Barış Gün Sürmeli, René Staritzbichler, Clemens Ringel, Saleem Al-Dakkak, Helene Dörksen, Thorsten Kaiser
{"title":"全血细胞计数数据在基于机器学习的错血检测中的分析物重要性分析。","authors":"Barış Gün Sürmeli, René Staritzbichler, Clemens Ringel, Saleem Al-Dakkak, Helene Dörksen, Thorsten Kaiser","doi":"10.3390/jpm15090404","DOIUrl":null,"url":null,"abstract":"<p><p><b>Background</b>: Wrong blood in tube (WBIT) is a critical pre-analytical error in laboratory medicine in which a blood sample is mislabeled with the wrong patient identity. These errors are often undetected due to the limitations of current detection strategies (e.g., delta checks). <b>Methods</b>: We evaluated Random Forest models for WBIT detection and conducted a detailed analyte importance analysis. In total, 799,721 samples from a German tertiary care center were analyzed and filtered for applicability. Model input features were derived by pairing consecutive same-patient samples for non-WBIT cases, simulating WBIT by pairing samples from different patients, and computing per-analyte first-order differences for each pair. We exhaustively searched all subsets of nine CBC analytes and evaluated models using F1 score, AUC, sensitivity, and PPV. Analyte importance was assessed via SHAP, permutation, and impurity decrease. <b>Results</b>: Models using as few as three analytes (MCV, RDW, MCH) reached F1 scores above 90%, with performance plateauing beyond six analytes. MCV and RDW were consistently top-ranked. Two-dimensional and three-dimensional visualizations revealed interpretable decision boundaries. <b>Conclusions</b>: Findings demonstrate that robust WBIT detection is achievable using a minimal subset of CBC analytes, offering a practical, interpretable, and broadly generalizable ML-based solution suitable for diverse clinical environments.</p>","PeriodicalId":16722,"journal":{"name":"Journal of Personalized Medicine","volume":"15 9","pages":""},"PeriodicalIF":3.0000,"publicationDate":"2025-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12470999/pdf/","citationCount":"0","resultStr":"{\"title\":\"Analyte Importance Analysis in Machine Learning-Based Detection of Wrong-Blood-in-Tube Errors Using Complete Blood Count Data.\",\"authors\":\"Barış Gün Sürmeli, René Staritzbichler, Clemens Ringel, Saleem Al-Dakkak, Helene Dörksen, Thorsten Kaiser\",\"doi\":\"10.3390/jpm15090404\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p><b>Background</b>: Wrong blood in tube (WBIT) is a critical pre-analytical error in laboratory medicine in which a blood sample is mislabeled with the wrong patient identity. These errors are often undetected due to the limitations of current detection strategies (e.g., delta checks). <b>Methods</b>: We evaluated Random Forest models for WBIT detection and conducted a detailed analyte importance analysis. In total, 799,721 samples from a German tertiary care center were analyzed and filtered for applicability. Model input features were derived by pairing consecutive same-patient samples for non-WBIT cases, simulating WBIT by pairing samples from different patients, and computing per-analyte first-order differences for each pair. We exhaustively searched all subsets of nine CBC analytes and evaluated models using F1 score, AUC, sensitivity, and PPV. Analyte importance was assessed via SHAP, permutation, and impurity decrease. <b>Results</b>: Models using as few as three analytes (MCV, RDW, MCH) reached F1 scores above 90%, with performance plateauing beyond six analytes. MCV and RDW were consistently top-ranked. Two-dimensional and three-dimensional visualizations revealed interpretable decision boundaries. <b>Conclusions</b>: Findings demonstrate that robust WBIT detection is achievable using a minimal subset of CBC analytes, offering a practical, interpretable, and broadly generalizable ML-based solution suitable for diverse clinical environments.</p>\",\"PeriodicalId\":16722,\"journal\":{\"name\":\"Journal of Personalized Medicine\",\"volume\":\"15 9\",\"pages\":\"\"},\"PeriodicalIF\":3.0000,\"publicationDate\":\"2025-09-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12470999/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Personalized Medicine\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.3390/jpm15090404\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Personalized Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.3390/jpm15090404","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Analyte Importance Analysis in Machine Learning-Based Detection of Wrong-Blood-in-Tube Errors Using Complete Blood Count Data.
