使用经过验证的工具对面向患者的泌尿外科远程手术内容进行质量评估。
摘要
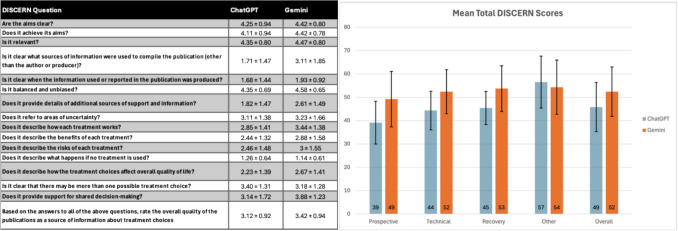
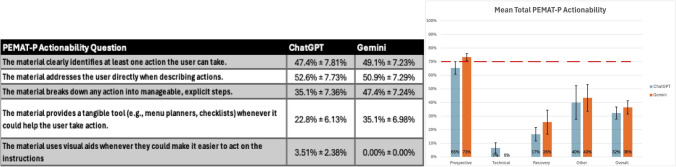
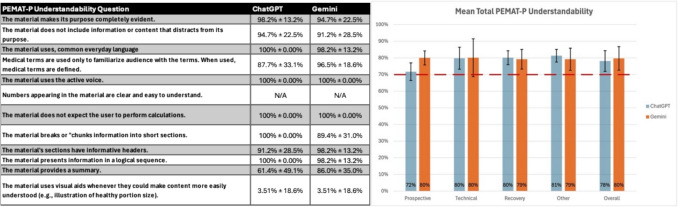
导读:随着人工智能(AI)聊天机器人的普及,提供的医疗信息的准确性和清晰度需要严格的评估。泌尿外科远程手术是一个复杂的概念,患者将使用人工智能进行研究。我们比较了ChatGPT和谷歌Gemini在提供泌尿外科远程手术面向患者的信息方面的差异。方法:利用美国泌尿外科协会(AUA)和欧洲机器人泌尿外科分会(ERUS)的一般资料,生成与泌尿外科远程手术相关的19个问题。问题被分成4类(前瞻性、技术性、恢复性、其他),并直接输入ChatGPT 40和谷歌Gemini 2.5(非付费版本)。对于每个问题,一个新的聊天开始,以防止任何继续的答案。三位审稿人使用两种经过验证的医疗保健工具:DISCERN(质量)和患者教育材料评估工具(可理解性和可操作性)独立审查了回复。结果:除了“其他”之外,双子座的平均辨别分数(总分80分)在所有领域都高于ChatGPT。前瞻性49.2对39.1;技术52.3 vs 44.3;复苏53.7比45.4;其他54.3对56.5;总体52.4 vs 45.8(图1)。两个平台的PEMAT-P可理解度均超过70%:预期80.0%对71.7%;技术面80.1%对79.8%;回收率79.2%对80.1%;其他79.2% vs 81.3%;总体为79.7%对78.1%(图2)。可操作性都很低;只有双子座在预期域达到了70%的阈值(图3)。图1 A每个回答的平均DISCERN得分(满分为5分)和标准差B每个问题类别和总体的平均总DISCERN得分(满分为80分)图表中的数字表示被四舍五入到最接近的整数,以便于解释。图形值仍然是真实值。[56.5用数字表示为57等....]图2 A每个回答的平均分PEMAT-P可理解性得分及其标准差B每个问题类别和总体的平均分PEMAT-P可理解性得分(70%的最小阈值被认为是“可理解的”)。图表中的数字表示被四舍五入到最接近的整数,以便于解释。图形值仍然是真实值。[71.70%用数字表示为72%,等....]图3 A每个回答的标准误差的PEMAT-P可操作性平均得分B每个问题类别和总体的PEMAT-P可操作性平均得分(70%是被认为是“可操作性”的回答的最低阈值)。图表中的数字表示被四舍五入到最接近的整数,以便于解释。图形值仍然是真实值。[65.40%用数字表示为65%等....]结论:ChatGPT和Gemini提供了与泌尿外科远程手术相关的相关且可理解的信息,Gemini提供的信息来源更一致。然而,这两个聊天机器人都不能可靠地提供可操作的响应,这限制了它们作为患者决策的独立网关的效用。
Introduction: With increasing accessibility to Artificial Intelligence (AI) chatbots, the precision and clarity of medical information provided require rigorous assessment. Urologic telesurgery represents a complex concept that patients will investigate using AI. We compared ChatGPT and Google Gemini in providing patient-facing information on urologic telesurgical procedures.
Methods: 19 questions related to urologic telesurgery were generated using general information from the American Urologic Association (AUA) and European Robotic Urology Section (ERUS). Questions were organized into 4 categories (Prospective, Technical, Recovery, Other) and directly typed into ChatGPT 4o and Google Gemini 2.5 (non-paid versions). For each question, a new chat was started to prevent any continuation of answers. Three reviewers independently reviewed the responses using two validated healthcare tools: DISCERN (quality) and Patient Education Material Assessment Tool (understandability and actionability).
Results: Mean DISCERN scores (out of 80) were higher for Gemini than ChatGPT in all domains except "Other". Prospective 49.2 versus 39.1; technical 52.3 versus 44.3; recovery 53.7 versus 45.4; other 54.3 versus 56.5; overall 52.4 versus 45.8 (Fig. 1). PEMAT-P understandability uniformly exceeded 70% for both platforms: prospective 80.0% versus 71.7%; technical 80.1% versus 79.8%; recovery 79.2% versus 80.1%; other 79.2% versus 81.3%; overall 79.7% versus 78.1% (Fig. 2). Actionability was uniformly low; only Gemini met the 70% threshold in the prospective domain (Fig. 3). Fig. 1 A Mean DISCERN scores (out of 5) with standard deviations for each response B Mean total DISCERN scores (out of 80) among each question category and overall. Numerical representation in the graph was rounded to the closest whole number for easier interpretation. Graphed value is still the true value. [56.5 represented numerically as 57, etc.…] Fig. 2 A Mean PEMAT-P Understandability scores with standard deviations for each response B Mean PEMAT-P Understandability scores among each question category and overall (70% minimum threshold for responses to be deemed "understandable"). Numerical representation in the graph was rounded to the closest whole number for easier interpretation. Graphed value is still the true value. [71.70% represented numerically as 72%, etc.…] Fig. 3 A Mean PEMAT-P Actionability scores with standard errors for each response B Mean PEMAT-P Actionability scores among each question category and overall (70% is the minimum threshold for responses to be deemed "actionable"). Numerical representation in the graph was rounded to the closest whole number for easier interpretation. The graphed value is still the true value. [65.40% represented numerically as 65%, etc.…] CONCLUSION: ChatGPT and Gemini deliver relevant and understandable information related to urologic telesurgery, with Gemini more consistently providing sources. However, neither chatbot reliably offers actionable responses, limiting their utility as a standalone gateway for patient decision-making.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


