Joshua Winograd, Autumn Kim, Nikit Venishetty, Alia Codelia-Anjum, Dean Elterman, Naeem Bhojani, Kevin C Zorn, Adithya Balasubramanian, Andrew Vickers, Bilal Chughtai
{"title":"MedReadr:浏览器内基于规则的自然语言处理算法的开发和评估,用于估计消费者健康文章的可靠性。","authors":"Joshua Winograd, Autumn Kim, Nikit Venishetty, Alia Codelia-Anjum, Dean Elterman, Naeem Bhojani, Kevin C Zorn, Adithya Balasubramanian, Andrew Vickers, Bilal Chughtai","doi":"10.1159/000548163","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>The internet is a major source of medical information for patients, yet the quality of online health content remains highly variable. Existing assessment tools are often labor-intensive, invalidated, or limited in scope. We developed and validated MedReadr, an in-browser, rule-based natural language processing (NLP) algorithm that automatically estimates the reliability of consumer health articles for patients and providers.</p><p><strong>Methods: </strong>Thirty-five consumer medical articles were independently assessed by two reviewers using validated manual scoring systems (QUEST and Sandvik). Interrater reliability was evaluated with Cohen's κ, and metrics with κ > 0.6 were selected for model fitting. MedReadr extracted key features from article text and metadata using predefined NLP rules. A multivariable linear regression model was trained to predict manual reliability scores, with internal validation performed on an independent set of 20 articles.</p><p><strong>Results: </strong>High interrater reliability was achieved across all QUEST and most Sandvik domains (Cohen's κ > 0.6). The MedReadr model demonstrated strong performance, achieving <i>R</i> <sup>2</sup> = 0.90 and RMSE = 0.05 on the development set and <i>R</i> <sup>2</sup> = 0.83 and RMSE = 0.07 on the validation set. All model coefficients were statistically significant (<i>p</i> < 0.05). Key predictive features included currency and reference scores, sentiment polarity, engagement content, and the frequency of provider contact, intervention endorsement, intervention mechanism, and intervention uncertainty phrases.</p><p><strong>Conclusion: </strong>MedReadr demonstrates that structural reliability scoring of online health articles can be automated using a transparent, rule-based NLP approach. Applied to English-language articles from mainstream search results on common medical conditions, the tool showed strong agreement with validated manual scoring systems. However, it has only been validated on a narrow scope of content and is not designed to analyze search results for specific questions or detect misinformation. Future research should assess its performance across a broader range of web content and evaluate whether its integration improves patient comprehension, digital health literacy, and clinician-patient communication.</p>","PeriodicalId":101351,"journal":{"name":"Biomedicine hub","volume":"10 1","pages":"162-170"},"PeriodicalIF":0.0000,"publicationDate":"2025-08-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12503773/pdf/","citationCount":"0","resultStr":"{\"title\":\"MedReadr: Development and Evaluation of an In-Browser, Rule-Based Natural Language Processing Algorithm to Estimate the Reliability of Consumer Health Articles.\",\"authors\":\"Joshua Winograd, Autumn Kim, Nikit Venishetty, Alia Codelia-Anjum, Dean Elterman, Naeem Bhojani, Kevin C Zorn, Adithya Balasubramanian, Andrew Vickers, Bilal Chughtai\",\"doi\":\"10.1159/000548163\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Introduction: </strong>The internet is a major source of medical information for patients, yet the quality of online health content remains highly variable. Existing assessment tools are often labor-intensive, invalidated, or limited in scope. We developed and validated MedReadr, an in-browser, rule-based natural language processing (NLP) algorithm that automatically estimates the reliability of consumer health articles for patients and providers.</p><p><strong>Methods: </strong>Thirty-five consumer medical articles were independently assessed by two reviewers using validated manual scoring systems (QUEST and Sandvik). Interrater reliability was evaluated with Cohen's κ, and metrics with κ > 0.6 were selected for model fitting. MedReadr extracted key features from article text and metadata using predefined NLP rules. A multivariable linear regression model was trained to predict manual reliability scores, with internal validation performed on an independent set of 20 articles.</p><p><strong>Results: </strong>High interrater reliability was achieved across all QUEST and most Sandvik domains (Cohen's κ > 0.6). The MedReadr model demonstrated strong performance, achieving <i>R</i> <sup>2</sup> = 0.90 and RMSE = 0.05 on the development set and <i>R</i> <sup>2</sup> = 0.83 and RMSE = 0.07 on the validation set. All model coefficients were statistically significant (<i>p</i> < 0.05). Key predictive features included currency and reference scores, sentiment polarity, engagement content, and the frequency of provider contact, intervention endorsement, intervention mechanism, and intervention uncertainty phrases.</p><p><strong>Conclusion: </strong>MedReadr demonstrates that structural reliability scoring of online health articles can be automated using a transparent, rule-based NLP approach. Applied to English-language articles from mainstream search results on common medical conditions, the tool showed strong agreement with validated manual scoring systems. However, it has only been validated on a narrow scope of content and is not designed to analyze search results for specific questions or detect misinformation. Future research should assess its performance across a broader range of web content and evaluate whether its integration improves patient comprehension, digital health literacy, and clinician-patient communication.</p>\",\"PeriodicalId\":101351,\"journal\":{\"name\":\"Biomedicine hub\",\"volume\":\"10 1\",\"pages\":\"162-170\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2025-08-25\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12503773/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biomedicine hub\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1159/000548163\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biomedicine hub","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1159/000548163","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
MedReadr: Development and Evaluation of an In-Browser, Rule-Based Natural Language Processing Algorithm to Estimate the Reliability of Consumer Health Articles.
