Elizaveta Kopacheva, Aron Henriksson, Hercules Dalianis, Tora Hammar, Alisa Lincke
{"title":"使用微调临床语言模型识别临床文本中的不良药物事件:机器学习研究。","authors":"Elizaveta Kopacheva, Aron Henriksson, Hercules Dalianis, Tora Hammar, Alisa Lincke","doi":"10.2196/71949","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Medications are essential for health care but can cause adverse drug events (ADEs), which are harmful and sometimes fatal. Detecting ADEs is a challenging task because they are often not documented in the structured data of electronic health records (EHRs). There is a need for automatically extracting ADE-related information from clinical notes, as manual review is labor-intensive and time-consuming.</p><p><strong>Objective: </strong>This study aims to fine-tune the pretrained clinical language model, Swedish Deidentified Clinical Bidirectional Encoder Representations from Transformers (SweDeClin-BERT), for medical named entity recognition (NER) and relation extraction (RE) tasks, and to implement an integrated NER-RE approach to more effectively identify ADEs in clinical notes from clinical units in Sweden. The performance of this approach is compared with our previous machine learning method, which used conditional random fields (CRFs) and random forest (RF).</p><p><strong>Methods: </strong>A subset of clinical notes from the Stockholm EPR (Electronic Patient Record) Corpus, dated 2009-2010, containing suspected ADEs based on International Classification of Diseases, 10th Revision (ICD-10) codes in the A.1 and A.2 categories was randomly sampled. These notes were annotated by a physician with ADE-related entities and relations following the ADE annotation guidelines. We fine-tuned the SweDeClin-BERT model for the NER and RE tasks and implemented an integrated NER-RE pipeline to extract entities and relationships from clinical notes. The models were evaluated using 395 clinical notes from clinical units in Sweden. The NER-RE pipeline was then applied to classify the clinical notes as containing or not containing ADEs. In addition, we conducted an error analysis to better understand the model's behavior and to identify potential areas for improvement.</p><p><strong>Results: </strong>In total, 62% of notes contained an explicit description of an ADE, indicating that an ADE-related ICD-10 code alone does not ensure detailed event documentation. The fine-tuned SweDeClin-BERT model achieved an F1-score of 0.845 for NER and 0.81 for RE task, outperforming the baseline models (CRFs for NER and random forests for RE). In particular, the RE task showed a 53% improvement in macro-average F1-score compared to the baseline. The integrated NER-RE pipeline achieved an overall F1-score of 0.81.</p><p><strong>Conclusions: </strong>Using a domain-specific language model like SweDeClin-BERT for detecting ADEs in clinical notes demonstrates improved classification performance (0.77 in strict and 0.81 in relaxed mode) compared to conventional machine learning models like CRFs and RF. The proposed fine-tuned ADE model requires further refinement and evaluation on annotated clinical notes from another hospital to evaluate the model's generalizability. In addition, the annotation guidelines should be revised, as there is an overlap of words between the Finding and Disorder entity categories, which were not consistently distinguished by the annotators. Furthermore, future work should address the handling of compound words and split entities to better capture context in the Swedish language.</p>","PeriodicalId":14841,"journal":{"name":"JMIR Formative Research","volume":"9 ","pages":"e71949"},"PeriodicalIF":2.0000,"publicationDate":"2025-09-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12425423/pdf/","citationCount":"0","resultStr":"{\"title\":\"Identifying Adverse Drug Events in Clinical Text Using Fine-Tuned Clinical Language Models: Machine Learning Study.\",\"authors\":\"Elizaveta Kopacheva, Aron Henriksson, Hercules Dalianis, Tora Hammar, Alisa Lincke\",\"doi\":\"10.2196/71949\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Medications are essential for health care but can cause adverse drug events (ADEs), which are harmful and sometimes fatal. Detecting ADEs is a challenging task because they are often not documented in the structured data of electronic health records (EHRs). There is a need for automatically extracting ADE-related information from clinical notes, as manual review is labor-intensive and time-consuming.