Paula Andrea Perez-Toro, Judith Dineley, Raquel Iniesta, Yuezhou Zhang, Faith Matcham, Sara Siddi, Femke Lamers, Josep Maria Haro, Brenda W J H Penninx, Amos A Folarin, Tomas Arias-Vergara, Juan Rafael Orozco-Arroyave, Elmar Nöth, Andreas Maier, Til Wykes, Srinivasan Vairavan, Richard Dobson, Vaibhav A Narayan, Matthew Hotopf, Nicholas Cummins
{"title":"探索在多语言抑郁症语料库中使用大型语言模型的偏差。","authors":"Paula Andrea Perez-Toro, Judith Dineley, Raquel Iniesta, Yuezhou Zhang, Faith Matcham, Sara Siddi, Femke Lamers, Josep Maria Haro, Brenda W J H Penninx, Amos A Folarin, Tomas Arias-Vergara, Juan Rafael Orozco-Arroyave, Elmar Nöth, Andreas Maier, Til Wykes, Srinivasan Vairavan, Richard Dobson, Vaibhav A Narayan, Matthew Hotopf, Nicholas Cummins","doi":"10.1038/s41598-025-19980-x","DOIUrl":null,"url":null,"abstract":"<p><p>Recent advancements in Large Language Models (LLMs) present promising opportunities for applying these technologies to aid the detection and monitoring of Major Depressive Disorder. However, demographic biases in LLMs may present challenges in the extraction of key information, where concerns persist about whether these models perform equally well across diverse populations. This study investigates how demographic factors, specifically age and gender affect the performance of LLMs in classifying depression symptom severity across multilingual datasets. By systematically balancing and evaluating datasets in English, Spanish, and Dutch, we aim to uncover performance disparities linked to demographic representation and linguistic diversity. The findings from this work can directly inform the design and deployment of more equitable LLM-based screening systems. Gender had varying effects across models, whereas age consistently produced more pronounced differences in performance. Additionally, model accuracy varied noticeably across languages. This study emphasizes the need to incorporate demographic-aware models in health-related analyses. It raises awareness of the biases that may affect their application in mental health and suggests further research on methods to mitigate these biases and enhance model generalization.</p>","PeriodicalId":21811,"journal":{"name":"Scientific Reports","volume":"15 1","pages":"36197"},"PeriodicalIF":3.9000,"publicationDate":"2025-10-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12533096/pdf/","citationCount":"0","resultStr":"{\"title\":\"Exploring biases related to the use of large language models in a multilingual depression corpus.\",\"authors\":\"Paula Andrea Perez-Toro, Judith Dineley, Raquel Iniesta, Yuezhou Zhang, Faith Matcham, Sara Siddi, Femke Lamers, Josep Maria Haro, Brenda W J H Penninx, Amos A Folarin, Tomas Arias-Vergara, Juan Rafael Orozco-Arroyave, Elmar Nöth, Andreas Maier, Til Wykes, Srinivasan Vairavan, Richard Dobson, Vaibhav A Narayan, Matthew Hotopf, Nicholas Cummins\",\"doi\":\"10.1038/s41598-025-19980-x\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Recent advancements in Large Language Models (LLMs) present promising opportunities for applying these technologies to aid the detection and monitoring of Major Depressive Disorder. However, demographic biases in LLMs may present challenges in the extraction of key information, where concerns persist about whether these models perform equally well across diverse populations. This study investigates how demographic factors, specifically age and gender affect the performance of LLMs in classifying depression symptom severity across multilingual datasets. By systematically balancing and evaluating datasets in English, Spanish, and Dutch, we aim to uncover performance disparities linked to demographic representation and linguistic diversity. The findings from this work can directly inform the design and deployment of more equitable LLM-based screening systems. Gender had varying effects across models, whereas age consistently produced more pronounced differences in performance. Additionally, model accuracy varied noticeably across languages. This study emphasizes the need to incorporate demographic-aware models in health-related analyses. It raises awareness of the biases that may affect their application in mental health and suggests further research on methods to mitigate these biases and enhance model generalization.</p>\",\"PeriodicalId\":21811,\"journal\":{\"name\":\"Scientific Reports\",\"volume\":\"15 1\",\"pages\":\"36197\"},\"PeriodicalIF\":3.9000,\"publicationDate\":\"2025-10-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12533096/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Scientific Reports\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://doi.org/10.1038/s41598-025-19980-x\",\"RegionNum\":2,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Scientific Reports","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1038/s41598-025-19980-x","RegionNum":2,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
Exploring biases related to the use of large language models in a multilingual depression corpus.
