Jie J Yao, Ryan D Lopez, Adam A Rizk, Manan Aggarwal, Surena Namdari
{"title":"骨科文献综述中流行的大语言模型的评价:与先前发表的综述的比较。","authors":"Jie J Yao, Ryan D Lopez, Adam A Rizk, Manan Aggarwal, Surena Namdari","doi":"10.22038/ABJS.2025.84896.3874","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>Large language models (LLMs) may improve the process of conducting systematic literature reviews. Our aim was to evaluate the utility of one popular LLM chatbot, Chat Generative Pre-trained Transformer (ChatGPT), in systematic literature reviews when compared to traditionally conducted reviews.</p><p><strong>Methods: </strong>We identified five systematic reviews published in the Journal of Bone and Joint Surgery from 2021 to 2022. We retrieved the clinical questions, methodologies, and included studies for each review. We evaluated ChatGPT's performance on three tasks. (1) For each published systematic review's core clinical question, ChatGPT designed a relevant database search strategy. (2) ChatGPT screened the abstracts of those articles identified by that search strategy for inclusion in a review. (3) For one systematic review, ChatGPT reviewed each individual manuscript identified after screening to identify those that fit inclusion criteria. We compared the performance of ChatGPT on each of these three tasks to the previously published systematic reviews.</p><p><strong>Results: </strong>ChatGPT captured a median of 91% (interquartile range, IQR 84%, 94%) of articles in the published systematic reviews. After screening of these abstracts, ChatGPT was able to capture a median of 75% (IQR 70%, 79%) of articles included in the published systematic reviews. On in-depth screening of manuscripts, ChatGPT captured only 55% of target publications; however, this improved to 100% on review of the manuscripts that ChatGPT identified on this step. Qualitative analysis of ChatGPT's performance highlighted the importance of prompt design and engineering.</p><p><strong>Conclusion: </strong>Using published reviews as a gold standard, ChatGPT demonstrated ability in replicating fundamental tasks for orthopedic systematic review. Cautious use and supervision of this general purpose LLM, ChatGPT, may aid in the process of systematic literature review. Further study and discussion regarding the role of LLMs in literature review is needed.</p>","PeriodicalId":46704,"journal":{"name":"Archives of Bone and Joint Surgery-ABJS","volume":"13 8","pages":"460-469"},"PeriodicalIF":1.8000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12432827/pdf/","citationCount":"0","resultStr":"{\"title\":\"Evaluation of a Popular Large Language Model in Orthopedic Literature Review: Comparison to Previously Published Reviews.\",\"authors\":\"Jie J Yao, Ryan D Lopez, Adam A Rizk, Manan Aggarwal, Surena Namdari\",\"doi\":\"10.22038/ABJS.2025.84896.3874\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objectives: </strong>Large language models (LLMs) may improve the process of conducting systematic literature reviews. Our aim was to evaluate the utility of one popular LLM chatbot, Chat Generative Pre-trained Transformer (ChatGPT), in systematic literature reviews when compared to traditionally conducted reviews.</p><p><strong>Methods: </strong>We identified five systematic reviews published in the Journal of Bone and Joint Surgery from 2021 to 2022. We retrieved the clinical questions, methodologies, and included studies for each review. We evaluated ChatGPT's performance on three tasks. (1) For each published systematic review's core clinical question, ChatGPT designed a relevant database search strategy. (2) ChatGPT screened the abstracts of those articles identified by that search strategy for inclusion in a review. (3) For one systematic review, ChatGPT reviewed each individual manuscript identified after screening to identify those that fit inclusion criteria. We compared the performance of ChatGPT on each of these three tasks to the previously published systematic reviews.</p><p><strong>Results: </strong>ChatGPT captured a median of 91% (interquartile range, IQR 84%, 94%) of articles in the published systematic reviews. After screening of these abstracts, ChatGPT was able to capture a median of 75% (IQR 70%, 79%) of articles included in the published systematic reviews. On in-depth screening of manuscripts, ChatGPT captured only 55% of target publications; however, this improved to 100% on review of the manuscripts that ChatGPT identified on this step. Qualitative analysis of ChatGPT's performance highlighted the importance of prompt design and engineering.</p><p><strong>Conclusion: </strong>Using published reviews as a gold standard, ChatGPT demonstrated ability in replicating fundamental tasks for orthopedic systematic review. Cautious use and supervision of this general purpose LLM, ChatGPT, may aid in the process of systematic literature review. Further study and discussion regarding the role of LLMs in literature review is needed.</p>\",\"PeriodicalId\":46704,\"journal\":{\"name\":\"Archives of Bone and Joint Surgery-ABJS\",\"volume\":\"13 8\",\"pages\":\"460-469\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2025-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12432827/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Archives of Bone and Joint Surgery-ABJS\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.22038/ABJS.2025.84896.3874\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"ORTHOPEDICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Archives of Bone and Joint Surgery-ABJS","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.22038/ABJS.2025.84896.3874","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"ORTHOPEDICS","Score":null,"Total":0}
Evaluation of a Popular Large Language Model in Orthopedic Literature Review: Comparison to Previously Published Reviews.
