EasyAnim: 3D面部动画从野外视频与定制的装备的化身
IF 2.2
4区 计算机科学
Q2 COMPUTER SCIENCE, SOFTWARE ENGINEERING
引用次数: 0
摘要
RGB视频驱动的数字人物三维面部动画有着广泛的应用。然而,由于各种身份和野外视频环境以及不同的索具设计,实际实施遇到了重大挑战。传统的工业管道需要一个劳动密集型的校准过程来确保兼容性,而最近的新方法受限于特定的索具标准,或者需要在演员视频上额外的劳动,这使得它们难以应用于定制的索具和野外视频。为了使任务变得简单和方便,我们介绍了EasyAnim,它利用丰富的2D视频来无监督地学习对齐的隐式运动流,并以广义的方式将其映射到各种索具参数。提出了一种具有自重构约束和交叉重构约束的框架,以保证角色域和人类角色域的一致性。大量的实验表明,EasyAnim在没有额外约束和人工的情况下产生了相当甚至更好的结果。本文章由计算机程序翻译,如有差异,请以英文原文为准。
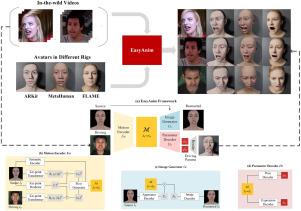
EasyAnim: 3D facial animation from in-the-wild videos for avatars with customized riggings
3D facial animation of digital avatars driven by RGB videos has extensive applications. However, the practical implementation encounters a significant challenge due to the various identities and environments of in-the-wild videos and varying rigging designs. The traditional industry pipeline necessitates a labor-intensive alignment process to ensure compatibility, while the recent novel methods are constrained to a specific rigging standard or require additional labor on actor videos, making them difficult to apply to customized riggings and in-the-wild videos. To make the task easy and convenient, we introduce EasyAnim, which utilizes abundant 2D videos to learn an aligned implicit motion flow unsupervisedly and maps it to various rigging parameters in a generalized manner. A novel framework with self- and cross- reconstruction constraints is proposed to ensure the alignment of avatar and human actor domains. Extensive experiments demonstrate that EasyAnim generates comparable or even better results with no additional constraints and labor.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Graphical Models
工程技术-计算机:软件工程
CiteScore
3.60
自引率
5.90%
发文量
15
审稿时长
47 days
期刊介绍:
Graphical Models is recognized internationally as a highly rated, top tier journal and is focused on the creation, geometric processing, animation, and visualization of graphical models and on their applications in engineering, science, culture, and entertainment. GMOD provides its readers with thoroughly reviewed and carefully selected papers that disseminate exciting innovations, that teach rigorous theoretical foundations, that propose robust and efficient solutions, or that describe ambitious systems or applications in a variety of topics.
We invite papers in five categories: research (contributions of novel theoretical or practical approaches or solutions), survey (opinionated views of the state-of-the-art and challenges in a specific topic), system (the architecture and implementation details of an innovative architecture for a complete system that supports model/animation design, acquisition, analysis, visualization?), application (description of a novel application of know techniques and evaluation of its impact), or lecture (an elegant and inspiring perspective on previously published results that clarifies them and teaches them in a new way).
GMOD offers its authors an accelerated review, feedback from experts in the field, immediate online publication of accepted papers, no restriction on color and length (when justified by the content) in the online version, and a broad promotion of published papers. A prestigious group of editors selected from among the premier international researchers in their fields oversees the review process.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


