{"title":"基于大型语言模型的半结构化web文章的高通量生物医学关系提取。","authors":"Songchi Zhou, Sheng Yu","doi":"10.1186/s12911-025-03204-3","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>We aim to develop a high-throughput biomedical relation extraction system tailored for semi-structured biomedical websites, leveraging the reading comprehension abilities and domain-specific medical knowledge of large language models (LLMs).</p><p><strong>Methods: </strong>We formulate relation extraction as a series of binary classification problems. Given the context from semi-structured biomedical web articles, LLMs decide whether a relation holds while providing accompanying rationales for factual verification. The article's main title is designated as the tail entity, and candidate head entities are identified by matching against a biomedical thesaurus with semantic typing to guide candidate relation types. To assess system performance and robustness, we compare general-purpose, domain-adapted, and parameter-efficient LLMs on an expert-curated benchmark, evaluating their relative effectiveness in extracting relations from semi-structured biomedical websites.</p><p><strong>Results: </strong>Domain-adapted models consistently outperform their general-purpose counterparts. Specifically, MedGemma-27B achieves an F1 score of 0.820 and Cohen's Kappa of 0.677, representing clear improvements over its base model Gemma3-27B (F1 = 0.771, Kappa = 0.604). Notably, MedGemma-27B also surpasses OpenAI's GPT-4o (F1 = 0.708, Kappa = 0.561) and GPT-4.1 (F1 = 0.732, Kappa = 0.597), demonstrating the advantage of biomedical domain adaptation even over stronger proprietary models. Among all evaluated models, DeepSeek-V3 yields the best overall performance (F1 = 0.844, Kappa = 0.730). Using MedGemma-27B, we extracted 225,799 relation triplets across three relation types from three authoritative biomedical websites. Case studies further highlight both the strengths and persistent challenges of different LLM classes in biomedical relation extraction from semi-structured content.</p><p><strong>Conclusion: </strong>Our study demonstrates that LLMs can serve as effective engines for high-throughput biomedical relation extraction, with domain-adapted and parameter-efficient models offering practical advantages. The framework is scalable and broadly adaptable, enabling efficient extraction of diverse biomedical relations across heterogeneous semi-structured websites. Beyond technical performance, the ability to extract reliable biomedical relations at scale can directly benefit clinical applications, such as enriching biomedical knowledge graphs, supporting evidence-based guideline development, and ultimately assisting clinicians in accessing structured medical knowledge for decision-making.</p>","PeriodicalId":9340,"journal":{"name":"BMC Medical Informatics and Decision Making","volume":"25 1","pages":"351"},"PeriodicalIF":3.8000,"publicationDate":"2025-09-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12482089/pdf/","citationCount":"0","resultStr":"{\"title\":\"High-throughput biomedical relation extraction for semi-structured web articles empowered by large language models.\",\"authors\":\"Songchi Zhou, Sheng Yu\",\"doi\":\"10.1186/s12911-025-03204-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>We aim to develop a high-throughput biomedical relation extraction system tailored for semi-structured biomedical websites, leveraging the reading comprehension abilities and domain-specific medical knowledge of large language models (LLMs).</p><p><strong>Methods: </strong>We formulate relation extraction as a series of binary classification problems. Given the context from semi-structured biomedical web articles, LLMs decide whether a relation holds while providing accompanying rationales for factual verification. The article's main title is designated as the tail entity, and candidate head entities are identified by matching against a biomedical thesaurus with semantic typing to guide candidate relation types. To assess system performance and robustness, we compare general-purpose, domain-adapted, and parameter-efficient LLMs on an expert-curated benchmark, evaluating their relative effectiveness in extracting relations from semi-structured biomedical websites.</p><p><strong>Results: </strong>Domain-adapted models consistently outperform their general-purpose counterparts. Specifically, MedGemma-27B achieves an F1 score of 0.820 and Cohen's Kappa of 0.677, representing clear improvements over its base model Gemma3-27B (F1 = 0.771, Kappa = 0.604). Notably, MedGemma-27B also surpasses OpenAI's GPT-4o (F1 = 0.708, Kappa = 0.561) and GPT-4.1 (F1 = 0.732, Kappa = 0.597), demonstrating the advantage of biomedical domain adaptation even over stronger proprietary models. Among all evaluated models, DeepSeek-V3 yields the best overall performance (F1 = 0.844, Kappa = 0.730). Using MedGemma-27B, we extracted 225,799 relation triplets across three relation types from three authoritative biomedical websites. Case studies further highlight both the strengths and persistent challenges of different LLM classes in biomedical relation extraction from semi-structured content.</p><p><strong>Conclusion: </strong>Our study demonstrates that LLMs can serve as effective engines for high-throughput biomedical relation extraction, with domain-adapted and parameter-efficient models offering practical advantages. The framework is scalable and broadly adaptable, enabling efficient extraction of diverse biomedical relations across heterogeneous semi-structured websites. Beyond technical performance, the ability to extract reliable biomedical relations at scale can directly benefit clinical applications, such as enriching biomedical knowledge graphs, supporting evidence-based guideline development, and ultimately assisting clinicians in accessing structured medical knowledge for decision-making.</p>\",\"PeriodicalId\":9340,\"journal\":{\"name\":\"BMC Medical Informatics and Decision Making\",\"volume\":\"25 1\",\"pages\":\"351\"},\"PeriodicalIF\":3.8000,\"publicationDate\":\"2025-09-29\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12482089/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"BMC Medical Informatics and Decision Making\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1186/s12911-025-03204-3\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"MEDICAL INFORMATICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMC Medical Informatics and Decision Making","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1186/s12911-025-03204-3","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
High-throughput biomedical relation extraction for semi-structured web articles empowered by large language models.
