Yanshan Wang, Jordan Hilsman, Chenyu Li, Michele Morris, Paul M Heider, Sunyang Fu, Min Ji Kwak, Andrew Wen, Joseph R Applegate, Liwei Wang, Elmer Bernstam, Hongfang Liu, Jack Chang, Daniel R Harris, Alexandria Corbeau, Darren Henderson, John Osborne, Richard E Kennedy, Nelly-Estefanie Garduno-Rapp, Justin F Rousseau, Chao Yan, You Chen, Mayur B Patel, Tyler J Murphy, Bradley A Malin, Chan Mi Park, Jungwei W Fan, Sunghwan Sohn, Sandeep Pagali, Yifan Peng, Aman Pathak, Yonghui Wu, Zongqi Xia, Salvatore Loguercio, Steven E Reis, Shyam Visweswaran
{"title":"国家ENACT网络中自然语言处理算法的开发与验证。","authors":"Yanshan Wang, Jordan Hilsman, Chenyu Li, Michele Morris, Paul M Heider, Sunyang Fu, Min Ji Kwak, Andrew Wen, Joseph R Applegate, Liwei Wang, Elmer Bernstam, Hongfang Liu, Jack Chang, Daniel R Harris, Alexandria Corbeau, Darren Henderson, John Osborne, Richard E Kennedy, Nelly-Estefanie Garduno-Rapp, Justin F Rousseau, Chao Yan, You Chen, Mayur B Patel, Tyler J Murphy, Bradley A Malin, Chan Mi Park, Jungwei W Fan, Sunghwan Sohn, Sandeep Pagali, Yifan Peng, Aman Pathak, Yonghui Wu, Zongqi Xia, Salvatore Loguercio, Steven E Reis, Shyam Visweswaran","doi":"10.1017/cts.2025.10116","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>Electronic Health Record (EHR) data are critical for advancing translational research and AI technologies. The ENACT network offers access to structured EHR data across 57 CTSA hubs. However, substantial information is contained in clinical narratives, requiring natural language processing (NLP) for research. The ENACT NLP Working Group was formed to make NLP-derived clinical information accessible and queryable across the network.</p><p><strong>Methods: </strong>We established the ENACT NLP Working Group with 13 sites selected based on criteria including clinical notes access, IT infrastructure, NLP expertise, and institutional support. We divided sites into five focus groups targeting clinical tasks within disease contexts. Each focus group consisted of two development sites and two validation sites. We extended the ENACT ontology to standardize NLP-derived data and conducted multisite evaluations using the Open Health Natural Language Processing (OHNLP) Toolkit.</p><p><strong>Results: </strong>The working group achieved 100% site retention and deployed NLP infrastructure across all sites. We developed and validated NLP algorithms for rare disease phenotyping, social determinants of health, opioid use disorder, sleep phenotyping, and delirium phenotyping. Performance varied across sites (F1 scores 0.53-0.96), highlighting data heterogeneity impacts. We extended the ENACT common data model and ontology to incorporate NLP-derived data while maintaining Shared Health Research Informatics NEtwork (SHRINE) compatibility.</p><p><strong>Conclusion: </strong>This demonstrates feasibility of deploying NLP infrastructure across large, federated networks. The focus group approach proved more practical than general-purpose approaches. Key lessons include the challenge of data heterogeneity and importance of collaborative governance. This work also provides a foundation that other networks can build on to implement NLP capabilities for translational research.</p>","PeriodicalId":15529,"journal":{"name":"Journal of Clinical and Translational Science","volume":"9 1","pages":"e199"},"PeriodicalIF":2.0000,"publicationDate":"2025-08-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12444719/pdf/","citationCount":"0","resultStr":"{\"title\":\"Development and validation of natural language processing algorithms in the national ENACT network.\",\"authors\":\"Yanshan Wang, Jordan Hilsman, Chenyu Li, Michele Morris, Paul M Heider, Sunyang Fu, Min Ji Kwak, Andrew Wen, Joseph R Applegate, Liwei Wang, Elmer Bernstam, Hongfang Liu, Jack Chang, Daniel R Harris, Alexandria Corbeau, Darren Henderson, John Osborne, Richard E Kennedy, Nelly-Estefanie Garduno-Rapp, Justin F Rousseau, Chao Yan, You Chen, Mayur B Patel, Tyler J Murphy, Bradley A Malin, Chan Mi Park, Jungwei W Fan, Sunghwan Sohn, Sandeep Pagali, Yifan Peng, Aman Pathak, Yonghui Wu, Zongqi Xia, Salvatore Loguercio, Steven E Reis, Shyam Visweswaran\",\"doi\":\"10.1017/cts.2025.10116\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objective: </strong>Electronic Health Record (EHR) data are critical for advancing translational research and AI technologies. The ENACT network offers access to structured EHR data across 57 CTSA hubs. However, substantial information is contained in clinical narratives, requiring natural language processing (NLP) for research. The ENACT NLP Working Group was formed to make NLP-derived clinical information accessible and queryable across the network.</p><p><strong>Methods: </strong>We established the ENACT NLP Working Group with 13 sites selected based on criteria including clinical notes access, IT infrastructure, NLP expertise, and institutional support. We divided sites into five focus groups targeting clinical tasks within disease contexts. Each focus group consisted of two development sites and two validation sites. We extended the ENACT ontology to standardize NLP-derived data and conducted multisite evaluations using the Open Health Natural Language Processing (OHNLP) Toolkit.</p><p><strong>Results: </strong>The working group achieved 100% site retention and deployed NLP infrastructure across all sites. We developed and validated NLP algorithms for rare disease phenotyping, social determinants of health, opioid use disorder, sleep phenotyping, and delirium phenotyping. Performance varied across sites (F1 scores 0.53-0.96), highlighting data heterogeneity impacts. We extended the ENACT common data model and ontology to incorporate NLP-derived data while maintaining Shared Health Research Informatics NEtwork (SHRINE) compatibility.</p><p><strong>Conclusion: </strong>This demonstrates feasibility of deploying NLP infrastructure across large, federated networks. The focus group approach proved more practical than general-purpose approaches. Key lessons include the challenge of data heterogeneity and importance of collaborative governance. This work also provides a foundation that other networks can build on to implement NLP capabilities for translational research.</p>\",\"PeriodicalId\":15529,\"journal\":{\"name\":\"Journal of Clinical and Translational Science\",\"volume\":\"9 1\",\"pages\":\"e199\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2025-08-22\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12444719/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Clinical and Translational Science\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1017/cts.2025.10116\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q3\",\"JCRName\":\"MEDICINE, RESEARCH & EXPERIMENTAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Clinical and Translational Science","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1017/cts.2025.10116","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"MEDICINE, RESEARCH & EXPERIMENTAL","Score":null,"Total":0}
Development and validation of natural language processing algorithms in the national ENACT network.
