{"title":"chatgpt - 40在影像引导乳腺活检后影像学病理一致性和处理建议中的表现。","authors":"Albert Lee, Belinda Curpen, Afsaneh Alikhassi","doi":"10.3390/diagnostics15192536","DOIUrl":null,"url":null,"abstract":"<p><p><b>Background:</b> Determining radiology-pathology concordance after breast biopsies is critical to ensuring appropriate patient management. However, expertise and multidisciplinary input are not universally accessible. <b>Purpose:</b> To evaluate the performance of a large language model, ChatGPT-4o, in determining the radiology-pathology concordance of breast biopsies and suggesting subsequent management steps. <b>Methods:</b> A retrospective single-center study analyzed 244 cases of image-guided breast biopsies of women. ChatGPT-4o assessed de-identified radiology and pathology reports for concordance and recommended management. Radiologist assessments served as the reference standard with final surgical pathology and 2-year imaging follow-up serving as gold standards when applicable. Concordance rates, management recommendations, and diagnostic agreement with the gold standard were compared using statistical tests, including McNemar's, chi-square, Fisher-Freeman-Halton, and Cohen's kappa. <b>Results:</b> ChatGPT-4o achieved a concordance rate of 98.8% vs. 98.0% for radiologists (<i>p</i> = 0.625) and demonstrated high diagnostic agreement with the gold standard (kappa = 0.947, <i>p</i> < 0.001). ChatGPT-4o favored imaging follow-up more than radiologists (49.2% vs. 41.8%, <i>p</i> < 0.001) and surgical management less frequently (41.8% vs. 46.7%). <b>Conclusions:</b> ChatGPT-4o demonstrated diagnostic performance comparable to radiologists with breast imaging subspecialities in evaluating breast biopsy concordance. Its slightly more conservative management approach may enhance shared decision-making in resource-limited settings.</p>","PeriodicalId":11225,"journal":{"name":"Diagnostics","volume":"15 19","pages":""},"PeriodicalIF":3.3000,"publicationDate":"2025-10-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12523907/pdf/","citationCount":"0","resultStr":"{\"title\":\"Performance of ChatGPT-4o in Determining Radiology-Pathology Concordance and Management Recommendations Following Image-Guided Breast Biopsies.\",\"authors\":\"Albert Lee, Belinda Curpen, Afsaneh Alikhassi\",\"doi\":\"10.3390/diagnostics15192536\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p><b>Background:</b> Determining radiology-pathology concordance after breast biopsies is critical to ensuring appropriate patient management. However, expertise and multidisciplinary input are not universally accessible. <b>Purpose:</b> To evaluate the performance of a large language model, ChatGPT-4o, in determining the radiology-pathology concordance of breast biopsies and suggesting subsequent management steps. <b>Methods:</b> A retrospective single-center study analyzed 244 cases of image-guided breast biopsies of women. ChatGPT-4o assessed de-identified radiology and pathology reports for concordance and recommended management. Radiologist assessments served as the reference standard with final surgical pathology and 2-year imaging follow-up serving as gold standards when applicable. Concordance rates, management recommendations, and diagnostic agreement with the gold standard were compared using statistical tests, including McNemar's, chi-square, Fisher-Freeman-Halton, and Cohen's kappa. <b>Results:</b> ChatGPT-4o achieved a concordance rate of 98.8% vs. 98.0% for radiologists (<i>p</i> = 0.625) and demonstrated high diagnostic agreement with the gold standard (kappa = 0.947, <i>p</i> < 0.001). ChatGPT-4o favored imaging follow-up more than radiologists (49.2% vs. 41.8%, <i>p</i> < 0.001) and surgical management less frequently (41.8% vs. 46.7%). <b>Conclusions:</b> ChatGPT-4o demonstrated diagnostic performance comparable to radiologists with breast imaging subspecialities in evaluating breast biopsy concordance. Its slightly more conservative management approach may enhance shared decision-making in resource-limited settings.</p>\",\"PeriodicalId\":11225,\"journal\":{\"name\":\"Diagnostics\",\"volume\":\"15 19\",\"pages\":\"\"},\"PeriodicalIF\":3.3000,\"publicationDate\":\"2025-10-08\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12523907/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Diagnostics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.3390/diagnostics15192536\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MEDICINE, GENERAL & INTERNAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Diagnostics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.3390/diagnostics15192536","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MEDICINE, GENERAL & INTERNAL","Score":null,"Total":0}
Performance of ChatGPT-4o in Determining Radiology-Pathology Concordance and Management Recommendations Following Image-Guided Breast Biopsies.