</p><p><strong>Objective: </strong>This study aims to fine-tune the pretrained clinical language model, Swedish Deidentified Clinical Bidirectional Encoder Representations from Transformers (SweDeClin-BERT), for medical named entity recognition (NER) and relation extraction (RE) tasks, and to implement an integrated NER-RE approach to more effectively identify ADEs in clinical notes from clinical units in Sweden. The performance of this approach is compared with our previous machine learning method, which used conditional random fields (CRFs) and random forest (RF).</p><p><strong>Methods: </strong>A subset of clinical notes from the Stockholm EPR (Electronic Patient Record) Corpus, dated 2009-2010, containing suspected ADEs based on International Classification of Diseases, 10th Revision (ICD-10) codes in the A.1 and A.2 categories was randomly sampled. These notes were annotated by a physician with ADE-related entities and relations following the ADE annotation guidelines. We fine-tuned the SweDeClin-BERT model for the NER and RE tasks and implemented an integrated NER-RE pipeline to extract entities and relationships from clinical notes. The models were evaluated using 395 clinical notes from clinical units in Sweden. The NER-RE pipeline was then applied to classify the clinical notes as containing or not containing ADEs. In addition, we conducted an error analysis to better understand the model's behavior and to identify potential areas for improvement.</p><p><strong>Results: </strong>In total, 62% of notes contained an explicit description of an ADE, indicating that an ADE-related ICD-10 code alone does not ensure detailed event documentation. The fine-tuned SweDeClin-BERT model achieved an F1-score of 0.845 for NER and 0.81 for RE task, outperforming the baseline models (CRFs for NER and random forests for RE). In particular, the RE task showed a 53% improvement in macro-average F1-score compared to the baseline. The integrated NER-RE pipeline achieved an overall F1-score of 0.81.</p><p><strong>Conclusions: </strong>Using a domain-specific language model like SweDeClin-BERT for detecting ADEs in clinical notes demonstrates improved classification performance (0.77 in strict and 0.81 in relaxed mode) compared to conventional machine learning models like CRFs and RF. The proposed fine-tuned ADE model requires further refinement and evaluation on annotated clinical notes from another hospital to evaluate the model's generalizability. In addition, the annotation guidelines should be revised, as there is an overlap of words between the Finding and Disorder entity categories, which were not consistently distinguished by the annotators. Furthermore, future work should address the handling of compound words and split entities to better capture context in the Swedish language.</p>\",\"PeriodicalId\":14841,\"journal\":{\"name\":\"JMIR Formative Research\",\"volume\":\"9 \",\"pages\":\"e71949\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2025-09-11\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12425423/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR Formative Research\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/71949\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Formative Research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/71949","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Identifying Adverse Drug Events in Clinical Text Using Fine-Tuned Clinical Language Models: Machine Learning Study.
Background: Medications are essential for health care but can cause adverse drug events (ADEs), which are harmful and sometimes fatal. Detecting ADEs is a challenging task because they are often not documented in the structured data of electronic health records (EHRs). There is a need for automatically extracting ADE-related information from clinical notes, as manual review is labor-intensive and time-consuming.
Objective: This study aims to fine-tune the pretrained clinical language model, Swedish Deidentified Clinical Bidirectional Encoder Representations from Transformers (SweDeClin-BERT), for medical named entity recognition (NER) and relation extraction (RE) tasks, and to implement an integrated NER-RE approach to more effectively identify ADEs in clinical notes from clinical units in Sweden. The performance of this approach is compared with our previous machine learning method, which used conditional random fields (CRFs) and random forest (RF).