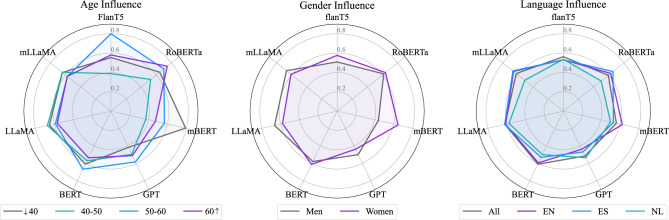
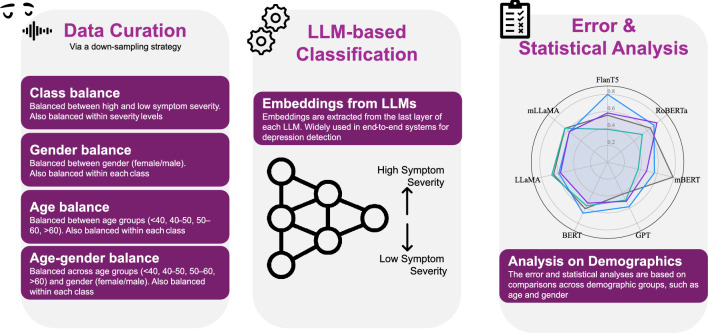
Recent advancements in Large Language Models (LLMs) present promising opportunities for applying these technologies to aid the detection and monitoring of Major Depressive Disorder. However, demographic biases in LLMs may present challenges in the extraction of key information, where concerns persist about whether these models perform equally well across diverse populations. This study investigates how demographic factors, specifically age and gender affect the performance of LLMs in classifying depression symptom severity across multilingual datasets. By systematically balancing and evaluating datasets in English, Spanish, and Dutch, we aim to uncover performance disparities linked to demographic representation and linguistic diversity. The findings from this work can directly inform the design and deployment of more equitable LLM-based screening systems. Gender had varying effects across models, whereas age consistently produced more pronounced differences in performance. Additionally, model accuracy varied noticeably across languages. This study emphasizes the need to incorporate demographic-aware models in health-related analyses. It raises awareness of the biases that may affect their application in mental health and suggests further research on methods to mitigate these biases and enhance model generalization.
期刊介绍:
We publish original research from all areas of the natural sciences, psychology, medicine and engineering. You can learn more about what we publish by browsing our specific scientific subject areas below or explore Scientific Reports by browsing all articles and collections.
Scientific Reports has a 2-year impact factor: 4.380 (2021), and is the 6th most-cited journal in the world, with more than 540,000 citations in 2020 (Clarivate Analytics, 2021).
•Engineering
Engineering covers all aspects of engineering, technology, and applied science. It plays a crucial role in the development of technologies to address some of the world''s biggest challenges, helping to save lives and improve the way we live.
•Physical sciences
Physical sciences are those academic disciplines that aim to uncover the underlying laws of nature — often written in the language of mathematics. It is a collective term for areas of study including astronomy, chemistry, materials science and physics.
•Earth and environmental sciences
Earth and environmental sciences cover all aspects of Earth and planetary science and broadly encompass solid Earth processes, surface and atmospheric dynamics, Earth system history, climate and climate change, marine and freshwater systems, and ecology. It also considers the interactions between humans and these systems.
•Biological sciences
Biological sciences encompass all the divisions of natural sciences examining various aspects of vital processes. The concept includes anatomy, physiology, cell biology, biochemistry and biophysics, and covers all organisms from microorganisms, animals to plants.
•Health sciences
The health sciences study health, disease and healthcare. This field of study aims to develop knowledge, interventions and technology for use in healthcare to improve the treatment of patients.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