Background: We aim to develop a high-throughput biomedical relation extraction system tailored for semi-structured biomedical websites, leveraging the reading comprehension abilities and domain-specific medical knowledge of large language models (LLMs).
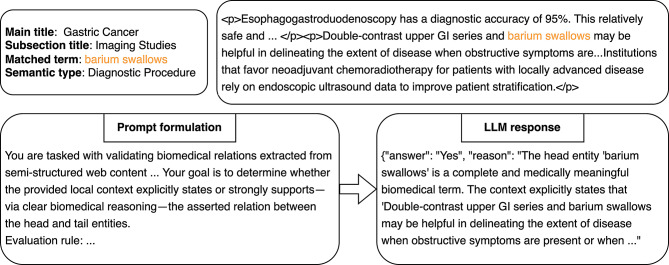
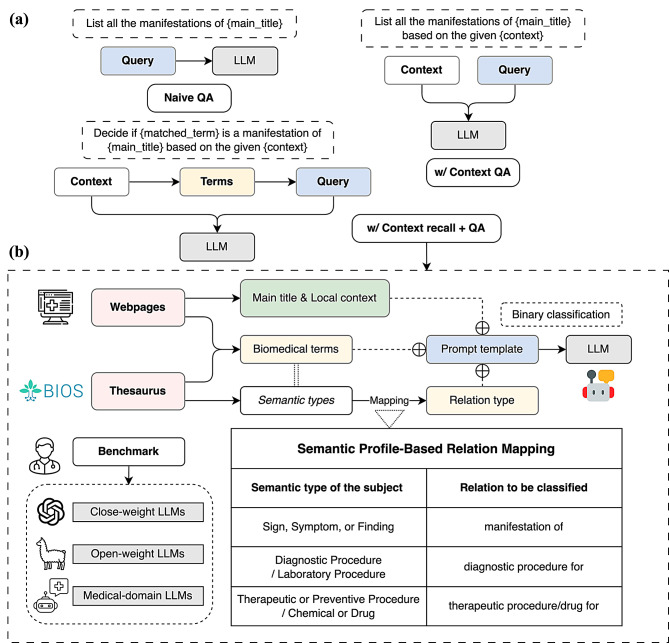
Methods: We formulate relation extraction as a series of binary classification problems. Given the context from semi-structured biomedical web articles, LLMs decide whether a relation holds while providing accompanying rationales for factual verification. The article's main title is designated as the tail entity, and candidate head entities are identified by matching against a biomedical thesaurus with semantic typing to guide candidate relation types. To assess system performance and robustness, we compare general-purpose, domain-adapted, and parameter-efficient LLMs on an expert-curated benchmark, evaluating their relative effectiveness in extracting relations from semi-structured biomedical websites.
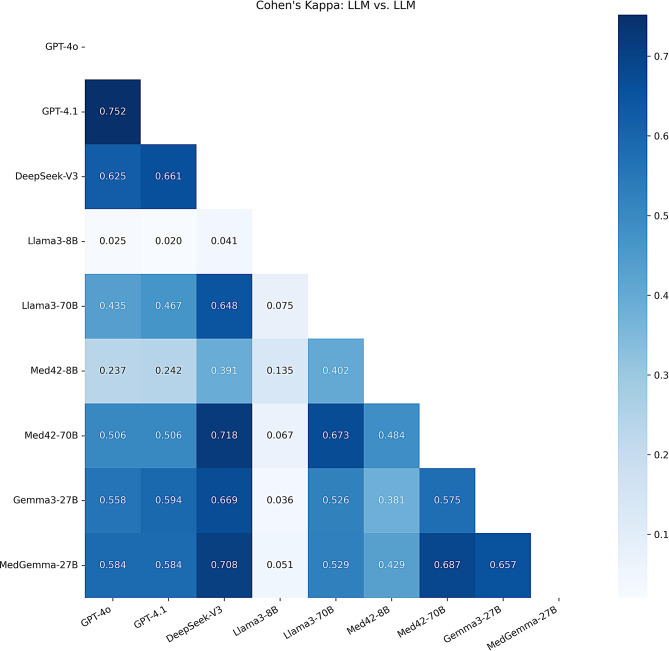
Results: Domain-adapted models consistently outperform their general-purpose counterparts. Specifically, MedGemma-27B achieves an F1 score of 0.820 and Cohen's Kappa of 0.677, representing clear improvements over its base model Gemma3-27B (F1 = 0.771, Kappa = 0.604). Notably, MedGemma-27B also surpasses OpenAI's GPT-4o (F1 = 0.708, Kappa = 0.561) and GPT-4.1 (F1 = 0.732, Kappa = 0.597), demonstrating the advantage of biomedical domain adaptation even over stronger proprietary models. Among all evaluated models, DeepSeek-V3 yields the best overall performance (F1 = 0.844, Kappa = 0.730). Using MedGemma-27B, we extracted 225,799 relation triplets across three relation types from three authoritative biomedical websites. Case studies further highlight both the strengths and persistent challenges of different LLM classes in biomedical relation extraction from semi-structured content.
Conclusion: Our study demonstrates that LLMs can serve as effective engines for high-throughput biomedical relation extraction, with domain-adapted and parameter-efficient models offering practical advantages. The framework is scalable and broadly adaptable, enabling efficient extraction of diverse biomedical relations across heterogeneous semi-structured websites. Beyond technical performance, the ability to extract reliable biomedical relations at scale can directly benefit clinical applications, such as enriching biomedical knowledge graphs, supporting evidence-based guideline development, and ultimately assisting clinicians in accessing structured medical knowledge for decision-making.
期刊介绍:
BMC Medical Informatics and Decision Making is an open access journal publishing original peer-reviewed research articles in relation to the design, development, implementation, use, and evaluation of health information technologies and decision-making for human health.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


