{"title":"生成对抗网络增强的异构集成学习用于co2 -甲醇催化剂性能的可解释预测","authors":"Qingchun Yang, , , Dongwen Rong, , , Zhao Wang, , , Qiwen Guo, , , Jingsong Guan, , , Yichun Dong, , and , Huairong Zhou*, ","doi":"10.1021/acs.iecr.5c02507","DOIUrl":null,"url":null,"abstract":"<p >Accurate prediction of catalyst performance in CO<sub>2</sub>-to-methanol (CTM) conversion remains challenging due to the scarcity of experimental data and the complexity of feature interactions. To address these issues, this study proposes an interpretable gene-adversarial network-enhanced heterogeneous ensemble modeling (GAN-HEM) framework. It integrates four synergistic key functional modules: data augmentation, feature interaction analysis, ensemble modeling, and interpretable analysis. Comparing the variational autoencoder-based data augmentation method demonstrates that the GAN has significant advantages in maintaining the global consistency and local geometric features of the data manifold structure. After the multivariate evaluation of feature association within the hybrid data set, it was found that retaining all the identified CTM catalyst features is beneficial for enhancing the predictive accuracy and generalization ability of the prediction model. Therefore, this data set is further applied to develop various homogeneous and heterogeneous ensemble learning models of the CTM process. The hyperparameters of these models are automatically optimized using the Bayesian algorithm-based Optuna approach. Results indicated that the optimized heterogeneous ensemble learning architecture has the highest prediction accuracy (<i>R</i><sup>2</sup> = 0.9314 and RMSE = 0.2636), significantly outperforming homogeneous models through its capacity to capture complex nonlinear feature interactions. The Shapley additive explanation-based interpretability analysis identifies reaction temperature as the dominant feature (>39% contribution). Partial dependence plots reveal competitive selectivity: higher temperature favors CO (thermodynamic constraints), while increased pressure and heating rate enhance methanol selectivity (kinetic promotion). This framework accelerates CTM catalyst discovery and optimization, providing high-fidelity prediction and actionable design insights.</p>","PeriodicalId":39,"journal":{"name":"Industrial & Engineering Chemistry Research","volume":"64 41","pages":"19797–19816"},"PeriodicalIF":3.9000,"publicationDate":"2025-10-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Generative Adversarial Network-Enhanced Heterogeneous Ensemble Learning for Interpretable Prediction of CO2-to-Methanol Catalyst Performance\",\"authors\":\"Qingchun Yang, , , Dongwen Rong, , , Zhao Wang, , , Qiwen Guo, , , Jingsong Guan, , , Yichun Dong, , and , Huairong Zhou*, \",\"doi\":\"10.1021/acs.iecr.5c02507\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p >Accurate prediction of catalyst performance in CO<sub>2</sub>-to-methanol (CTM) conversion remains challenging due to the scarcity of experimental data and the complexity of feature interactions. To address these issues, this study proposes an interpretable gene-adversarial network-enhanced heterogeneous ensemble modeling (GAN-HEM) framework. It integrates four synergistic key functional modules: data augmentation, feature interaction analysis, ensemble modeling, and interpretable analysis. Comparing the variational autoencoder-based data augmentation method demonstrates that the GAN has significant advantages in maintaining the global consistency and local geometric features of the data manifold structure. After the multivariate evaluation of feature association within the hybrid data set, it was found that retaining all the identified CTM catalyst features is beneficial for enhancing the predictive accuracy and generalization ability of the prediction model. Therefore, this data set is further applied to develop various homogeneous and heterogeneous ensemble learning models of the CTM process. The hyperparameters of these models are automatically optimized using the Bayesian algorithm-based Optuna approach. Results indicated that the optimized heterogeneous ensemble learning