools to navigate the ever-changing business environment.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