Objectives: Large language models (LLMs) may improve the process of conducting systematic literature reviews. Our aim was to evaluate the utility of one popular LLM chatbot, Chat Generative Pre-trained Transformer (ChatGPT), in systematic literature reviews when compared to traditionally conducted reviews.
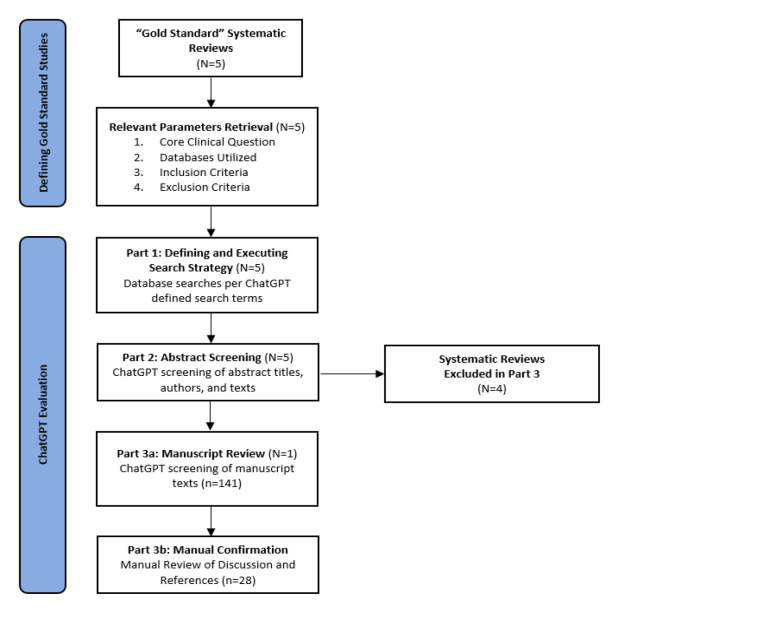
Methods: We identified five systematic reviews published in the Journal of Bone and Joint Surgery from 2021 to 2022. We retrieved the clinical questions, methodologies, and included studies for each review. We evaluated ChatGPT's performance on three tasks. (1) For each published systematic review's core clinical question, ChatGPT designed a relevant database search strategy. (2) ChatGPT screened the abstracts of those articles identified by that search strategy for inclusion in a review. (3) For one systematic review, ChatGPT reviewed each individual manuscript identified after screening to identify those that fit inclusion criteria. We compared the performance of ChatGPT on each of these three tasks to the previously published systematic reviews.
Results: ChatGPT captured a median of 91% (interquartile range, IQR 84%, 94%) of articles in the published systematic reviews. After screening of these abstracts, ChatGPT was able to capture a median of 75% (IQR 70%, 79%) of articles included in the published systematic reviews. On in-depth screening of manuscripts, ChatGPT captured only 55% of target publications; however, this improved to 100% on review of the manuscripts that ChatGPT identified on this step. Qualitative analysis of ChatGPT's performance highlighted the importance of prompt design and engineering.
Conclusion: Using published reviews as a gold standard, ChatGPT demonstrated ability in replicating fundamental tasks for orthopedic systematic review. Cautious use and supervision of this general purpose LLM, ChatGPT, may aid in the process of systematic literature review. Further study and discussion regarding the role of LLMs in literature review is needed.
期刊介绍:
The Archives of Bone and Joint Surgery (ABJS) aims to encourage a better understanding of all aspects of Orthopedic Sciences. The journal accepts scientific papers including original research, review article, short communication, case report, and letter to the editor in all fields of bone, joint, musculoskeletal surgery and related researches. The Archives of Bone and Joint Surgery (ABJS) will publish papers in all aspects of today`s modern orthopedic sciences including: Arthroscopy, Arthroplasty, Sport Medicine, Reconstruction, Hand and Upper Extremity, Pediatric Orthopedics, Spine, Trauma, Foot and Ankle, Tumor, Joint Rheumatic Disease, Skeletal Imaging, Orthopedic Physical Therapy, Rehabilitation, Orthopedic Basic Sciences (Biomechanics, Biotechnology, Biomaterial..).

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