architecture has the highest prediction accuracy (<i>R</i><sup>2</sup> = 0.9314 and RMSE = 0.2636), significantly outperforming homogeneous models through its capacity to capture complex nonlinear feature interactions. The Shapley additive explanation-based interpretability analysis identifies reaction temperature as the dominant feature (>39% contribution). Partial dependence plots reveal competitive selectivity: higher temperature favors CO (thermodynamic constraints), while increased pressure and heating rate enhance methanol selectivity (kinetic promotion). This framework accelerates CTM catalyst discovery and optimization, providing high-fidelity prediction and actionable design insights.</p>\",\"PeriodicalId\":39,\"journal\":{\"name\":\"Industrial & Engineering Chemistry Research\",\"volume\":\"64 41\",\"pages\":\"19797–19816\"},\"PeriodicalIF\":3.9000,\"publicationDate\":\"2025-10-06\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Industrial & Engineering Chemistry Research\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://pubs.acs.org/doi/10.1021/acs.iecr.5c02507\",\"RegionNum\":3,\"RegionCategory\":\"工程技术\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"ENGINEERING, CHEMICAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Industrial & Engineering Chemistry Research","FirstCategoryId":"5","ListUrlMain":"https://pubs.acs.org/doi/10.1021/acs.iecr.5c02507","RegionNum":3,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"ENGINEERING, CHEMICAL","Score":null,"Total":0}
Generative Adversarial Network-Enhanced Heterogeneous Ensemble Learning for Interpretable Prediction of CO2-to-Methanol Catalyst Performance
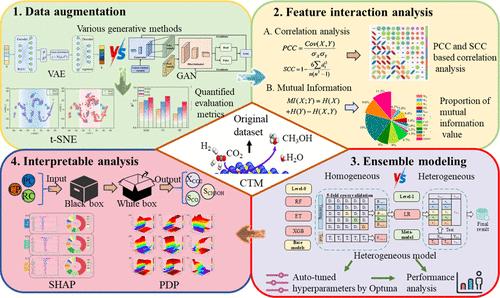
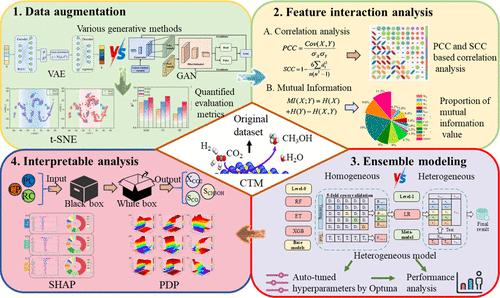
Accurate prediction of catalyst performance in CO2-to-methanol (CTM) conversion remains challenging due to the scarcity of experimental data and the complexity of feature interactions. To address these issues, this study proposes an interpretable gene-adversarial network-enhanced heterogeneous ensemble modeling (GAN-HEM) framework. It integrates four synergistic key functional modules: data augmentation, feature interaction analysis, ensemble modeling, and interpretable analysis. Comparing the variational autoencoder-based data augmentation method demonstrates that the GAN has significant advantages in maintaining the global consistency and local geometric features of the data manifold structure. After the multivariate evaluation of feature association within the hybrid data set, it was found that retaining all the identified CTM catalyst features is beneficial for enhancing the predictive accuracy and generalization ability of the prediction model. Therefore, this data set is further applied to develop various homogeneous and heterogeneous ensemble learning models of the CTM process. The hyperparameters of these models are automatically optimized using the Bayesian algorithm-based Optuna approach. Results indicated that the optimized heterogeneous ensemble learning architecture has the highest prediction accuracy (R2 = 0.9314 and RMSE = 0.2636), significantly outperforming homogeneous models through its capacity to capture complex nonlinear feature interactions. The Shapley additive explanation-based interpretability analysis identifies reaction temperature as the dominant feature (>39% contribution). Partial dependence plots reveal competitive selectivity: higher temperature favors CO (thermodynamic constraints), while increased pressure and heating rate enhance methanol selectivity (kinetic promotion). This framework accelerates CTM catalyst discovery and optimization, providing high-fidelity prediction and actionable design insights.
期刊介绍:
ndustrial & Engineering Chemistry, with variations in title and format, has been published since 1909 by the American Chemical Society. Industrial & Engineering Chemistry Research is a weekly publication that reports industrial and academic research in the broad fields of applied chemistry and chemical engineering with special focus on fundamentals, processes, and products.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