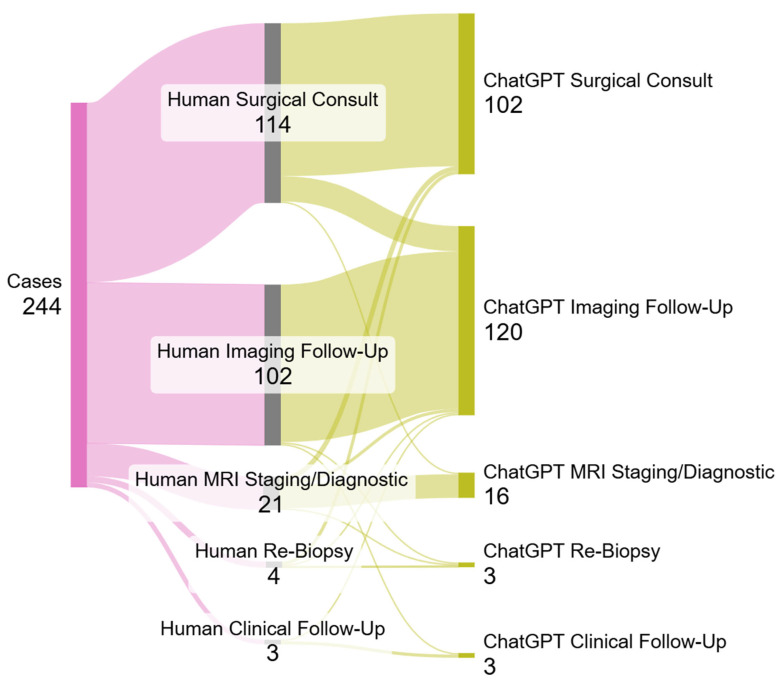
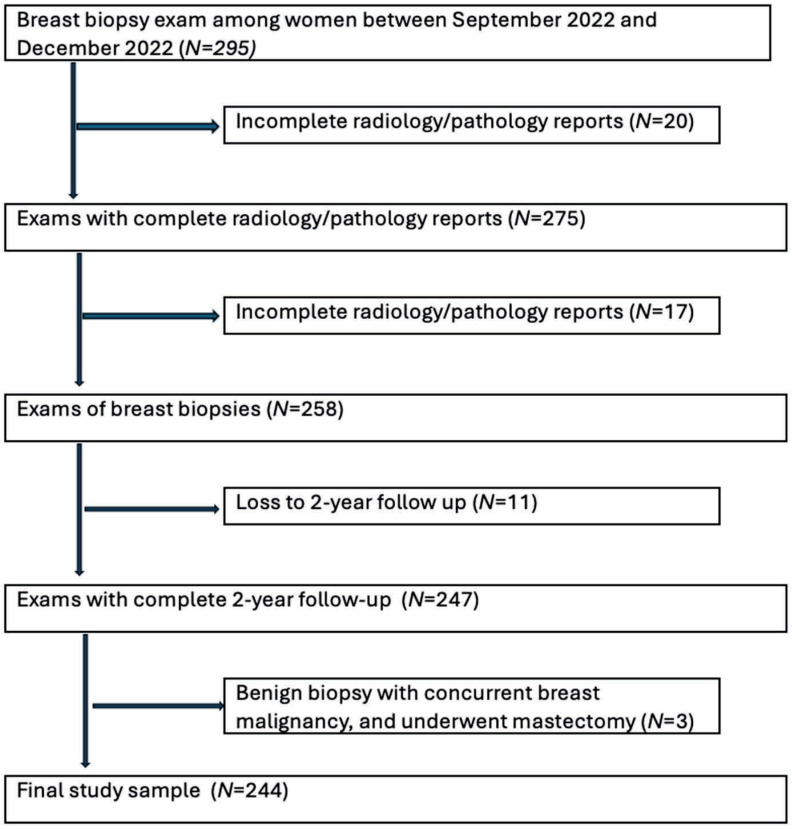
Background: Determining radiology-pathology concordance after breast biopsies is critical to ensuring appropriate patient management. However, expertise and multidisciplinary input are not universally accessible. Purpose: To evaluate the performance of a large language model, ChatGPT-4o, in determining the radiology-pathology concordance of breast biopsies and suggesting subsequent management steps. Methods: A retrospective single-center study analyzed 244 cases of image-guided breast biopsies of women. ChatGPT-4o assessed de-identified radiology and pathology reports for concordance and recommended management. Radiologist assessments served as the reference standard with final surgical pathology and 2-year imaging follow-up serving as gold standards when applicable. Concordance rates, management recommendations, and diagnostic agreement with the gold standard were compared using statistical tests, including McNemar's, chi-square, Fisher-Freeman-Halton, and Cohen's kappa. Results: ChatGPT-4o achieved a concordance rate of 98.8% vs. 98.0% for radiologists (p = 0.625) and demonstrated high diagnostic agreement with the gold standard (kappa = 0.947, p < 0.001). ChatGPT-4o favored imaging follow-up more than radiologists (49.2% vs. 41.8%, p < 0.001) and surgical management less frequently (41.8% vs. 46.7%). Conclusions: ChatGPT-4o demonstrated diagnostic performance comparable to radiologists with breast imaging subspecialities in evaluating breast biopsy concordance. Its slightly more conservative management approach may enhance shared decision-making in resource-limited settings.
DiagnosticsBiochemistry, Genetics and Molecular Biology-Clinical Biochemistry
CiteScore
4.70
自引率
8.30%
发文量
2699
审稿时长
19.64 days
期刊介绍:
Diagnostics (ISSN 2075-4418) is an international scholarly open access journal on medical diagnostics. It publishes original research articles, reviews, communications and short notes on the research and development of medical diagnostics. There is no restriction on the length of the papers. Our aim is to encourage scientists to publish their experimental and theoretical research in as much detail as possible. Full experimental and/or methodological details must be provided for research articles.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


