Hong-Seon Lee, Seung-Hyun Song, Chaeri Park, Jeongrok Seo, Won Hwa Kim, Jaeil Kim, Sungjun Kim, Kyunghwa Han, Young Han Lee
{"title":"简化的伦理:在人工智能生成的放射学报告中平衡患者的自主性、理解力和准确性。","authors":"Hong-Seon Lee, Seung-Hyun Song, Chaeri Park, Jeongrok Seo, Won Hwa Kim, Jaeil Kim, Sungjun Kim, Kyunghwa Han, Young Han Lee","doi":"10.1186/s12910-025-01285-3","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Large language models (LLMs) such as GPT-4 are increasingly used to simplify radiology reports and improve patient comprehension. However, excessive simplification may undermine informed consent and autonomy by compromising clinical accuracy. This study investigates the ethical implications of readability thresholds in AI-generated radiology reports, identifying the minimum reading level at which clinical accuracy is preserved.</p><p><strong>Methods: </strong>We retrospectively analyzed 500 computed tomography and magnetic resonance imaging reports from a tertiary hospital. Each report was transformed into 17 versions (reading grade levels 1-17) using GPT-4 Turbo. Readability metrics and word counts were calculated for each version. Clinical accuracy was evaluated using radiologist assessments and PubMed-BERTScore. We identified the first grade level at which a statistically significant decline in accuracy occurred, determining the lowest level that preserved both accuracy and readability. We further assessed potential clinical consequences in reports simplified to the 7th-grade level.</p><p><strong>Results: </strong>Readability scores showed strong correlation with prompted reading levels (r = 0.80-0.84). Accuracy remained stable across grades 13-11 but declined significantly below grade 11. At the 7th-grade level, 20% of reports contained inaccuracies with potential to alter patient management, primarily due to omission, incorrect conversion, or inappropriate generalization. The 11th-grade level emerged as the current lower bound for preserving accuracy in LLM-generated radiology reports.</p><p><strong>Conclusions: </strong>Our findings highlight an ethical tension between improving readability and maintaining clinical accuracy. While 7th-grade readability remains an ethical ideal, current AI tools cannot reliably produce accurate reports below the 11th-grade level. Ethical implementation of AI-generated reporting should include layered communication strategies and model transparency to safeguard patient autonomy and comprehension.</p>","PeriodicalId":55348,"journal":{"name":"BMC Medical Ethics","volume":"26 1","pages":"136"},"PeriodicalIF":3.1000,"publicationDate":"2025-10-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12523008/pdf/","citationCount":"0","resultStr":"{\"title\":\"The ethics of simplification: balancing patient autonomy, comprehension, and accuracy in AI-generated radiology reports.\",\"authors\":\"Hong-Seon Lee, Seung-Hyun Song, Chaeri Park, Jeongrok Seo, Won Hwa Kim, Jaeil Kim, Sungjun Kim, Kyunghwa Han, Young Han Lee\",\"doi\":\"10.1186/s12910-025-01285-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Large language models (LLMs) such as GPT-4 are increasingly used to simplify radiology reports and improve patient comprehension. However, excessive simplification may undermine informed consent and autonomy by compromising clinical accuracy. This study investigates the ethical implications of readability thresholds in AI-generated radiology reports, identifying the minimum reading level at which clinical accuracy is preserved.</p><p><strong>Methods: </strong>We retrospectively analyzed 500 computed tomography and magnetic resonance imaging reports from a tertiary hospital. Each report was transformed into 17 versions (reading grade levels 1-17) using GPT-4 Turbo. Readability metrics and word counts were calculated for each version. Clinical accuracy was evaluated using radiologist assessments and PubMed-BERTScore. We identified the first grade level at which a statistically significant decline in accuracy occurred, determining the lowest level that preserved both accuracy and readability. We further assessed potential clinical consequences in reports simplified to the 7th-grade level.</p><p><strong>Results: </strong>Readability scores showed strong correlation with prompted reading levels (r = 0.80-0.84). Accuracy remained stable across grades 13-11 but declined significantly below grade 11. At the 7th-grade level, 20% of reports contained inaccuracies with potential to alter patient management, primarily due to omission, incorrect conversion, or inappropriate generalization. The 11th-grade level emerged as the current lower bound for preserving accuracy in LLM-generated radiology reports.</p><p><strong>Conclusions: </strong>Our findings highlight an ethical tension between improving readability and maintaining clinical accuracy. While 7th-grade readability remains an ethical ideal, current AI tools cannot reliably produce accurate reports below the 11th-grade level. Ethical implementation of AI-generated reporting should include layered communication strategies and model transparency to safeguard patient autonomy and comprehension.</p>\",\"PeriodicalId\":55348,\"journal\":{\"name\":\"BMC Medical Ethics\",\"volume\":\"26 1\",\"pages\":\"136\"},\"PeriodicalIF\":3.1000,\"publicationDate\":\"2025-10-15\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12523008/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"BMC Medical Ethics\",\"FirstCategoryId\":\"98\",\"ListUrlMain\":\"https://doi.org/10.1186/s12910-025-01285-3\",\"RegionNum\":1,\"RegionCategory\":\"哲学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"ETHICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMC Medical Ethics","FirstCategoryId":"98","ListUrlMain":"https://doi.org/10.1186/s12910-025-01285-3","RegionNum":1,"RegionCategory":"哲学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"ETHICS","Score":null,"Total":0}
The ethics of simplification: balancing patient autonomy, comprehension, and accuracy in AI-generated radiology reports.
