SHREC 2025:多模态增强语言和空间辅助(ROOMELSA)的最佳对象检索
IF 2.8
4区 计算机科学
Q2 COMPUTER SCIENCE, SOFTWARE ENGINEERING
引用次数: 0
摘要
最近的3D检索系统通常是为简单、可控的场景而设计的,例如从裁剪的图像或简短的描述中识别物体。然而,现实世界的场景更加复杂,通常需要基于模糊的、自由形式的描述来识别混乱场景中的物体。为此,我们提出了ROOMELSA,这是一个新的基准,旨在评估模型解释自然语言的能力。具体来说,ROOMELSA关注全景房间图像中的特定区域,并从大型数据库中准确检索相应的3D模型。此外,我们的ROOMELSA数据集包括1,600多个公寓场景,近5,200个房间和超过44,000个目标查询。根据经验,虽然粗对象检索在很大程度上得到了解决,但只有一个表现最好的模型在几乎所有测试用例中始终将正确匹配排在第一位。值得注意的是,一个轻量级的基于clip的模型也表现良好,尽管它在材料、部件结构和上下文线索的细微变化中挣扎,导致偶尔的错误。值得注意的是,这些发现强调了视觉和语言理解紧密结合的重要性。通过弥合场景级基础和细粒度3D检索之间的差距,ROOMELSA为推进强大的现实世界3D识别系统建立了新的基准。本文章由计算机程序翻译,如有差异,请以英文原文为准。
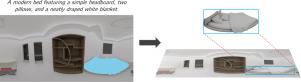
SHREC 2025: Retrieval of Optimal Objects for Multi-modal Enhanced Language and Spatial Assistance (ROOMELSA)
Recent 3D retrieval systems are typically designed for simple, controlled scenarios, such as identifying an object from a cropped image or a brief description. However, real-world scenarios are more complex, often requiring the recognition of an object in a cluttered scene based on a vague, free-form description. To this end, we present ROOMELSA, a new benchmark designed to evaluate a model’s ability to interpret natural language. Specifically, ROOMELSA attends to a specific region within a panoramic room image and accurately retrieves the corresponding 3D model from a large database. In addition, our ROOMELSA dataset includes over 1,600 apartment scenes, nearly 5,200 rooms, and more than 44,000 targeted queries. Empirically, while coarse object retrieval is largely solved, only one top-performing model consistently ranked the correct match first across nearly all test cases. Notably, a lightweight CLIP-based model also performed well, although it struggled with subtle variations in materials, part structures, and contextual cues, resulting in occasional errors. Notably, these findings highlight the importance of tightly integrating visual and language understanding. By bridging the gap between scene-level grounding and fine-grained 3D retrieval, ROOMELSA establishes a new benchmark for advancing robust, real-world 3D recognition systems.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Computers & Graphics-Uk
工程技术-计算机:软件工程
CiteScore
5.30
自引率
12.00%
发文量
173
审稿时长
38 days
期刊介绍:
Computers & Graphics is dedicated to disseminate information on research and applications of computer graphics (CG) techniques. The journal encourages articles on:
1. Research and applications of interactive computer graphics. We are particularly interested in novel interaction techniques and applications of CG to problem domains.
2. State-of-the-art papers on late-breaking, cutting-edge research on CG.
3. Information on innovative uses of graphics principles and technologies.
4. Tutorial papers on both teaching CG principles and innovative uses of CG in education.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


