Cheng-Peng Li, Yuan Chu, Wei-Wei Jia, Priska Hakenberg, Flavius Șandra-Petrescu, Christoph Reißfelder, Cui Yang
{"title":"重拳出击:Deepseek-R1和openai - 01在胰腺腺癌相关问题上的正面比较","authors":"Cheng-Peng Li, Yuan Chu, Wei-Wei Jia, Priska Hakenberg, Flavius Șandra-Petrescu, Christoph Reißfelder, Cui Yang","doi":"10.7150/ijms.118887","DOIUrl":null,"url":null,"abstract":"<p><p><b>Objective:</b> This study aimed to compare the performance of DeepSeek-R1 and OpenAI-o1 in addressing complex pancreatic ductal adenocarcinoma (PDAC)-related clinical questions, focusing on accuracy, comprehensiveness, safety, and reasoning quality. <b>Methods:</b> Twenty PDAC-related questions derived from the up-to-date NCCN guidelines for PDAC were posed to both models. Responses were evaluated for accuracy, comprehensiveness, and safety, and chain-of-thought (CoT) outputs were rated for logical coherence and error handling by blinded clinical experts using 5-point Likert scales. Inter-rater reliability, evaluated scores, and character counts by both models were compared. <b>Results:</b> Both models demonstrated high accuracy (median score: 5 vs. 5, p=0.527) and safety (5 vs. 5, p=0.285). DeepSeek-R1 outperformed OpenAI-o1 in comprehensiveness (median: 5 vs. 4.5, p=0.015) and generated significantly longer responses (median characters: 544 vs. 248, p<0.001). For reasoning quality, DeepSeek-R1 achieved superior scores in logical coherence (median: 5 vs. 4, p<0.001) and error handling (5 vs. 4, p<0.001), with 75% of its responses scoring full points compared to OpenAI-o1's 5%. <b>Conclusion:</b> While both models exhibit high clinical utility, DeepSeek-R1's enhanced reasoning capabilities, open-source nature, and cost-effectiveness position it as a promising tool for complex oncology decision support. Further validation in real-world multimodal clinical scenarios is warranted.</p>","PeriodicalId":14031,"journal":{"name":"International Journal of Medical Sciences","volume":"22 15","pages":"3868-3877"},"PeriodicalIF":3.2000,"publicationDate":"2025-08-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12492379/pdf/","citationCount":"0","resultStr":"{\"title\":\"Punching Above Its Weight: A Head-to-Head Comparison of Deepseek-R1 and OpenAI-o1 on Pancreatic Adenocarcinoma-Related Questions.\",\"authors\":\"Cheng-Peng Li, Yuan Chu, Wei-Wei Jia, Priska Hakenberg, Flavius Șandra-Petrescu, Christoph Reißfelder, Cui Yang\",\"doi\":\"10.7150/ijms.118887\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p><b>Objective:</b> This study aimed to compare the performance of DeepSeek-R1 and OpenAI-o1 in addressing complex pancreatic ductal adenocarcinoma (PDAC)-related clinical questions, focusing on accuracy, comprehensiveness, safety, and reasoning quality. <b>Methods:</b> Twenty PDAC-related questions derived from the up-to-date NCCN guidelines for PDAC were posed to both models. Responses were evaluated for accuracy, comprehensiveness, and safety, and chain-of-thought (CoT) outputs were rated for logical coherence and error handling by blinded clinical experts using 5-point Likert scales. Inter-rater reliability, evaluated scores, and character counts by both models were compared. <b>Results:</b> Both models demonstrated high accuracy (median score: 5 vs. 5, p=0.527) and safety (5 vs. 5, p=0.285). DeepSeek-R1 outperformed OpenAI-o1 in comprehensiveness (median: 5 vs. 4.5, p=0.015) and generated significantly longer responses (median characters: 544 vs. 248, p<0.001). For reasoning quality, DeepSeek-R1 achieved superior scores in logical coherence (median: 5 vs. 4, p<0.001) and error handling (5 vs. 4, p<0.001), with 75% of its responses scoring full points compared to OpenAI-o1's 5%. <b>Conclusion:</b> While both models exhibit high clinical utility, DeepSeek-R1's enhanced reasoning capabilities, open-source nature, and cost-effectiveness position it as a promising tool for complex oncology decision support. Further validation in real-world multimodal clinical scenarios is warranted.</p>\",\"PeriodicalId\":14031,\"journal\":{\"name\":\"International Journal of Medical Sciences\",\"volume\":\"22 15\",\"pages\":\"3868-3877\"},\"PeriodicalIF\":3.2000,\"publicationDate\":\"2025-08-22\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12492379/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"International Journal of Medical Sciences\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.7150/ijms.118887\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q1\",\"JCRName\":\"MEDICINE, GENERAL & INTERNAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Medical Sciences","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.7150/ijms.118887","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"MEDICINE, GENERAL & INTERNAL","Score":null,"Total":0}
Punching Above Its Weight: A Head-to-Head Comparison of Deepseek-R1 and OpenAI-o1 on Pancreatic Adenocarcinoma-Related Questions.
