Noriyuki Okuyama, Mika Ishii, Yuriko Fukuoka, Hiromitsu Hattori, Yuta Kasahara, Tai Toshihiro, Koki Yoshinaga, Tomoko Hashimoto, Koichi Kyono
{"title":"大语言模型在辅助生殖技术数据分析和医学教育中的应用:比较研究。","authors":"Noriyuki Okuyama, Mika Ishii, Yuriko Fukuoka, Hiromitsu Hattori, Yuta Kasahara, Tai Toshihiro, Koki Yoshinaga, Tomoko Hashimoto, Koichi Kyono","doi":"10.2196/70107","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Recent studies have demonstrated that large language models exhibit exceptional performance in medical examinations. However, there is a lack of reports assessing their capabilities in specific domains or their application in practical data analysis using code interpreters. Furthermore, comparative analyses across different large language models have not been extensively conducted.</p><p><strong>Objective: </strong>The purpose of this study was to evaluate whether advanced artificial intelligence (AI) models can analyze data from template-based input and demonstrate basic knowledge of reproductive medicine. Four AI models (GPT-4, GPT-4o, Claude 3.5 Sonnet, and Gemini Pro 1.5) were evaluated for their data analytical capabilities through numerical calculations and graph rendering. Their knowledge of infertility treatment was assessed using 10 examination questions developed by experts.</p><p><strong>Methods: </strong>First, we uploaded data to the AI models and furnished instruction templates using the chat interface. The study investigated whether the AI models could perform pregnancy rate analysis and graph rendering, based on blastocyst grades according to Gardner criteria. Second, we assessed model diagnostic capabilities based on specialized knowledge. This evaluation used 10 questions derived from the Japanese Fertility Specialist Examination and the Embryologist Certification Exam, along with chromosome imaging. These materials were curated under the supervision of certified embryologists and fertility specialists. All procedures were repeated 10 times per AI model.</p><p><strong>Results: </strong>GPT-4o achieved grade A output (defined as achieving the objective with a single output attempt) in 9 out of 10 trials, outperforming GPT-4, which achieved grade A in 7 out of 10. The average processing times for data analysis were 26.8 (SD 3.7) seconds for GPT-4o and 36.7 (SD 3) seconds for GPT-4, whereas Claude failed in all 10 attempts. Gemini achieved an average processing time of 23 (SD 3) seconds and received grade A in 6 out of 10 trials, though occasional manual corrections were needed. Embryologists required an average of 358.3 (SD 9.7) seconds for the same tasks. In the knowledge-based assessment, GPT-4o, Claude, and Gemini achieved perfect scores (9/9) on multiple-choice questions, while GPT-4 showed a 60% (6/10) success rate on 1 question. None of the AI models could reliably diagnose chromosomal abnormalities from karyotype images, with the highest image diagnostic accuracy being 70% (7/10) for Claude and Gemini.</p><p><strong>Conclusions: </strong>This rapid processing demonstrates the potential for these AI models to significantly expedite data-intensive tasks in clinical settings. This performance underscores their potential utility as educational tools or decision support systems in reproductive medicine. However, none of the models were able to accurately interpret and diagnose using medical images.