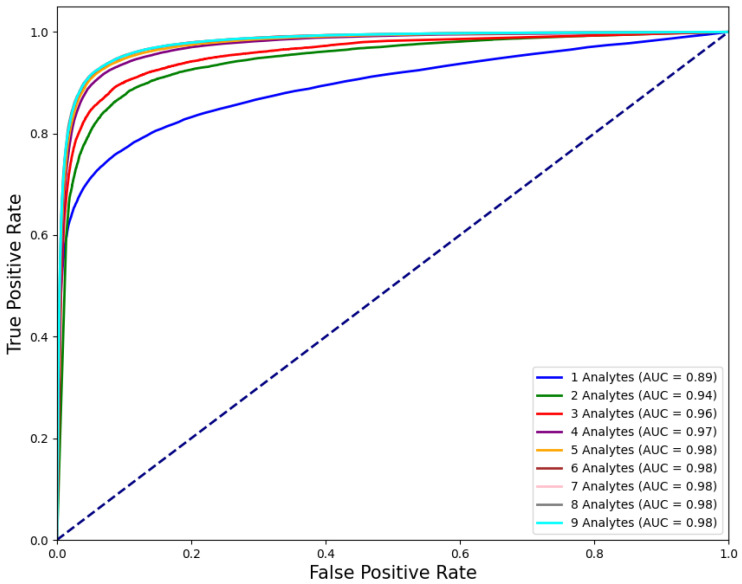
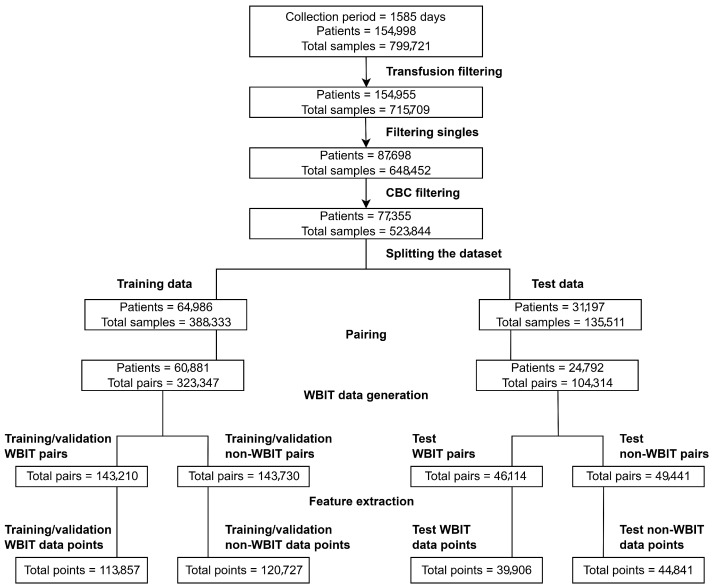
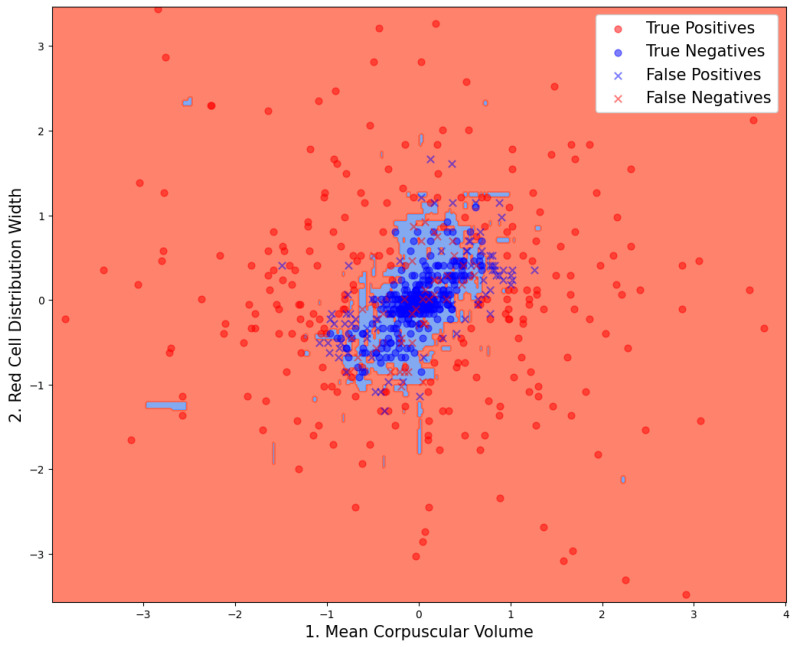
Background: Wrong blood in tube (WBIT) is a critical pre-analytical error in laboratory medicine in which a blood sample is mislabeled with the wrong patient identity. These errors are often undetected due to the limitations of current detection strategies (e.g., delta checks). Methods: We evaluated Random Forest models for WBIT detection and conducted a detailed analyte importance analysis. In total, 799,721 samples from a German tertiary care center were analyzed and filtered for applicability. Model input features were derived by pairing consecutive same-patient samples for non-WBIT cases, simulating WBIT by pairing samples from different patients, and computing per-analyte first-order differences for each pair. We exhaustively searched all subsets of nine CBC analytes and evaluated models using F1 score, AUC, sensitivity, and PPV. Analyte importance was assessed via SHAP, permutation, and impurity decrease. Results: Models using as few as three analytes (MCV, RDW, MCH) reached F1 scores above 90%, with performance plateauing beyond six analytes. MCV and RDW were consistently top-ranked. Two-dimensional and three-dimensional visualizations revealed interpretable decision boundaries. Conclusions: Findings demonstrate that robust WBIT detection is achievable using a minimal subset of CBC analytes, offering a practical, interpretable, and broadly generalizable ML-based solution suitable for diverse clinical environments.
期刊介绍:
Journal of Personalized Medicine (JPM; ISSN 2075-4426) is an international, open access journal aimed at bringing all aspects of personalized medicine to one platform. JPM publishes cutting edge, innovative preclinical and translational scientific research and technologies related to personalized medicine (e.g., pharmacogenomics/proteomics, systems biology). JPM recognizes that personalized medicine—the assessment of genetic, environmental and host factors that cause variability of individuals—is a challenging, transdisciplinary topic that requires discussions from a range of experts. For a comprehensive perspective of personalized medicine, JPM aims to integrate expertise from the molecular and translational sciences, therapeutics and diagnostics, as well as discussions of regulatory, social, ethical and policy aspects. We provide a forum to bring together academic and clinical researchers, biotechnology, diagnostic and pharmaceutical companies, health professionals, regulatory and ethical experts, and government and regulatory authorities.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


