{"title":"回归均值解释了对行为后果的感知。","authors":"Saskia Johnen, Eckart Zimmermann","doi":"10.1098/rspb.2025.1715","DOIUrl":null,"url":null,"abstract":"<p><p>Predictions shape the perceptual consequences of our own actions such that self-generated events appear less intense to us. However, recent studies also reported sensory enhancement of self-produced sounds. Here, we tested whether sensory attenuation and enhancement are signatures of an adaptation to the mean sound statistics. In 330 human participants, we tested the idea that predictions about upcoming sounds shift auditory processing to the average sound context. Participants produced sounds between 40 and 80 decibels (dB) and rated their loudness. Estimates of perceived loudness followed a regression to the mean sound level. The effect was similar for self-produced and passively observed but temporally predictable tones, suggesting predictability alone drives perceptual changes. We then artificially created a new mean sound level by presenting sessions in which subjects mostly (80% of trials) produced either loud (80 dB) or quiet (40 dB) tones. In loud contexts, rarely presented quiet tones were enhanced, and in quiet contexts, loud tones were attenuated. Our results challenge the dominant forward model explanation, which attributes sensory attenuation to predictive suppression of self-generated stimuli, and instead open the door for alternative explanations. Our findings point to regression towards the mean sound level as the most plausible account for predictable sounds.</p>","PeriodicalId":520757,"journal":{"name":"Proceedings. Biological sciences","volume":"292 2057","pages":"20251715"},"PeriodicalIF":3.5000,"publicationDate":"2025-10-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12520771/pdf/","citationCount":"0","resultStr":"{\"title\":\"Regression to the mean explains perception of action consequences.\",\"authors\":\"Saskia Johnen, Eckart Zimmermann\",\"doi\":\"10.1098/rspb.2025.1715\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Predictions shape the perceptual consequences of our own actions such that self-generated events appear less intense to us. However, recent studies also reported sensory enhancement of self-produced sounds. Here, we tested whether sensory attenuation and enhancement are signatures of an adaptation to the mean sound statistics. In 330 human participants, we tested the idea that predictions about upcoming sounds shift auditory processing to the average sound context. Participants produced sounds between 40 and 80 decibels (dB) and rated their loudness. Estimates of perceived loudness followed a regression to the mean sound level. The effect was similar for self-produced and passively observed but temporally predictable tones, suggesting predictability alone drives perceptual changes. We then artificially created a new mean sound level by presenting sessions in which subjects mostly (80% of trials) produced either loud (80 dB) or quiet (40 dB) tones. In loud contexts, rarely presented quiet tones were enhanced, and in quiet contexts, loud tones were attenuated. Our results challenge the dominant forward model explanation, which attributes sensory attenuation to predictive suppression of self-generated stimuli, and instead open the door for alternative explanations. Our findings point to regression towards the mean sound level as the most plausible account for predictable sounds.</p>\",\"PeriodicalId\":520757,\"journal\":{\"name\":\"Proceedings. Biological sciences\",\"volume\":\"292 2057\",\"pages\":\"20251715\"},\"PeriodicalIF\":3.5000,\"publicationDate\":\"2025-10-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12520771/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Proceedings. Biological sciences\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1098/rspb.2025.1715\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/10/15 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Proceedings. Biological sciences","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1098/rspb.2025.1715","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/10/15 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
Regression to the mean explains perception of action consequences.
