Bruno Pellozo Cerqueira, Vinicius Cappellette da Silva Leite, Carla Gonzaga França, Fernando Sergio Leitão Filho, Sonia Maria Faresin, Ricardo Gassmann Figueiredo, Andrea Antunes Cetlin, Lilian Serrasqueiro Ballini Caetano, José Baddini-Martinez
{"title":"评价ChatGPT在回答哮喘相关问题中的准确性。","authors":"Bruno Pellozo Cerqueira, Vinicius Cappellette da Silva Leite, Carla Gonzaga França, Fernando Sergio Leitão Filho, Sonia Maria Faresin, Ricardo Gassmann Figueiredo, Andrea Antunes Cetlin, Lilian Serrasqueiro Ballini Caetano, José Baddini-Martinez","doi":"10.36416/1806-3756/e20240388","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>To evaluate the quality of ChatGPT answers to asthma-related questions, as assessed from the perspectives of asthma specialists and laypersons.</p><p><strong>Methods: </strong>Seven asthma-related questions were asked to ChatGPT (version 4) between May 3, 2024 and May 4, 2024. The questions were standardized with no memory of previous conversations to avoid bias. Six pulmonologists with extensive expertise in asthma acted as judges, independently assessing the quality and reproducibility of the answers from the perspectives of asthma specialists and laypersons. A Likert scale ranging from 1 to 4 was used, and the content validity coefficient was calculated to assess the level of agreement among the judges.</p><p><strong>Results: </strong>The evaluations showed variability in the quality of the answers provided by ChatGPT. From the perspective of asthma specialists, the scores ranged from 2 to 3, with greater divergence in questions 2, 3, and 5. From the perspective of laypersons, the content validity coefficient exceeded 0.80 for four of the seven questions, with most answers being correct despite a lack of significant depth.</p><p><strong>Conclusions: </strong>Although ChatGPT performed well in providing answers to laypersons, the answers that it provided to specialists were less accurate and superficial. Although AI has the potential to provide useful information to the public, it should not replace medical guidance. Critical analysis of AI-generated information remains essential for health care professionals and laypersons alike, especially for complex conditions such as asthma.</p>","PeriodicalId":14845,"journal":{"name":"Jornal Brasileiro De Pneumologia","volume":"51 3","pages":"e20240388"},"PeriodicalIF":3.0000,"publicationDate":"2025-09-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12401147/pdf/","citationCount":"0","resultStr":"{\"title\":\"Evaluation of the accuracy of ChatGPT in answering asthma-related questions.\",\"authors\":\"Bruno Pellozo Cerqueira, Vinicius Cappellette da Silva Leite, Carla Gonzaga França, Fernando Sergio Leitão Filho, Sonia Maria Faresin, Ricardo Gassmann Figueiredo, Andrea Antunes Cetlin, Lilian Serrasqueiro Ballini Caetano, José Baddini-Martinez\",\"doi\":\"10.36416/1806-3756/e20240388\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objective: </strong>To evaluate the quality of ChatGPT answers to asthma-related questions, as assessed from the perspectives of asthma specialists and laypersons.</p><p><strong>Methods: </strong>Seven asthma-related questions were asked to ChatGPT (version 4) between May 3, 2024 and May 4, 2024. The questions were standardized with no memory of previous conversations to avoid bias. Six pulmonologists with extensive expertise in asthma acted as judges, independently assessing the quality and reproducibility of the answers from the perspectives of asthma specialists and laypersons. A Likert scale ranging from 1 to 4 was used, and the content validity coefficient was calculated to assess the level of agreement among the judges.</p><p><strong>Results: </strong>The evaluations showed variability in the quality of the answers provided by ChatGPT. From the perspective of asthma specialists, the scores ranged from 2 to 3, with greater divergence in questions 2, 3, and 5. From the perspective of laypersons, the content validity coefficient exceeded 0.80 for four of the seven questions, with most answers being correct despite a lack of significant depth.</p><p><strong>Conclusions: </strong>Although ChatGPT performed well in providing answers to laypersons, the answers that it provided to specialists were less accurate and superficial. Although AI has the potential to provide useful information to the public, it should not replace medical guidance. Critical analysis of AI-generated information remains essential for health care professionals and laypersons alike, especially for complex conditions such as asthma.</p>\",\"PeriodicalId\":14845,\"journal\":{\"name\":\"Jornal Brasileiro De Pneumologia\",\"volume\":\"51 3\",\"pages\":\"e20240388\"},\"PeriodicalIF\":3.0000,\"publicationDate\":\"2025-09-08\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12401147/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Jornal Brasileiro De Pneumologia\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.36416/1806-3756/e20240388\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"RESPIRATORY SYSTEM\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Jornal Brasileiro De Pneumologia","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.36416/1806-3756/e20240388","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"RESPIRATORY SYSTEM","Score":null,"Total":0}
Evaluation of the accuracy of ChatGPT in answering asthma-related questions.
Objective: To evaluate the quality of ChatGPT answers to asthma-related questions, as assessed from the perspectives of asthma specialists and laypersons.
Methods: Seven asthma-related questions were asked to ChatGPT (version 4) between May 3, 2024 and May 4, 2024. The questions were standardized with no memory of previous conversations to avoid bias. Six pulmonologists with extensive expertise in asthma acted as judges, independently assessing the quality and reproducibility of the answers from the perspectives of asthma specialists and laypersons. A Likert scale ranging from 1 to 4 was used, and the content validity coefficient was calculated to assess the level of agreement among the judges.
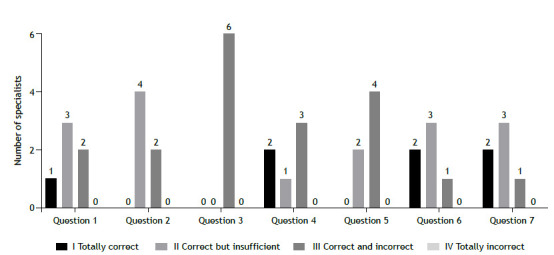
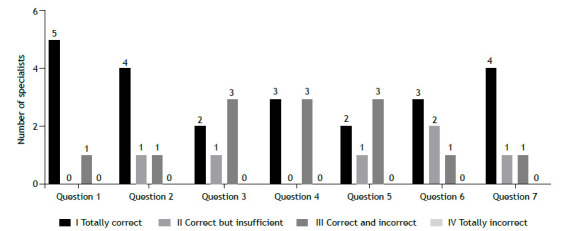
Results: The evaluations showed variability in the quality of the answers provided by ChatGPT. From the perspective of asthma specialists, the scores ranged from 2 to 3, with greater divergence in questions 2, 3, and 5. From the perspective of laypersons, the content validity coefficient exceeded 0.80 for four of the seven questions, with most answers being correct despite a lack of significant depth.
Conclusions: Although ChatGPT performed well in providing answers to laypersons, the answers that it provided to specialists were less accurate and superficial. Although AI has the potential to provide useful information to the public, it should not replace medical guidance. Critical analysis of AI-generated information remains essential for health care professionals and laypersons alike, especially for complex conditions such as asthma.
期刊介绍:
The Brazilian Journal of Pulmonology publishes scientific articles that contribute to the improvement of knowledge in the field of the lung diseases and related areas.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


