{"title":"通过顺序处理将观察生物医学研究自动拆分为批次。","authors":"Bram Burger, Marc Vaudel, Harald Barsnes","doi":"10.1093/biostatistics/kxac014","DOIUrl":null,"url":null,"abstract":"<p><p>Experimental design usually focuses on the setting where treatments and/or other aspects of interest can be manipulated. However, in observational biomedical studies with sequential processing, the set of available samples is often fixed, and the problem is thus rather the ordering and allocation of samples to batches such that comparisons between different treatments can be made with similar precision. In certain situations, this allocation can be done by hand, but this rapidly becomes impractical with more challenging cohort setups. Here, we present a fast and intuitive algorithm to generate balanced allocations of samples to batches for any single-variable model where the treatment variable is nominal. This greatly simplifies the grouping of samples into batches, makes the process reproducible, and provides a marked improvement over completely random allocations. The general challenges of allocation and why good solutions can be hard to find are also discussed, as well as potential extensions to multivariable settings.</p>","PeriodicalId":55357,"journal":{"name":"Biostatistics","volume":null,"pages":null},"PeriodicalIF":1.8000,"publicationDate":"2023-10-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10583723/pdf/","citationCount":"0","resultStr":"{\"title\":\"Automated splitting into batches for observational biomedical studies with sequential processing.\",\"authors\":\"Bram Burger, Marc Vaudel, Harald Barsnes\",\"doi\":\"10.1093/biostatistics/kxac014\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Experimental design usually focuses on the setting where treatments and/or other aspects of interest can be manipulated. However, in observational biomedical studies with sequential processing, the set of available samples is often fixed, and the problem is thus rather the ordering and allocation of samples to batches such that comparisons between different treatments can be made with similar precision. In certain situations, this allocation can be done by hand, but this rapidly becomes impractical with more challenging cohort setups. Here, we present a fast and intuitive algorithm to generate balanced allocations of samples to batches for any single-variable model where the treatment variable is nominal. This greatly simplifies the grouping of samples into batches, makes the process reproducible, and provides a marked improvement over completely random allocations. The general challenges of allocation and why good solutions can be hard to find are also discussed, as well as potential extensions to multivariable settings.</p>\",\"PeriodicalId\":55357,\"journal\":{\"name\":\"Biostatistics\",\"volume\":null,\"pages\":null},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2023-10-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10583723/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biostatistics\",\"FirstCategoryId\":\"100\",\"ListUrlMain\":\"https://doi.org/10.1093/biostatistics/kxac014\",\"RegionNum\":3,\"RegionCategory\":\"数学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biostatistics","FirstCategoryId":"100","ListUrlMain":"https://doi.org/10.1093/biostatistics/kxac014","RegionNum":3,"RegionCategory":"数学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Automated splitting into batches for observational biomedical studies with sequential processing.
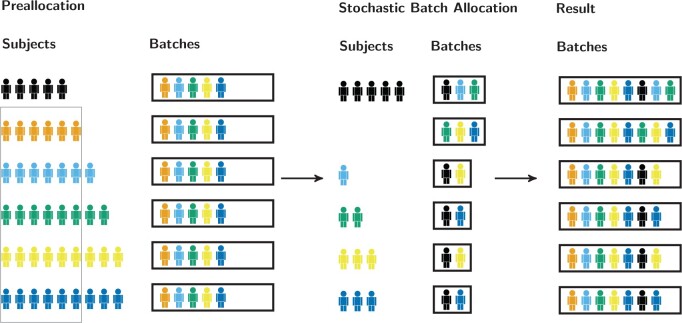
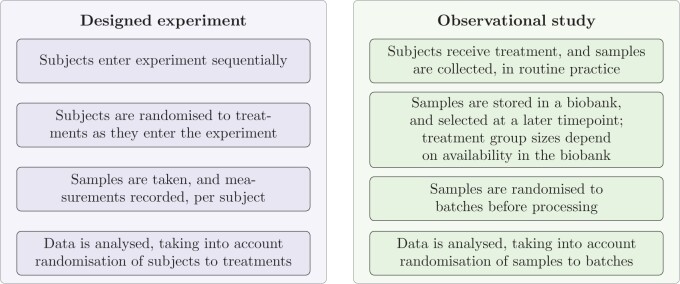
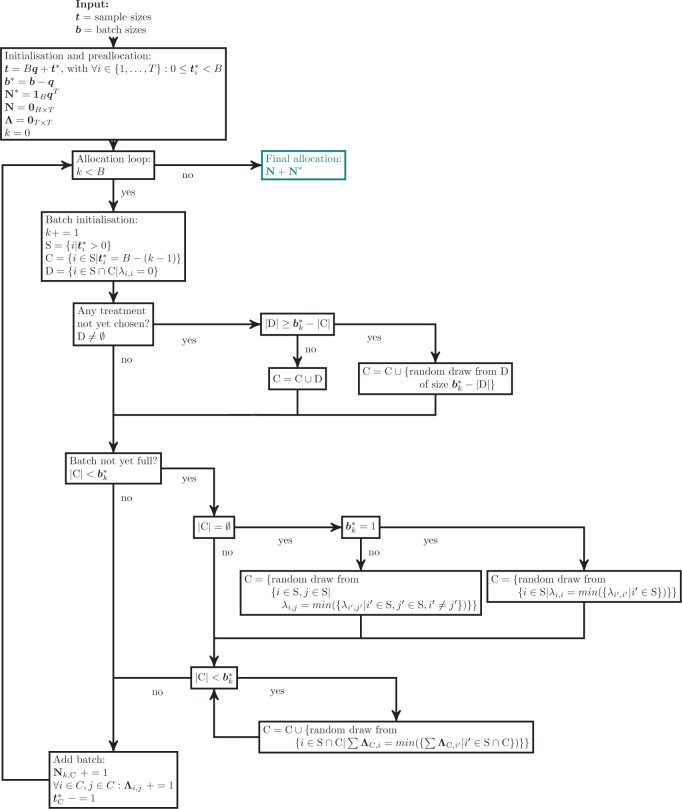
Experimental design usually focuses on the setting where treatments and/or other aspects of interest can be manipulated. However, in observational biomedical studies with sequential processing, the set of available samples is often fixed, and the problem is thus rather the ordering and allocation of samples to batches such that comparisons between different treatments can be made with similar precision. In certain situations, this allocation can be done by hand, but this rapidly becomes impractical with more challenging cohort setups. Here, we present a fast and intuitive algorithm to generate balanced allocations of samples to batches for any single-variable model where the treatment variable is nominal. This greatly simplifies the grouping of samples into batches, makes the process reproducible, and provides a marked improvement over completely random allocations. The general challenges of allocation and why good solutions can be hard to find are also discussed, as well as potential extensions to multivariable settings.
期刊介绍:
Among the important scientific developments of the 20th century is the explosive growth in statistical reasoning and methods for application to studies of human health. Examples include developments in likelihood methods for inference, epidemiologic statistics, clinical trials, survival analysis, and statistical genetics. Substantive problems in public health and biomedical research have fueled the development of statistical methods, which in turn have improved our ability to draw valid inferences from data. The objective of Biostatistics is to advance statistical science and its application to problems of human health and disease, with the ultimate goal of advancing the public''s health.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