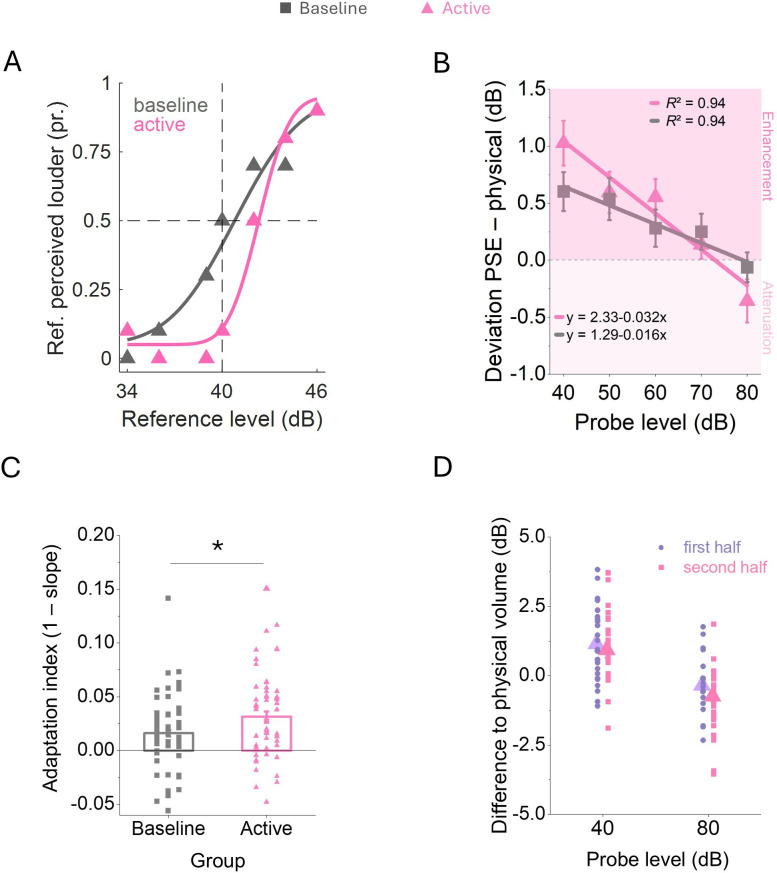
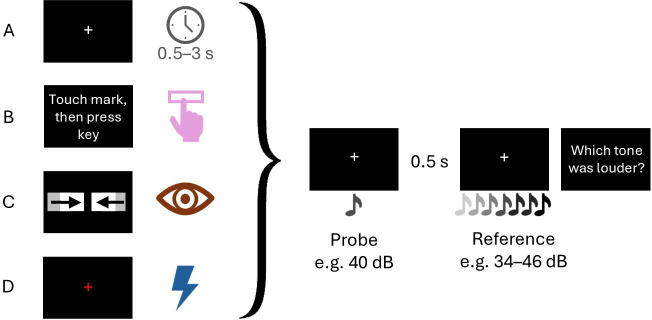
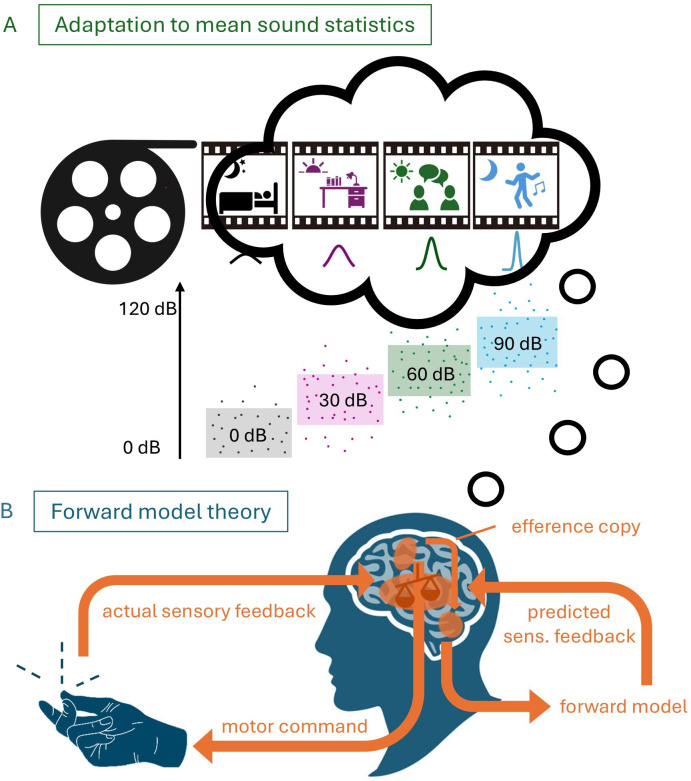
Predictions shape the perceptual consequences of our own actions such that self-generated events appear less intense to us. However, recent studies also reported sensory enhancement of self-produced sounds. Here, we tested whether sensory attenuation and enhancement are signatures of an adaptation to the mean sound statistics. In 330 human participants, we tested the idea that predictions about upcoming sounds shift auditory processing to the average sound context. Participants produced sounds between 40 and 80 decibels (dB) and rated their loudness. Estimates of perceived loudness followed a regression to the mean sound level. The effect was similar for self-produced and passively observed but temporally predictable tones, suggesting predictability alone drives perceptual changes. We then artificially created a new mean sound level by presenting sessions in which subjects mostly (80% of trials) produced either loud (80 dB) or quiet (40 dB) tones. In loud contexts, rarely presented quiet tones were enhanced, and in quiet contexts, loud tones were attenuated. Our results challenge the dominant forward model explanation, which attributes sensory attenuation to predictive suppression of self-generated stimuli, and instead open the door for alternative explanations. Our findings point to regression towards the mean sound level as the most plausible account for predictable sounds.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