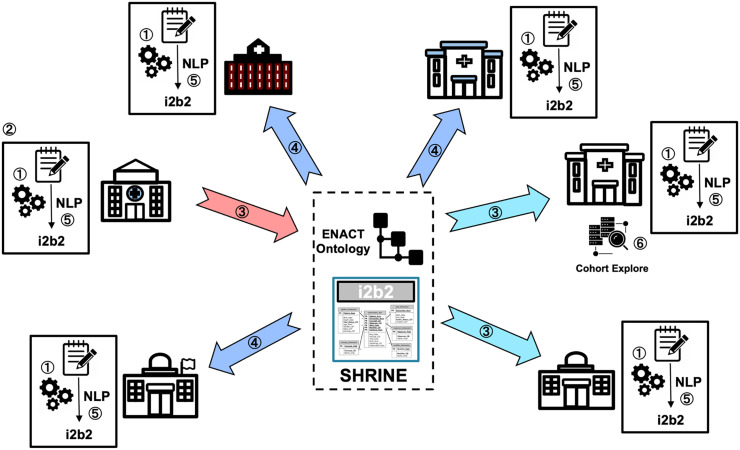
Objective: Electronic Health Record (EHR) data are critical for advancing translational research and AI technologies. The ENACT network offers access to structured EHR data across 57 CTSA hubs. However, substantial information is contained in clinical narratives, requiring natural language processing (NLP) for research. The ENACT NLP Working Group was formed to make NLP-derived clinical information accessible and queryable across the network.
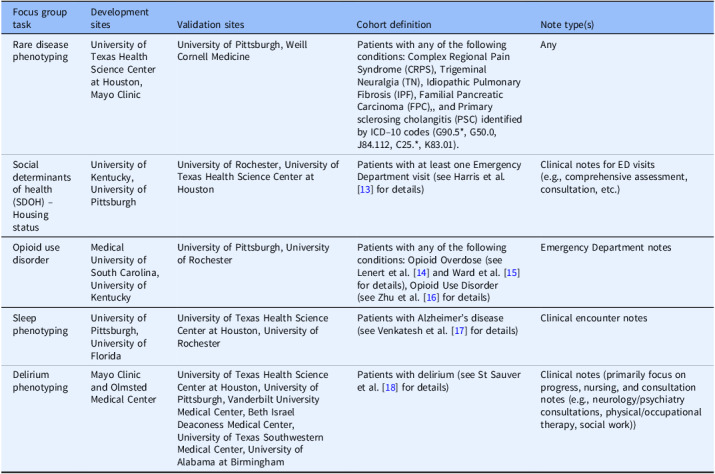
Methods: We established the ENACT NLP Working Group with 13 sites selected based on criteria including clinical notes access, IT infrastructure, NLP expertise, and institutional support. We divided sites into five focus groups targeting clinical tasks within disease contexts. Each focus group consisted of two development sites and two validation sites. We extended the ENACT ontology to standardize NLP-derived data and conducted multisite evaluations using the Open Health Natural Language Processing (OHNLP) Toolkit.
Results: The working group achieved 100% site retention and deployed NLP infrastructure across all sites. We developed and validated NLP algorithms for rare disease phenotyping, social determinants of health, opioid use disorder, sleep phenotyping, and delirium phenotyping. Performance varied across sites (F1 scores 0.53-0.96), highlighting data heterogeneity impacts. We extended the ENACT common data model and ontology to incorporate NLP-derived data while maintaining Shared Health Research Informatics NEtwork (SHRINE) compatibility.
Conclusion: This demonstrates feasibility of deploying NLP infrastructure across large, federated networks. The focus group approach proved more practical than general-purpose approaches. Key lessons include the challenge of data heterogeneity and importance of collaborative governance. This work also provides a foundation that other networks can build on to implement NLP capabilities for translational research.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