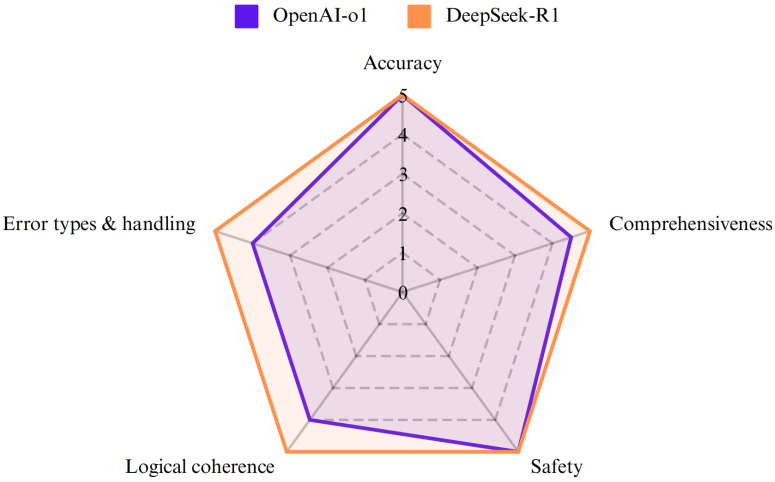
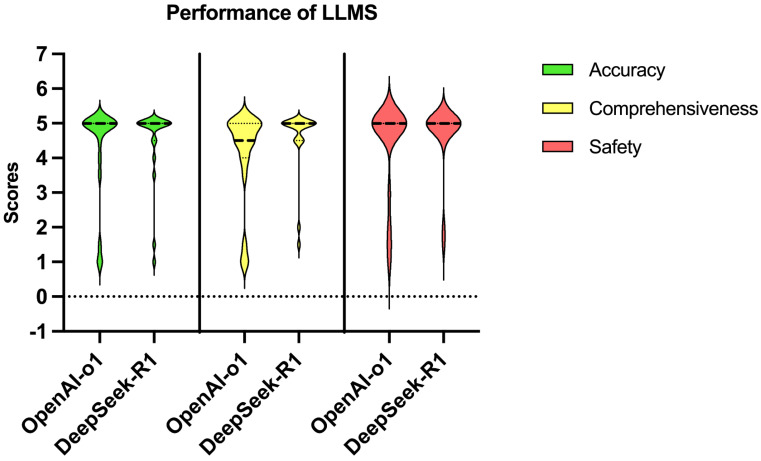
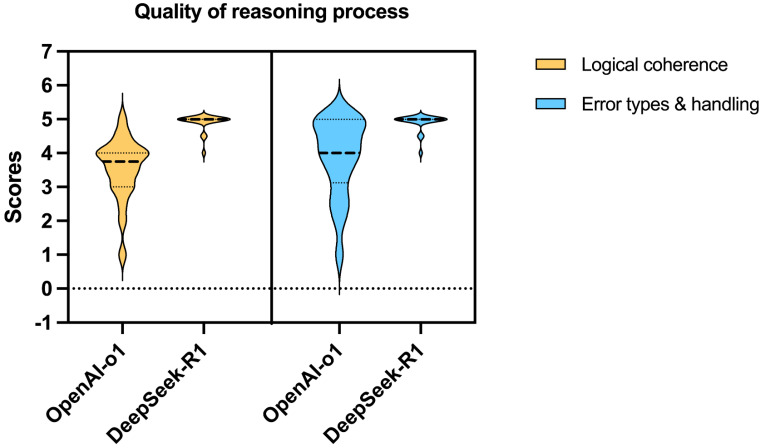
Objective: This study aimed to compare the performance of DeepSeek-R1 and OpenAI-o1 in addressing complex pancreatic ductal adenocarcinoma (PDAC)-related clinical questions, focusing on accuracy, comprehensiveness, safety, and reasoning quality. Methods: Twenty PDAC-related questions derived from the up-to-date NCCN guidelines for PDAC were posed to both models. Responses were evaluated for accuracy, comprehensiveness, and safety, and chain-of-thought (CoT) outputs were rated for logical coherence and error handling by blinded clinical experts using 5-point Likert scales. Inter-rater reliability, evaluated scores, and character counts by both models were compared. Results: Both models demonstrated high accuracy (median score: 5 vs. 5, p=0.527) and safety (5 vs. 5, p=0.285). DeepSeek-R1 outperformed OpenAI-o1 in comprehensiveness (median: 5 vs. 4.5, p=0.015) and generated significantly longer responses (median characters: 544 vs. 248, p<0.001). For reasoning quality, DeepSeek-R1 achieved superior scores in logical coherence (median: 5 vs. 4, p<0.001) and error handling (5 vs. 4, p<0.001), with 75% of its responses scoring full points compared to OpenAI-o1's 5%. Conclusion: While both models exhibit high clinical utility, DeepSeek-R1's enhanced reasoning capabilities, open-source nature, and cost-effectiveness position it as a promising tool for complex oncology decision support. Further validation in real-world multimodal clinical scenarios is warranted.
期刊介绍:
Original research papers, reviews, and short research communications in any medical related area can be submitted to the Journal on the understanding that the work has not been published previously in whole or part and is not under consideration for publication elsewhere. Manuscripts in basic science and clinical medicine are both considered. There is no restriction on the length of research papers and reviews, although authors are encouraged to be concise. Short research communication is limited to be under 2500 words.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