Introduction: The internet is a major source of medical information for patients, yet the quality of online health content remains highly variable. Existing assessment tools are often labor-intensive, invalidated, or limited in scope. We developed and validated MedReadr, an in-browser, rule-based natural language processing (NLP) algorithm that automatically estimates the reliability of consumer health articles for patients and providers.
Methods: Thirty-five consumer medical articles were independently assessed by two reviewers using validated manual scoring systems (QUEST and Sandvik). Interrater reliability was evaluated with Cohen's κ, and metrics with κ > 0.6 were selected for model fitting. MedReadr extracted key features from article text and metadata using predefined NLP rules. A multivariable linear regression model was trained to predict manual reliability scores, with internal validation performed on an independent set of 20 articles.
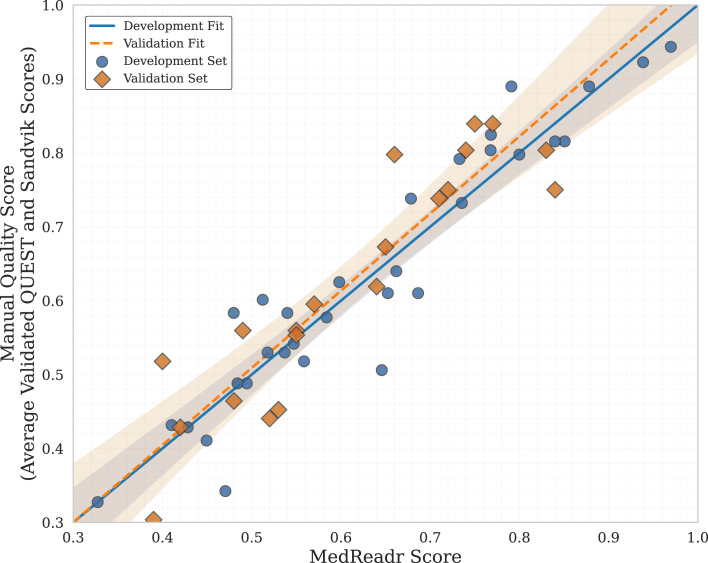
Results: High interrater reliability was achieved across all QUEST and most Sandvik domains (Cohen's κ > 0.6). The MedReadr model demonstrated strong performance, achieving R2 = 0.90 and RMSE = 0.05 on the development set and R2 = 0.83 and RMSE = 0.07 on the validation set. All model coefficients were statistically significant (p < 0.05). Key predictive features included currency and reference scores, sentiment polarity, engagement content, and the frequency of provider contact, intervention endorsement, intervention mechanism, and intervention uncertainty phrases.
Conclusion: MedReadr demonstrates that structural reliability scoring of online health articles can be automated using a transparent, rule-based NLP approach. Applied to English-language articles from mainstream search results on common medical conditions, the tool showed strong agreement with validated manual scoring systems. However, it has only been validated on a narrow scope of content and is not designed to analyze search results for specific questions or detect misinformation. Future research should assess its performance across a broader range of web content and evaluate whether its integration improves patient comprehension, digital health literacy, and clinician-patient communication.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