</p>","PeriodicalId":14841,"journal":{"name":"JMIR Formative Research","volume":"9 ","pages":"e70107"},"PeriodicalIF":2.0000,"publicationDate":"2025-10-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12488165/pdf/","citationCount":"0","resultStr":"{\"title\":\"Application of Large Language Models in Data Analysis and Medical Education for Assisted Reproductive Technology: Comparative Study.\",\"authors\":\"Noriyuki Okuyama, Mika Ishii, Yuriko Fukuoka, Hiromitsu Hattori, Yuta Kasahara, Tai Toshihiro, Koki Yoshinaga, Tomoko Hashimoto, Koichi Kyono\",\"doi\":\"10.2196/70107\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Recent studies have demonstrated that large language models exhibit exceptional performance in medical examinations. However, there is a lack of reports assessing their capabilities in specific domains or their application in practical data analysis using code interpreters. Furthermore, comparative analyses across different large language models have not been extensively conducted.</p><p><strong>Objective: </strong>The purpose of this study was to evaluate whether advanced artificial intelligence (AI) models can analyze data from template-based input and demonstrate basic knowledge of reproductive medicine. Four AI models (GPT-4, GPT-4o, Claude 3.5 Sonnet, and Gemini Pro 1.5) were evaluated for their data analytical capabilities through numerical calculations and graph rendering. Their knowledge of infertility treatment was assessed using 10 examination questions developed by experts.</p><p><strong>Methods: </strong>First, we uploaded data to the AI models and furnished instruction templates using the chat interface. The study investigated whether the AI models could perform pregnancy rate analysis and graph rendering, based on blastocyst grades according to Gardner criteria. Second, we assessed model diagnostic capabilities based on specialized knowledge. This evaluation used 10 questions derived from the Japanese Fertility Specialist Examination and the Embryologist Certification Exam, along with chromosome imaging. These materials were curated under the supervision of certified embryologists and fertility specialists. All procedures were repeated 10 times per AI model.</p><p><strong>Results: </strong>GPT-4o achieved grade A output (defined as achieving the objective with a single output attempt) in 9 out of 10 trials, outperforming GPT-4, which achieved grade A in 7 out of 10. The average processing times for data analysis were 26.8 (SD 3.7) seconds for GPT-4o and 36.7 (SD 3) seconds for GPT-4, whereas Claude failed in all 10 attempts. Gemini achieved an average processing time of 23 (SD 3) seconds and received grade A in 6 out of 10 trials, though occasional manual corrections were needed. Embryologists required an average of 358.3 (SD 9.7) seconds for the same tasks. In the knowledge-based assessment, GPT-4o, Claude, and Gemini achieved perfect scores (9/9) on multiple-choice questions, while GPT-4 showed a 60% (6/10) success rate on 1 question. None of the AI models could reliably diagnose chromosomal abnormalities from karyotype images, with the highest image diagnostic accuracy being 70% (7/10) for Claude and Gemini.</p><p><strong>Conclusions: </strong>This rapid processing demonstrates the potential for these AI models to significantly expedite data-intensive tasks in clinical settings. This performance underscores their potential utility as educational tools or decision support systems in reproductive medicine. However, none of the models were able to accurately interpret and diagnose using medical images.