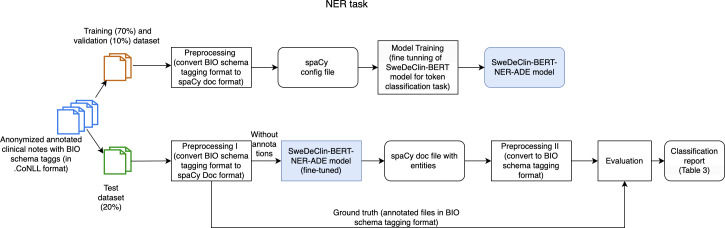
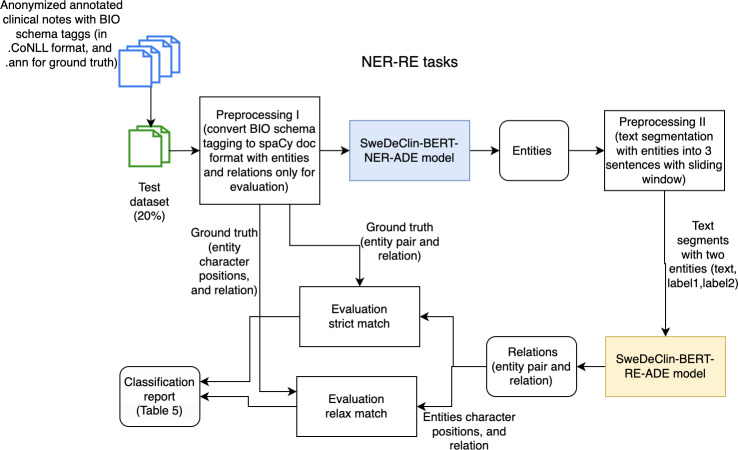
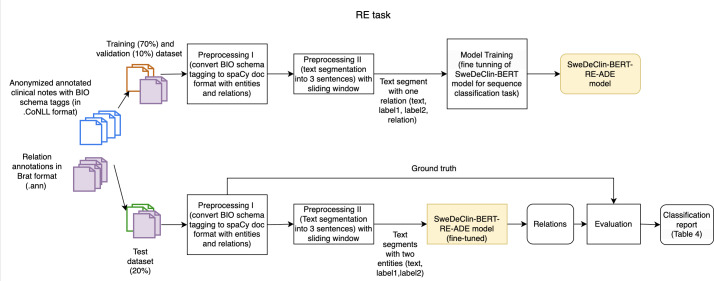
Methods: A subset of clinical notes from the Stockholm EPR (Electronic Patient Record) Corpus, dated 2009-2010, containing suspected ADEs based on International Classification of Diseases, 10th Revision (ICD-10) codes in the A.1 and A.2 categories was randomly sampled. These notes were annotated by a physician with ADE-related entities and relations following the ADE annotation guidelines. We fine-tuned the SweDeClin-BERT model for the NER and RE tasks and implemented an integrated NER-RE pipeline to extract entities and relationships from clinical notes. The models were evaluated using 395 clinical notes from clinical units in Sweden. The NER-RE pipeline was then applied to classify the clinical notes as containing or not containing ADEs. In addition, we conducted an error analysis to better understand the model's behavior and to identify potential areas for improvement.
Results: In total, 62% of notes contained an explicit description of an ADE, indicating that an ADE-related ICD-10 code alone does not ensure detailed event documentation. The fine-tuned SweDeClin-BERT model achieved an F1-score of 0.845 for NER and 0.81 for RE task, outperforming the baseline models (CRFs for NER and random forests for RE). In particular, the RE task showed a 53% improvement in macro-average F1-score compared to the baseline. The integrated NER-RE pipeline achieved an overall F1-score of 0.81.
Conclusions: Using a domain-specific language model like SweDeClin-BERT for detecting ADEs in clinical notes demonstrates improved classification performance (0.77 in strict and 0.81 in relaxed mode) compared to conventional machine learning models like CRFs and RF. The proposed fine-tuned ADE model requires further refinement and evaluation on annotated clinical notes from another hospital to evaluate the model's generalizability. In addition, the annotation guidelines should be revised, as there is an overlap of words between the Finding and Disorder entity categories, which were not consistently distinguished by the annotators. Furthermore, future work should address the handling of compound words and split entities to better capture context in the Swedish language.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


