{"title":"机器翻译中文本预处理的语言模型","authors":"A. V. Mylnikova, L. A. Mylnikov","doi":"10.3103/S0005105525700645","DOIUrl":null,"url":null,"abstract":"<p>This paper examines a model for the use of syntactic parsing-based text skeleton structures for the preprocessing of text corpora before they are transferred to MT neural network models to enhance their performance quality. In the paper, a model is suggested for text corpora, which is based on parts-of-speech (POS) tagging and syntactic parsing; this model is implemented on BERT network-based language model and a set of rules. A limited POS tagging dataset is taken in this paper to describe how data are prepared for the training of the model and how its efficiency performance can be improved. POS tagging is used in the paper to obtain syntactic parsing and determine the type of a sentence and word order changes according to the predefined rules. The application of the model, suggested in the paper, together with the MT language models Google and Yandex, allowed MT quality metrics to be increased by 0.1–0.23 according to BLEU and TER for Russian–English and German–English language pairs.</p>","PeriodicalId":42995,"journal":{"name":"AUTOMATIC DOCUMENTATION AND MATHEMATICAL LINGUISTICS","volume":"59 4","pages":"256 - 268"},"PeriodicalIF":0.5000,"publicationDate":"2025-10-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Language Models for Texts Preprocessing in Machine Translation\",\"authors\":\"A. V. Mylnikova, L. A. Mylnikov\",\"doi\":\"10.3103/S0005105525700645\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>This paper examines a model for the use of syntactic parsing-based text skeleton structures for the preprocessing of text corpora before they are transferred to MT neural network models to enhance their performance quality. In the paper, a model is suggested for text corpora, which is based on parts-of-speech (POS) tagging and syntactic parsing; this model is implemented on BERT network-based language model and a set of rules. A limited POS tagging dataset is taken in this paper to describe how data are prepared for the training of the model and how its efficiency performance can be improved. POS tagging is used in the paper to obtain syntactic parsing and determine the type of a sentence and word order changes according to the predefined rules. The application of the model, suggested in the paper, together with the MT language models Google and Yandex, allowed MT quality metrics to be increased by 0.1–0.23 according to BLEU and TER for Russian–English and German–English language pairs.</p>\",\"PeriodicalId\":42995,\"journal\":{\"name\":\"AUTOMATIC DOCUMENTATION AND MATHEMATICAL LINGUISTICS\",\"volume\":\"59 4\",\"pages\":\"256 - 268\"},\"PeriodicalIF\":0.5000,\"publicationDate\":\"2025-10-06\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"AUTOMATIC DOCUMENTATION AND MATHEMATICAL LINGUISTICS\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://link.springer.com/article/10.3103/S0005105525700645\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q4\",\"JCRName\":\"COMPUTER SCIENCE, INFORMATION SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"AUTOMATIC DOCUMENTATION AND MATHEMATICAL LINGUISTICS","FirstCategoryId":"1085","ListUrlMain":"https://link.springer.com/article/10.3103/S0005105525700645","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
Language Models for Texts Preprocessing in Machine Translation
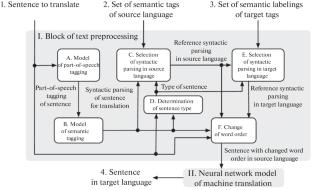
This paper examines a model for the use of syntactic parsing-based text skeleton structures for the preprocessing of text corpora before they are transferred to MT neural network models to enhance their performance quality. In the paper, a model is suggested for text corpora, which is based on parts-of-speech (POS) tagging and syntactic parsing; this model is implemented on BERT network-based language model and a set of rules. A limited POS tagging dataset is taken in this paper to describe how data are prepared for the training of the model and how its efficiency performance can be improved. POS tagging is used in the paper to obtain syntactic parsing and determine the type of a sentence and word order changes according to the predefined rules. The application of the model, suggested in the paper, together with the MT language models Google and Yandex, allowed MT quality metrics to be increased by 0.1–0.23 according to BLEU and TER for Russian–English and German–English language pairs.
期刊介绍:
Automatic Documentation and Mathematical Linguistics is an international peer reviewed journal that covers all aspects of automation of information processes and systems, as well as algorithms and methods for automatic language analysis. Emphasis is on the practical applications of new technologies and techniques for information analysis and processing.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