Background: Large language models (LLMs) such as GPT-4 are increasingly used to simplify radiology reports and improve patient comprehension. However, excessive simplification may undermine informed consent and autonomy by compromising clinical accuracy. This study investigates the ethical implications of readability thresholds in AI-generated radiology reports, identifying the minimum reading level at which clinical accuracy is preserved.
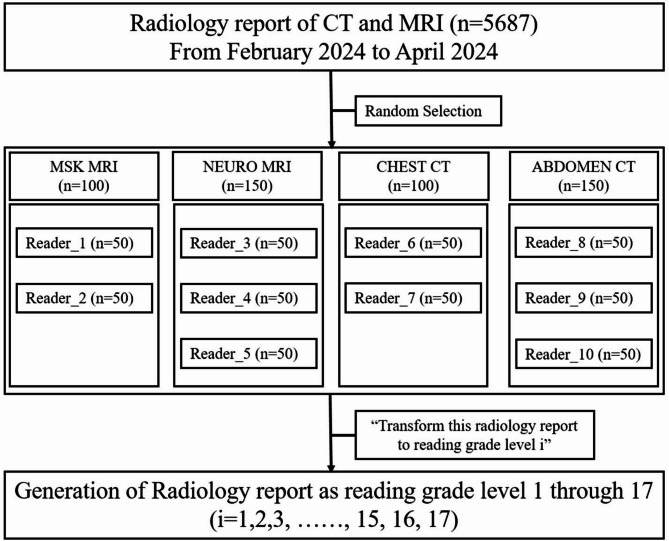
Methods: We retrospectively analyzed 500 computed tomography and magnetic resonance imaging reports from a tertiary hospital. Each report was transformed into 17 versions (reading grade levels 1-17) using GPT-4 Turbo. Readability metrics and word counts were calculated for each version. Clinical accuracy was evaluated using radiologist assessments and PubMed-BERTScore. We identified the first grade level at which a statistically significant decline in accuracy occurred, determining the lowest level that preserved both accuracy and readability. We further assessed potential clinical consequences in reports simplified to the 7th-grade level.
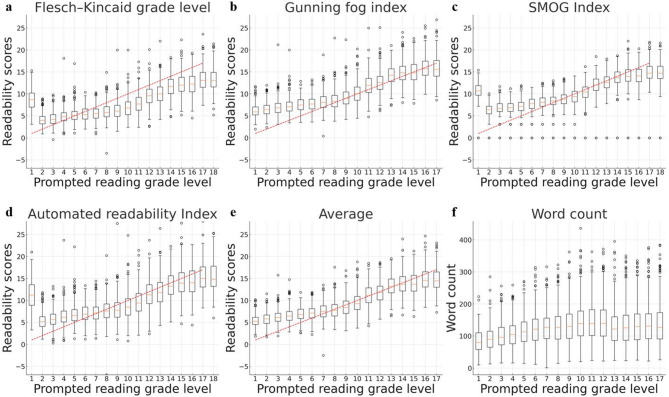
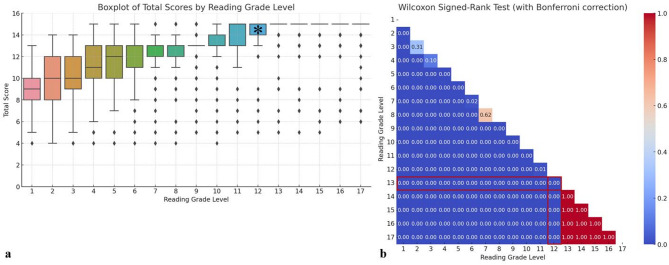
Results: Readability scores showed strong correlation with prompted reading levels (r = 0.80-0.84). Accuracy remained stable across grades 13-11 but declined significantly below grade 11. At the 7th-grade level, 20% of reports contained inaccuracies with potential to alter patient management, primarily due to omission, incorrect conversion, or inappropriate generalization. The 11th-grade level emerged as the current lower bound for preserving accuracy in LLM-generated radiology reports.
Conclusions: Our findings highlight an ethical tension between improving readability and maintaining clinical accuracy. While 7th-grade readability remains an ethical ideal, current AI tools cannot reliably produce accurate reports below the 11th-grade level. Ethical implementation of AI-generated reporting should include layered communication strategies and model transparency to safeguard patient autonomy and comprehension.
期刊介绍:
BMC Medical Ethics is an open access journal publishing original peer-reviewed research articles in relation to the ethical aspects of biomedical research and clinical practice, including professional choices and conduct, medical technologies, healthcare systems and health policies.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