</p>\",\"PeriodicalId\":14841,\"journal\":{\"name\":\"JMIR Formative Research\",\"volume\":\"9 \",\"pages\":\"e70107\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2025-10-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12488165/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR Formative Research\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/70107\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Formative Research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/70107","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Application of Large Language Models in Data Analysis and Medical Education for Assisted Reproductive Technology: Comparative Study.
Background: Recent studies have demonstrated that large language models exhibit exceptional performance in medical examinations. However, there is a lack of reports assessing their capabilities in specific domains or their application in practical data analysis using code interpreters. Furthermore, comparative analyses across different large language models have not been extensively conducted.
Objective: The purpose of this study was to evaluate whether advanced artificial intelligence (AI) models can analyze data from template-based input and demonstrate basic knowledge of reproductive medicine. Four AI models (GPT-4, GPT-4o, Claude 3.5 Sonnet, and Gemini Pro 1.5) were evaluated for their data analytical capabilities through numerical calculations and graph rendering. Their knowledge of infertility treatment was assessed using 10 examination questions developed by experts.
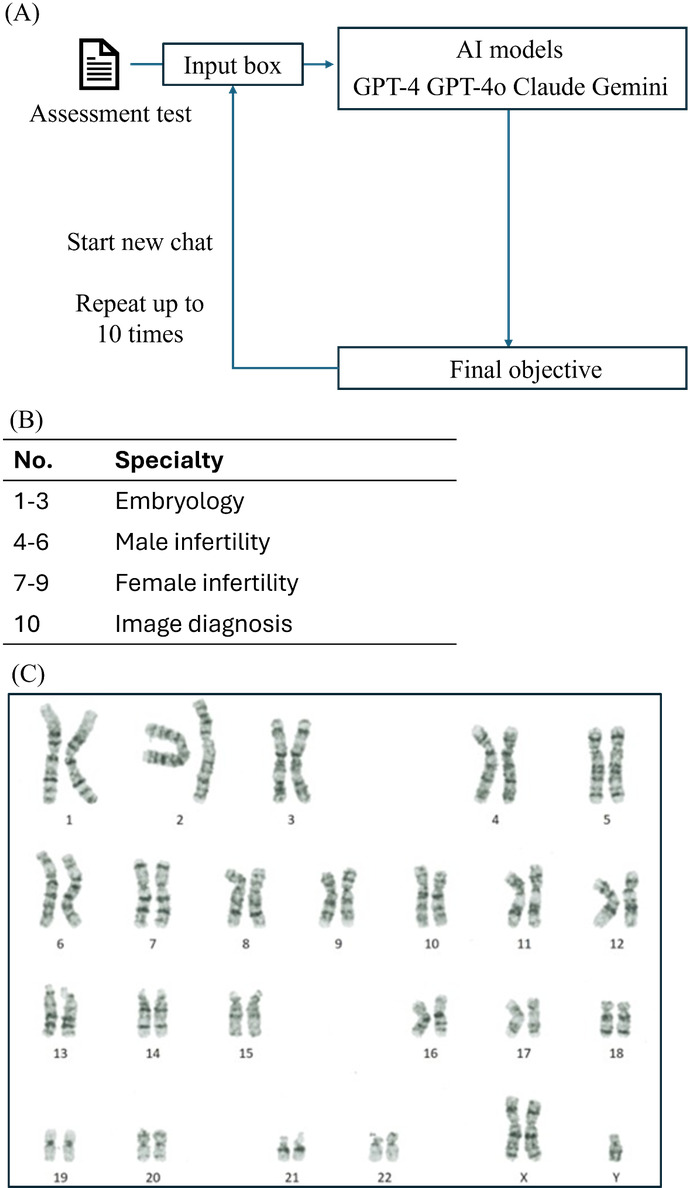
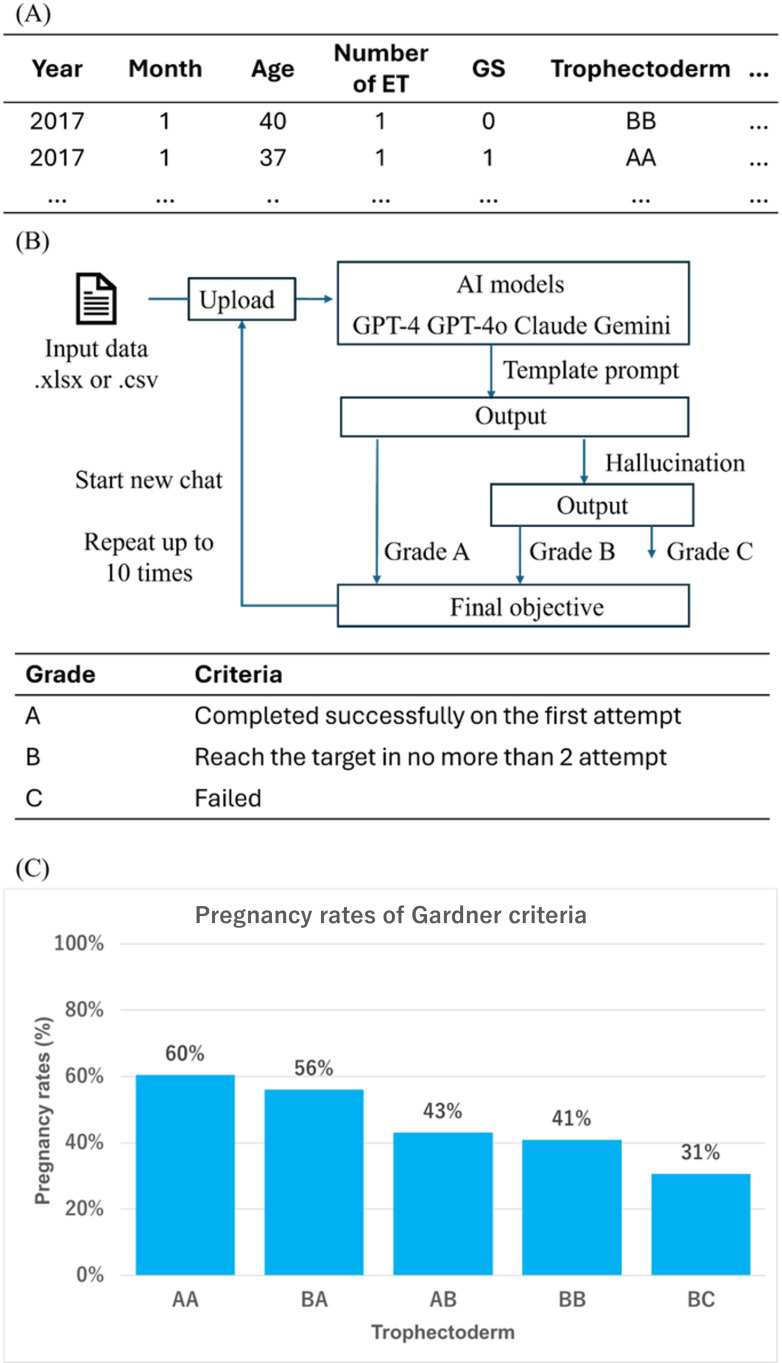
Methods: First, we uploaded data to the AI models and furnished instruction templates using the chat interface. The study investigated whether the AI models could perform pregnancy rate analysis and graph rendering, based on blastocyst grades according to Gardner criteria. Second, we assessed model diagnostic capabilities based on specialized knowledge. This evaluation used 10 questions derived from the Japanese Fertility Specialist Examination and the Embryologist Certification Exam, along with chromosome imaging. These materials were curated under the supervision of certified embryologists and fertility specialists. All procedures were repeated 10 times per AI model.
Results: GPT-4o achieved grade A output (defined as achieving the objective with a single output attempt) in 9 out of 10 trials, outperforming GPT-4, which achieved grade A in 7 out of 10. The average processing times for data analysis were 26.8 (SD 3.7) seconds for GPT-4o and 36.7 (SD 3) seconds for GPT-4, whereas Claude failed in all 10 attempts. Gemini achieved an average processing time of 23 (SD 3) seconds and received grade A in 6 out of 10 trials, though occasional manual corrections were needed. Embryologists required an average of 358.3 (SD 9.7) seconds for the same tasks. In the knowledge-based assessment, GPT-4o, Claude, and Gemini achieved perfect scores (9/9) on multiple-choice questions, while GPT-4 showed a 60% (6/10) success rate on 1 question. None of the AI models could reliably diagnose chromosomal abnormalities from karyotype images, with the highest image diagnostic accuracy being 70% (7/10) for Claude and Gemini.
Conclusions: This rapid processing demonstrates the potential for these AI models to significantly expedite data-intensive tasks in clinical settings. This performance underscores their potential utility as educational tools or decision support systems in reproductive medicine. However, none of the models were able to accurately interpret and diagnose using medical images.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


